
In probability theory and statistics, the cumulative distribution function (CDF) of a real-valued random variable , or just distribution function of , evaluated at , is the probability that will take a value less than or equal to .

In information theory, the entropy of a random variable is the average level of "information", "surprise", or "uncertainty" inherent to the variable's possible outcomes. Given a discrete random variable , which takes values in the alphabet and is distributed according to :
In mathematics, the Laplace transform, named after its discoverer Pierre-Simon Laplace, is an integral transform that converts a function of a real variable to a function of a complex variable . The transform has many applications in science and engineering, mostly as a tool for solving linear differential equations. In particular, it transforms ordinary differential equations into algebraic equations and convolution into multiplication. For suitable functions f, the Laplace transform is defined by the integral
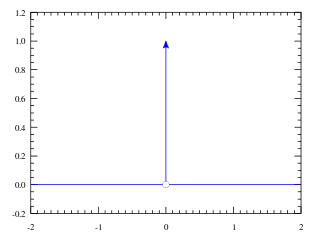
In mathematical analysis, the Dirac delta distribution, also known as the unit impulse, is a generalized function or distribution over the real numbers, whose value is zero everywhere except at zero, and whose integral over the entire real line is equal to one.

In probability theory, a probability density function (PDF), density function, or density of an absolutely continuous random variable, is a function whose value at any given sample in the sample space can be interpreted as providing a relative likelihood that the value of the random variable would be equal to that sample. Probability density is the probability per unit length, in other words, while the absolute likelihood for a continuous random variable to take on any particular value is 0, the value of the PDF at two different samples can be used to infer, in any particular draw of the random variable, how much more likely it is that the random variable would be close to one sample compared to the other sample.

The Heaviside step function, or the unit step function, usually denoted by H or θ, is a step function named after Oliver Heaviside, the value of which is zero for negative arguments and one for positive arguments. It is an example of the general class of step functions, all of which can be represented as linear combinations of translations of this one.
Rate–distortion theory is a major branch of information theory which provides the theoretical foundations for lossy data compression; it addresses the problem of determining the minimal number of bits per symbol, as measured by the rate R, that should be communicated over a channel, so that the source can be approximately reconstructed at the receiver without exceeding an expected distortion D.
The principle of maximum entropy states that the probability distribution which best represents the current state of knowledge about a system is the one with largest entropy, in the context of precisely stated prior data.
In information theory, the asymptotic equipartition property (AEP) is a general property of the output samples of a stochastic source. It is fundamental to the concept of typical set used in theories of data compression.
A prior probability distribution of an uncertain quantity, often simply called the prior, is its assumed probability distribution before some evidence is taken into account. For example, the prior could be the probability distribution representing the relative proportions of voters who will vote for a particular politician in a future election. The unknown quantity may be a parameter of the model or a latent variable rather than an observable variable.
In probability theory and statistics, the marginal distribution of a subset of a collection of random variables is the probability distribution of the variables contained in the subset. It gives the probabilities of various values of the variables in the subset without reference to the values of the other variables. This contrasts with a conditional distribution, which gives the probabilities contingent upon the values of the other variables.
In mathematical statistics, the Kullback–Leibler divergence, denoted , is a type of statistical distance: a measure of how one probability distribution P is different from a second, reference probability distribution Q. A simple interpretation of the KL divergence of P from Q is the expected excess surprise from using Q as a model when the actual distribution is P. While it is a measure of how different two distributions are, and in some sense is thus a "distance", it is not actually a metric, which is the most familiar and formal type of distance. In particular, it is not symmetric in the two distributions, and does not satisfy the triangle inequality. Instead, in terms of information geometry, it is a type of divergence, a generalization of squared distance, and for certain classes of distributions, it satisfies a generalized Pythagorean theorem.
In information theory, the Rényi entropy is a quantity that generalizes various notions of entropy, including Hartley entropy, Shannon entropy, collision entropy, and min-entropy. The Rényi entropy is named after Alfréd Rényi, who looked for the most general way to quantify information while preserving additivity for independent events. In the context of fractal dimension estimation, the Rényi entropy forms the basis of the concept of generalized dimensions.
In statistics and information theory, a maximum entropy probability distribution has entropy that is at least as great as that of all other members of a specified class of probability distributions. According to the principle of maximum entropy, if nothing is known about a distribution except that it belongs to a certain class, then the distribution with the largest entropy should be chosen as the least-informative default. The motivation is twofold: first, maximizing entropy minimizes the amount of prior information built into the distribution; second, many physical systems tend to move towards maximal entropy configurations over time.
Differential entropy is a concept in information theory that began as an attempt by Claude Shannon to extend the idea of (Shannon) entropy, a measure of average (surprisal) of a random variable, to continuous probability distributions. Unfortunately, Shannon did not derive this formula, and rather just assumed it was the correct continuous analogue of discrete entropy, but it is not. The actual continuous version of discrete entropy is the limiting density of discrete points (LDDP). Differential entropy is commonly encountered in the literature, but it is a limiting case of the LDDP, and one that loses its fundamental association with discrete entropy.
In information theory, information dimension is an information measure for random vectors in Euclidean space, based on the normalized entropy of finely quantized versions of the random vectors. This concept was first introduced by Alfréd Rényi in 1959.
This article discusses how information theory is related to measure theory.

The mathematical theory of information is based on probability theory and statistics, and measures information with several quantities of information. The choice of logarithmic base in the following formulae determines the unit of information entropy that is used. The most common unit of information is the bit, or more correctly the shannon, based on the binary logarithm. Although "bit" is more frequently used in place of "shannon", its name is not distinguished from the bit as used in data-processing to refer to a binary value or stream regardless of its entropy Other units include the nat, based on the natural logarithm, and the hartley, based on the base 10 or common logarithm.
In information theory, the entropy power inequality (EPI) is a result that relates to so-called "entropy power" of random variables. It shows that the entropy power of suitably well-behaved random variables is a superadditive function. The entropy power inequality was proved in 1948 by Claude Shannon in his seminal paper "A Mathematical Theory of Communication". Shannon also provided a sufficient condition for equality to hold; Stam (1959) showed that the condition is in fact necessary.
Inequalities are very important in the study of information theory. There are a number of different contexts in which these inequalities appear.


















