
In statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is

In mathematical physics and mathematics, the Pauli matrices are a set of three 2 × 2 complex matrices that are Hermitian, involutory and unitary. Usually indicated by the Greek letter sigma, they are occasionally denoted by tau when used in connection with isospin symmetries.
In quantum field theory, the Dirac spinor is the spinor that describes all known fundamental particles that are fermions, with the possible exception of neutrinos. It appears in the plane-wave solution to the Dirac equation, and is a certain combination of two Weyl spinors, specifically, a bispinor that transforms "spinorially" under the action of the Lorentz group.

In mathematics, Jensen's inequality, named after the Danish mathematician Johan Jensen, relates the value of a convex function of an integral to the integral of the convex function. It was proved by Jensen in 1906, building on an earlier proof of the same inequality for doubly-differentiable functions by Otto Hölder in 1889. Given its generality, the inequality appears in many forms depending on the context, some of which are presented below. In its simplest form the inequality states that the convex transformation of a mean is less than or equal to the mean applied after convex transformation; it is a simple corollary that the opposite is true of concave transformations.

In physics, the Rabi cycle is the cyclic behaviour of a two-level quantum system in the presence of an oscillatory driving field. A great variety of physical processes belonging to the areas of quantum computing, condensed matter, atomic and molecular physics, and nuclear and particle physics can be conveniently studied in terms of two-level quantum mechanical systems, and exhibit Rabi flopping when coupled to an optical driving field. The effect is important in quantum optics, magnetic resonance and quantum computing, and is named after Isidor Isaac Rabi.
In physics and astronomy, the Reissner–Nordström metric is a static solution to the Einstein–Maxwell field equations, which corresponds to the gravitational field of a charged, non-rotating, spherically symmetric body of mass M. The analogous solution for a charged, rotating body is given by the Kerr–Newman metric.
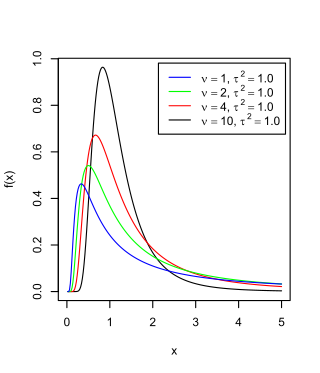
The scaled inverse chi-squared distribution is the distribution for x = 1/s2, where s2 is a sample mean of the squares of ν independent normal random variables that have mean 0 and inverse variance 1/σ2 = τ2. The distribution is therefore parametrised by the two quantities ν and τ2, referred to as the number of chi-squared degrees of freedom and the scaling parameter, respectively.
In theoretical physics, the Wess–Zumino model has become the first known example of an interacting four-dimensional quantum field theory with linearly realised supersymmetry. In 1974, Julius Wess and Bruno Zumino studied, using modern terminology, dynamics of a single chiral superfield whose cubic superpotential leads to a renormalizable theory.
Bayesian linear regression is a type of conditional modeling in which the mean of one variable is described by a linear combination of other variables, with the goal of obtaining the posterior probability of the regression coefficients and ultimately allowing the out-of-sample prediction of the regressandconditional on observed values of the regressors. The simplest and most widely used version of this model is the normal linear model, in which given is distributed Gaussian. In this model, and under a particular choice of prior probabilities for the parameters—so-called conjugate priors—the posterior can be found analytically. With more arbitrarily chosen priors, the posteriors generally have to be approximated.
In statistics, the bias of an estimator is the difference between this estimator's expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased. In statistics, "bias" is an objective property of an estimator. Bias is a distinct concept from consistency: consistent estimators converge in probability to the true value of the parameter, but may be biased or unbiased; see bias versus consistency for more.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
In mathematical physics, spacetime algebra (STA) is a name for the Clifford algebra Cl1,3(R), or equivalently the geometric algebra G(M4). According to David Hestenes, spacetime algebra can be particularly closely associated with the geometry of special relativity and relativistic spacetime.
In probability and statistics, the class of exponential dispersion models (EDM), also called exponential dispersion family (EDF), is a set of probability distributions that represents a generalisation of the natural exponential family. Exponential dispersion models play an important role in statistical theory, in particular in generalized linear models because they have a special structure which enables deductions to be made about appropriate statistical inference.

In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.

In general relativity, a point mass deflects a light ray with impact parameter by an angle approximately equal to

In the theory of stochastic processes, a part of the mathematical theory of probability, the variance gamma (VG) process, also known as Laplace motion, is a Lévy process determined by a random time change. The process has finite moments distinguishing it from many Lévy processes. There is no diffusion component in the VG process and it is thus a pure jump process. The increments are independent and follow a variance-gamma distribution, which is a generalization of the Laplace distribution.
In quantum field theory, a non-topological soliton (NTS) is a soliton field configuration possessing, contrary to a topological one, a conserved Noether charge and stable against transformation into usual particles of this field for the following reason. For fixed charge Q, the mass sum of Q free particles exceeds the energy (mass) of the NTS so that the latter is energetically favorable to exist.
Least-squares support-vector machines (LS-SVM) for statistics and in statistical modeling, are least-squares versions of support-vector machines (SVM), which are a set of related supervised learning methods that analyze data and recognize patterns, and which are used for classification and regression analysis. In this version one finds the solution by solving a set of linear equations instead of a convex quadratic programming (QP) problem for classical SVMs. Least-squares SVM classifiers were proposed by Johan Suykens and Joos Vandewalle. LS-SVMs are a class of kernel-based learning methods.
Pure inductive logic (PIL) is the area of mathematical logic concerned with the philosophical and mathematical foundations of probabilistic inductive reasoning. It combines classical predicate logic and probability theory. Probability values are assigned to sentences of a first-order relational language to represent degrees of belief that should be held by a rational agent. Conditional probability values represent degrees of belief based on the assumption of some received evidence.
In theoretical physics, more specifically in quantum field theory and supersymmetry, supersymmetric Yang–Mills, also known as super Yang–Mills and abbreviated to SYM, is a supersymmetric generalization of Yang–Mills theory, which is a gauge theory that plays an important part in the mathematical formulation of forces in particle physics.


















































