Related Research Articles
Information retrieval (IR) in computing and information science is the process of obtaining information system resources that are relevant to an information need from a collection of those resources. Searches can be based on full-text or other content-based indexing. Information retrieval is the science of searching for information in a document, searching for documents themselves, and also searching for the metadata that describes data, and for databases of texts, images or sounds.
Accuracy and precision are two measures of observational error. Accuracy is how close a given set of measurements are to their true value, while precision is how close the measurements are to each other.
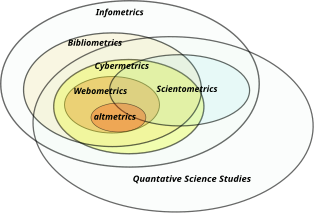
Information science is an academic field which is primarily concerned with analysis, collection, classification, manipulation, storage, retrieval, movement, dissemination, and protection of information. Practitioners within and outside the field study the application and the usage of knowledge in organizations in addition to the interaction between people, organizations, and any existing information systems with the aim of creating, replacing, improving, or understanding the information systems.
Westlaw is an online legal research service and proprietary database for lawyers and legal professionals available in over 60 countries. Information resources on Westlaw include more than 40,000 databases of case law, state and federal statutes, administrative codes, newspaper and magazine articles, public records, law journals, law reviews, treatises, legal forms and other information resources.
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text. A matrix containing word counts per document is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Documents are then compared by cosine similarity between any two columns. Values close to 1 represent very similar documents while values close to 0 represent very dissimilar documents.
Document retrieval is defined as the matching of some stated user query against a set of free-text records. These records could be any type of mainly unstructured text, such as newspaper articles, real estate records or paragraphs in a manual. User queries can range from multi-sentence full descriptions of an information need to a few words.
In text retrieval, full-text search refers to techniques for searching a single computer-stored document or a collection in a full-text database. Full-text search is distinguished from searches based on metadata or on parts of the original texts represented in databases.
Named-entity recognition (NER) (also known as (named)entity identification, entity chunking, and entity extraction) is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
Legal informatics is an area within information science.

The following outline is provided as an overview of and topical guide to library science:

In statistical analysis of binary classification, the F-score or F-measure is a measure of a test's accuracy. It is calculated from the precision and recall of the test, where the precision is the number of true positive results divided by the number of all positive results, including those not identified correctly, and the recall is the number of true positive results divided by the number of all samples that should have been identified as positive. Precision is also known as positive predictive value, and recall is also known as sensitivity in diagnostic binary classification.
Query expansion (QE) is the process of reformulating a given query to improve retrieval performance in information retrieval operations, particularly in the context of query understanding. In the context of search engines, query expansion involves evaluating a user's input and expanding the search query to match additional documents. Query expansion involves techniques such as:
A focused crawler is a web crawler that collects Web pages that satisfy some specific property, by carefully prioritizing the crawl frontier and managing the hyperlink exploration process. Some predicates may be based on simple, deterministic and surface properties. For example, a crawler's mission may be to crawl pages from only the .jp domain. Other predicates may be softer or comparative, e.g., "crawl pages about baseball", or "crawl pages with large PageRank". An important page property pertains to topics, leading to 'topical crawlers'. For example, a topical crawler may be deployed to collect pages about solar power, swine flu, or even more abstract concepts like controversy while minimizing resources spent fetching pages on other topics. Crawl frontier management may not be the only device used by focused crawlers; they may use a Web directory, a Web text index, backlinks, or any other Web artifact.
In pattern recognition, information retrieval, object detection and classification, precision and recall are performance metrics that apply to data retrieved from a collection, corpus or sample space.
Computer-assisted legal research (CALR) or computer-based legal research is a mode of legal research that uses databases of court opinions, statutes, court documents, and secondary material. Electronic databases make large bodies of case law easily available. Databases also have additional benefits, such as Boolean searches, evaluating case authority, organizing cases by topic, and providing links to cited material. Databases are available through paid subscription or for free.
A concept search is an automated information retrieval method that is used to search electronically stored unstructured text for information that is conceptually similar to the information provided in a search query. In other words, the ideas expressed in the information retrieved in response to a concept search query are relevant to the ideas contained in the text of the query.
Ranking of query is one of the fundamental problems in information retrieval (IR), the scientific/engineering discipline behind search engines. Given a query q and a collection D of documents that match the query, the problem is to rank, that is, sort, the documents in D according to some criterion so that the "best" results appear early in the result list displayed to the user. Ranking in terms of information retrieval is an important concept in computer science and is used in many different applications such as search engine queries and recommender systems. A majority of search engines use ranking algorithms to provide users with accurate and relevant results.
Fuzzy retrieval techniques are based on the Extended Boolean model and the Fuzzy set theory. There are two classical fuzzy retrieval models: Mixed Min and Max (MMM) and the Paice model. Both models do not provide a way of evaluating query weights, however this is considered by the P-norms algorithm.
Evaluation measures for an information retrieval (IR) system assess how well an index, search engine or database returns results from a collection of resources that satisfy a user's query. They are therefore fundamental to the success of information systems and digital platforms. The success of an IR system may be judged by a range of criteria including relevance, speed, user satisfaction, usability, efficiency and reliability. However, the most important factor in determining a system's effectiveness for users is the overall relevance of results retrieved in response to a query. Evaluation measures may be categorised in various ways including offline or online, user-based or system-based and include methods such as observed user behaviour, test collections, precision and recall, and scores from prepared benchmark test sets.
Query understanding is the process of inferring the intent of a search engine user by extracting semantic meaning from the searcher’s keywords. Query understanding methods generally take place before the search engine retrieves and ranks results. It is related to natural language processing but specifically focused on the understanding of search queries. Query understanding is at the heart of technologies like Amazon Alexa, Apple's Siri. Google Assistant, IBM's Watson, and Microsoft's Cortana.
References
- Maxwell, K.T.; Schafer, B. (2008). "Concept and Context in Legal Information Retrieval". Frontiers in Artificial Intelligence and Applications. 189: 63–72. Retrieved 2009-11-07.
- Jackson, P.; et al. (1998). "Information extraction from case law and retrieval of prior cases by partial parsing and query generation". Proceedings of the seventh international conference on Information and knowledge management. Cikm '98. ACM. pp. 60–67. doi:10.1145/288627.288642. ISBN 978-1581130614. S2CID 1268465 . Retrieved 2009-11-07.
- Blair, D.C.; Maron, M.E. (1985). "An evaluation of retrieval effectiveness for a full-text document-retrieval". Communications of the ACM. 28 (3): 289–299. doi:10.1145/3166.3197. hdl: 2027.42/35415 . S2CID 5144091.
- Peters, W.; et al. (2007). "The structuring of legal knowledge in LOIS". Artificial Intelligence and Law. 15 (2): 117–135. CiteSeerX 10.1.1.104.7469 . doi:10.1007/s10506-007-9034-4. S2CID 2355864.
- Saravanan, M.; et al. (2007). "Improving legal information retrieval using an ontological framework". Artificial Intelligence and Law. 17 (2): 101–124. doi:10.1007/s10506-009-9075-y. S2CID 8853001.
- Schweighofer, E.; Liebwald, D. (2007). "Advanced lexical ontologies and hybrid knowledge based systems: First steps to a dynamic legal electronic commentary". Artificial Intelligence and Law. 15 (2): 103–115. doi:10.1007/s10506-007-9029-1. S2CID 80124.
- Gelbart, D.; Smith, J.C. (1993). "Flexicon". Proceedings of the fourth international conference on Artificial intelligence and law - ICAIL '93. ACM. pp. 142–151. doi:10.1145/158976.158994. ISBN 978-0897916066. S2CID 18952317.
- Ashley, K.D.; Bruninghaus, S. (2009). "Automatically classifying case texts and predicting outcomes". Artificial Intelligence and Law. 17 (2): 125–165. doi:10.1007/s10506-009-9077-9. S2CID 31791294.