Related Research Articles
Natural language processing (NLP) is an interdisciplinary subfield of computer science and linguistics. It is primarily concerned with giving computers the ability to support and manipulate human language. It involves processing natural language datasets, such as text corpora or speech corpora, using either rule-based or probabilistic machine learning approaches. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.

A chatbot is a software application or web interface that is designed to mimic human conversation through text or voice interactions. Modern chatbots are typically online and use generative artificial intelligence systems that are capable of maintaining a conversation with a user in natural language and simulating the way a human would behave as a conversational partner. Such chatbots often use deep learning and natural language processing, but simpler chatbots have existed for decades.
Natural language generation (NLG) is a software process that produces natural language output. A widely-cited survey of NLG methods describes NLG as "the subfield of artificial intelligence and computational linguistics that is concerned with the construction of computer systems than can produce understandable texts in English or other human languages from some underlying non-linguistic representation of information".
In machine learning, a hyperparameter is a parameter, such as the learning rate or choice of optimizer, which specifies details of the learning process, hence the name hyperparameter. This is in contrast to parameters which determine the model itself.

Deep learning is the subset of machine learning methods based on artificial neural networks (ANNs) with representation learning. The adjective "deep" refers to the use of multiple layers in the network. Methods used can be either supervised, semi-supervised or unsupervised.
Google Brain was a deep learning artificial intelligence research team under the umbrella of Google AI, a research division at Google dedicated to artificial intelligence. Formed in 2011, Google Brain combined open-ended machine learning research with information systems and large-scale computing resources. The team has created tools such as TensorFlow, which allow for neural networks to be used by the public, with multiple internal AI research projects. The team aims to create research opportunities in machine learning and natural language processing. The team was merged into former Google sister company DeepMind to form Google DeepMind in April 2023.

DeepMind Technologies Limited, doing business as Google DeepMind, is a British-American artificial intelligence research laboratory which serves as a subsidiary of Google. Founded in the UK in 2010, it was acquired by Google in 2014, The company is based in London, with research centres in Canada, France, Germany and the United States.
This glossary of artificial intelligence is a list of definitions of terms and concepts relevant to the study of artificial intelligence, its sub-disciplines, and related fields. Related glossaries include Glossary of computer science, Glossary of robotics, and Glossary of machine vision.
In the field of artificial intelligence (AI), AI alignment research aims to steer AI systems towards humans' intended goals, preferences, or ethical principles. An AI system is considered aligned if it advances its intended objectives. A misaligned AI system pursues some objectives, but not the intended ones.
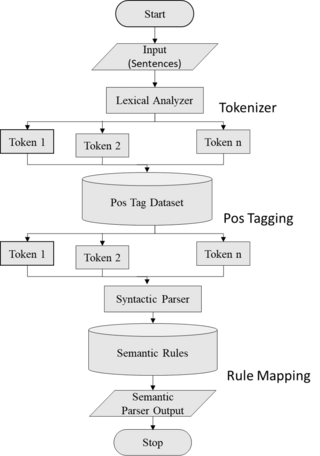
Semantic parsing is the task of converting a natural language utterance to a logical form: a machine-understandable representation of its meaning. Semantic parsing can thus be understood as extracting the precise meaning of an utterance. Applications of semantic parsing include machine translation, question answering, ontology induction, automated reasoning, and code generation. The phrase was first used in the 1970s by Yorick Wilks as the basis for machine translation programs working with only semantic representations. Semantic parsing is one of the important tasks in computational linguistics and natural language processing.

A transformer is a deep learning architecture based on the multi-head attention mechanism, proposed in a 2017 paper "Attention Is All You Need". It has no recurrent units, and thus requires less training time than previous recurrent neural architectures, such as long short-term memory (LSTM), and its later variation has been prevalently adopted for training large language models on large (language) datasets, such as the Wikipedia corpus and Common Crawl. Input text is split into n-grams encoded as tokens and each token is converted into a vector via looking up from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism allowing the signal for key tokens to be amplified and less important tokens to be diminished. The transformer paper, published in 2017, is based on the softmax-based attention mechanism was proposed by Bahdanau et. al. in 2014 for machine translation, and the Fast Weight Controller, similar to a transformer, was proposed in 1992.

Multi-agent reinforcement learning (MARL) is a sub-field of reinforcement learning. It focuses on studying the behavior of multiple learning agents that coexist in a shared environment. Each agent is motivated by its own rewards, and does actions to advance its own interests; in some environments these interests are opposed to the interests of other agents, resulting in complex group dynamics.
Generative Pre-trained Transformer 3 (GPT-3) is a large language model released by OpenAI in 2020. Like its predecessor, GPT-2, it is a decoder-only transformer model of deep neural network, which supersedes recurrence and convolution-based architectures with a technique known as "attention". This attention mechanism allows the model to selectively focus on segments of input text it predicts to be most relevant. It uses a 2048-tokens-long context, float16 (16-bit) precision, and a hitherto-unprecedented 175 billion parameters, requiring 350GB of storage space as each parameter takes 2 bytes of space, and has demonstrated strong "zero-shot" and "few-shot" learning abilities on many tasks.
Mona Talat Diab is a computer science professor and director of Carnegie Mellon University's Language Technologies Institute. Previously, she was a professor at George Washington University and a research scientist with Facebook AI. Her research focuses on natural language processing, computational linguistics, cross lingual/multilingual processing, computational socio-pragmatics, Arabic language processing, and applied machine learning.
Self-supervised learning (SSL) is a paradigm in machine learning where a model is trained on a task using the data itself to generate supervisory signals, rather than relying on external labels provided by humans. In the context of neural networks, self-supervised learning aims to leverage inherent structures or relationships within the input data to create meaningful training signals. SSL tasks are designed so that solving it requires capturing essential features or relationships in the data. The input data is typically augmented or transformed in a way that creates pairs of related samples. One sample serves as the input, and the other is used to formulate the supervisory signal. This augmentation can involve introducing noise, cropping, rotation, or other transformations. Self-supervised learning more closely imitates the way humans learn to classify objects.
Prompt engineering is the process of structuring text that can be interpreted and understood by a generative AI model. A prompt is natural language text describing the task that an AI should perform.
Meta AI is an artificial intelligence laboratory that belongs to Meta Platforms Inc. Meta AI intends to develop various forms of artificial intelligence, improving augmented and artificial reality technologies. Meta AI is an academic research laboratory focused on generating knowledge for the AI community. This is in contrast to Facebook's Applied Machine Learning (AML) team, which focuses on practical applications of its products.
In machine learning, reinforcement learning from human feedback (RLHF), including reinforcement learning from human preferences, is a technique that trains a "reward model" directly from human feedback and uses the model as a reward function to optimize an agent's policy using reinforcement learning (RL) through an optimization algorithm like Proximal Policy Optimization. The reward model is trained in advance to the policy being optimized to predict if a given output is good or bad. RLHF can improve the robustness and exploration of RL agents, especially when the reward function is sparse or noisy.
A large language model (LLM) is a language model notable for its ability to achieve general-purpose language generation and understanding. LLMs acquire these abilities by learning statistical relationships from text documents during a computationally intensive self-supervised and semi-supervised training process. LLMs are artificial neural networks, the largest and most capable of which are built with a transformer-based architecture. Some recent implementations are based on other architectures, such as recurrent neural network variants and Mamba.
Specification gaming or reward hacking occurs when an AI optimizes an objective function—achieving the literal, formal specification of an objective—without actually achieving an outcome that the programmers intended. DeepMind researchers have analogized it to the human behavior of finding a "shortcut" when being evaluated: "In the real world, when rewarded for doing well on a homework assignment, a student might copy another student to get the right answers, rather than learning the material—and thus exploit a loophole in the task specification."
References
- 1 2 "Chatbots learn how to negotiate and drive a hard bargain". New Scientist. 14 June 2017. Retrieved 24 January 2018.
- 1 2 3 4 Baraniuk, Chris (1 August 2017). "'Creepy Facebook AI' story sweeps media". BBC News. Retrieved 24 January 2018.
- ↑ "Facebook robots shut down after they talk to each other in language only they understand". The Independent. 31 July 2017. Retrieved 24 January 2018.
- 1 2 Field, Matthew (1 August 2017). "Facebook shuts down robots after they invent their own language". The Telegraph. Retrieved 24 January 2018.
- 1 2 LaFrance, Adrienne (20 June 2017). "What an AI's Non-Human Language Actually Looks Like". The Atlantic. Retrieved 24 January 2018.
- ↑ "It Begins: Bots Are Learning to Chat in Their Own Language". WIRED. 16 March 2017. Retrieved 24 January 2018.
- ↑ Mordatch, I., & Abbeel, P. (2017). Emergence of Grounded Compositional Language in Multi-Agent Populations. arXiv preprint arXiv:1703.04908.
- ↑ Das, A., Kottur, S., Moura, J. M., Lee, S., & Batra, D. (2017). Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning. arXiv preprint arXiv:1703.06585.
- ↑ Johnson, M., Schuster, M., Le, Q. V., Krikun, M., Wu, Y., Chen, Z., ... & Hughes, M. (2016). Google's multilingual neural machine translation system: enabling zero-shot translation. arXiv preprint arXiv:1611.04558.