
In computing, a database is an organized collection of data or a type of data store based on the use of a database management system (DBMS), the software that interacts with end users, applications, and the database itself to capture and analyze the data. The DBMS additionally encompasses the core facilities provided to administer the database. The sum total of the database, the DBMS and the associated applications can be referred to as a database system. Often the term "database" is also used loosely to refer to any of the DBMS, the database system or an application associated with the database.
Natural language processing (NLP) is an interdisciplinary subfield of computer science and information retrieval. It is primarily concerned with giving computers the ability to support and manipulate human language. It involves processing natural language datasets, such as text corpora or speech corpora, using either rule-based or probabilistic machine learning approaches. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. To this end, natural language processing often borrows ideas from theoretical linguistics. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.
A relational database (RDB) is a database based on the relational model of data, as proposed by E. F. Codd in 1970. A database management system used to maintain relational databases is a relational database management system (RDBMS). Many relational database systems are equipped with the option of using SQL for querying and updating the database.
Data integrity is the maintenance of, and the assurance of, data accuracy and consistency over its entire life-cycle. It is a critical aspect to the design, implementation, and usage of any system that stores, processes, or retrieves data. The term is broad in scope and may have widely different meanings depending on the specific context even under the same general umbrella of computing. It is at times used as a proxy term for data quality, while data validation is a prerequisite for data integrity.
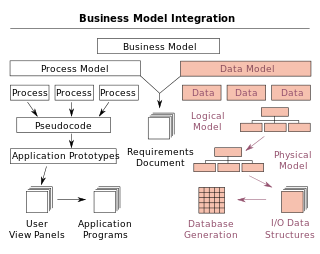
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. For instance, a data model may specify that the data element representing a car be composed of a number of other elements which, in turn, represent the color and size of the car and define its owner.
A surrogate key in a database is a unique identifier for either an entity in the modeled world or an object in the database. The surrogate key is not derived from application data, unlike a natural key.

An entity–relationship model describes interrelated things of interest in a specific domain of knowledge. A basic ER model is composed of entity types and specifies relationships that can exist between entities.
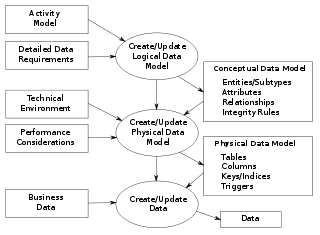
Data modeling in software engineering is the process of creating a data model for an information system by applying certain formal techniques. It may be applied as part of broader Model-driven engineering (MDE) concept.
Database design is the organization of data according to a database model. The designer determines what data must be stored and how the data elements interrelate. With this information, they can begin to fit the data to the database model. A database management system manages the data accordingly.
The term conceptual model refers to any model that is formed after a conceptualization or generalization process. Conceptual models are often abstractions of things in the real world, whether physical or social. Semantic studies are relevant to various stages of concept formation. Semantics is fundamentally a study of concepts, the meaning that thinking beings give to various elements of their experience.

Integration DEFinition for information modeling (IDEF1X) is a data modeling language for the development of semantic data models. IDEF1X is used to produce a graphical information model which represents the structure and semantics of information within an environment or system.
Within data modelling, cardinality is the numerical relationship between rows of one table and rows in another. Common cardinalities include one-to-one, one-to-many, and many-to-many. Cardinality can be used to define data models as well as analyze entities within datasets.
Frames are an artificial intelligence data structure used to divide knowledge into substructures by representing "stereotyped situations". They were proposed by Marvin Minsky in his 1974 article "A Framework for Representing Knowledge". Frames are the primary data structure used in artificial intelligence frame languages; they are stored as ontologies of sets.

A database model is a type of data model that determines the logical structure of a database. It fundamentally determines in which manner data can be stored, organized and manipulated. The most popular example of a database model is the relational model, which uses a table-based format.
Entity Framework (EF) is an open source object–relational mapping (ORM) framework for ADO.NET. It was originally shipped as an integral part of .NET Framework, however starting with Entity Framework version 6.0 it has been delivered separately from the .NET Framework.

ERIL is a visual language for representing the data structure of a computer system. As its name suggests, ERIL is based on entity-relationship diagrams and class diagrams. ERIL combines the relational and object-oriented approaches to data modeling.
This glossary of artificial intelligence is a list of definitions of terms and concepts relevant to the study of artificial intelligence, its sub-disciplines, and related fields. Related glossaries include Glossary of computer science, Glossary of robotics, and Glossary of machine vision.

Artificial intelligence in healthcare is a term used to describe the use of machine-learning algorithms and software, or artificial intelligence (AI), to copy human cognition in the analysis, presentation, and understanding of complex medical and health care data, or to exceed human capabilities by providing new ways to diagnose, treat, or prevent disease. Specifically, AI is the ability of computer algorithms to arrive at approximate conclusions based solely on input data.

Merative L.P., formerly IBM Watson Health, is an American medical technology company that provides products and services that help clients facilitate medical research, clinical research, real world evidence, and healthcare services, through the use of artificial intelligence, data analytics, cloud computing, and other advanced information technology. Merative is owned by Francisco Partners, an American private equity firm headquartered in San Francisco, California. In 2022, IBM divested and spun-off their Watson Health division into Merative. As of 2023, it remains a standalone company headquartered in Ann Arbor with innovation centers in Hyderabad, Bengaluru, and Chennai.

