Related Research Articles
In computational complexity theory, a branch of computer science, bounded-error probabilistic polynomial time (BPP) is the class of decision problems solvable by a probabilistic Turing machine in polynomial time with an error probability bounded by 1/3 for all instances. BPP is one of the largest practical classes of problems, meaning most problems of interest in BPP have efficient probabilistic algorithms that can be run quickly on real modern machines. BPP also contains P, the class of problems solvable in polynomial time with a deterministic machine, since a deterministic machine is a special case of a probabilistic machine.
The P versus NP problem is a major unsolved problem in theoretical computer science. In informal terms, it asks whether every problem whose solution can be quickly verified can also be quickly solved.
In computer science, the computational complexity or simply complexity of an algorithm is the amount of resources required to run it. Particular focus is given to computation time and memory storage requirements. The complexity of a problem is the complexity of the best algorithms that allow solving the problem.
Complexity characterises the behaviour of a system or model whose components interact in multiple ways and follow local rules, leading to non-linearity, randomness, collective dynamics, hierarchy, and emergence.
In theoretical computer science and mathematics, computational complexity theory focuses on classifying computational problems according to their resource usage, and relating these classes to each other. A computational problem is a task solved by a computer. A computation problem is solvable by mechanical application of mathematical steps, such as an algorithm.

In computability theory and computational complexity theory, a decision problem is a computational problem that can be posed as a yes–no question of the input values. An example of a decision problem is deciding by means of an algorithm whether a given natural number is prime. Another is the problem "given two numbers x and y, does x evenly divide y?". The answer is either 'yes' or 'no' depending upon the values of x and y. A method for solving a decision problem, given in the form of an algorithm, is called a decision procedure for that problem. A decision procedure for the decision problem "given two numbers x and y, does x evenly divide y?" would give the steps for determining whether x evenly divides y. One such algorithm is long division. If the remainder is zero the answer is 'yes', otherwise it is 'no'. A decision problem which can be solved by an algorithm is called decidable.

In computational complexity theory, NP is a complexity class used to classify decision problems. NP is the set of decision problems for which the problem instances, where the answer is "yes", have proofs verifiable in polynomial time by a deterministic Turing machine, or alternatively the set of problems that can be solved in polynomial time by a nondeterministic Turing machine.
In computational complexity theory, NP-hardness is the defining property of a class of problems that are informally "at least as hard as the hardest problems in NP". A simple example of an NP-hard problem is the subset sum problem.
In computational complexity theory, a polynomial-time reduction is a method for solving one problem using another. One shows that if a hypothetical subroutine solving the second problem exists, then the first problem can be solved by transforming or reducing it to inputs for the second problem and calling the subroutine one or more times. If both the time required to transform the first problem to the second, and the number of times the subroutine is called is polynomial, then the first problem is polynomial-time reducible to the second.
In theoretical computer science, a probabilistic Turing machine is a non-deterministic Turing machine that chooses between the available transitions at each point according to some probability distribution. As a consequence, a probabilistic Turing machine can—unlike a deterministic Turing Machine—have stochastic results; that is, on a given input and instruction state machine, it may have different run times, or it may not halt at all; furthermore, it may accept an input in one execution and reject the same input in another execution.

In theoretical computer science, the time complexity is the computational complexity that describes the amount of computer time it takes to run an algorithm. Time complexity is commonly estimated by counting the number of elementary operations performed by the algorithm, supposing that each elementary operation takes a fixed amount of time to perform. Thus, the amount of time taken and the number of elementary operations performed by the algorithm are taken to be related by a constant factor.

In computational complexity theory, a complexity class is a set of computational problems "of related resource-based complexity". The two most commonly analyzed resources are time and memory.
In computer science, parameterized complexity is a branch of computational complexity theory that focuses on classifying computational problems according to their inherent difficulty with respect to multiple parameters of the input or output. The complexity of a problem is then measured as a function of those parameters. This allows the classification of NP-hard problems on a finer scale than in the classical setting, where the complexity of a problem is only measured as a function of the number of bits in the input. This appears to have been first demonstrated in Gurevich, Stockmeyer & Vishkin (1984). The first systematic work on parameterized complexity was done by Downey & Fellows (1999).
In computational complexity theory, P, also known as PTIME or DTIME(nO(1)), is a fundamental complexity class. It contains all decision problems that can be solved by a deterministic Turing machine using a polynomial amount of computation time, or polynomial time.

In computational complexity theory, the complexity class PH is the union of all complexity classes in the polynomial hierarchy:
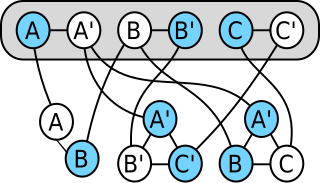
In computability theory and computational complexity theory, a reduction is an algorithm for transforming one problem into another problem. A sufficiently efficient reduction from one problem to another may be used to show that the second problem is at least as difficult as the first.
In computational complexity theory, NL is the complexity class containing decision problems that can be solved by a nondeterministic Turing machine using a logarithmic amount of memory space.

In computational complexity theory and circuit complexity, a Boolean circuit is a mathematical model for combinational digital logic circuits. A formal language can be decided by a family of Boolean circuits, one circuit for each possible input length.
In computational complexity theory, QMA, which stands for Quantum Merlin Arthur, is the set of languages for which, when a string is in the language, there is a polynomial-size quantum proof that convinces a polynomial time quantum verifier of this fact with high probability. Moreover, when the string is not in the language, every polynomial-size quantum state is rejected by the verifier with high probability.
Quantum complexity theory is the subfield of computational complexity theory that deals with complexity classes defined using quantum computers, a computational model based on quantum mechanics. It studies the hardness of computational problems in relation to these complexity classes, as well as the relationship between quantum complexity classes and classical complexity classes.
References
- ↑ Balcazar, Jose Luis; Diaz, Josep; Gabarro, Joaquim (1990). Structural Complexity II. Springer Verlag. ISBN 3-540-52079-1., Theorem 3.9