
In algorithmic information theory, the Kolmogorov complexity of an object, such as a piece of text, is the length of a shortest computer program that produces the object as output. It is a measure of the computational resources needed to specify the object, and is also known as algorithmic complexity, Solomonoff–Kolmogorov–Chaitin complexity, program-size complexity, descriptive complexity, or algorithmic entropy. It is named after Andrey Kolmogorov, who first published on the subject in 1963 and is a generalization of classical information theory.

In mathematics, two sequences of numbers, often experimental data, are proportional or directly proportional if their corresponding elements have a constant ratio. The ratio is called coefficient of proportionality and its reciprocal is known as constant of normalization. Two sequences are inversely proportional if corresponding elements have a constant product, also called the coefficient of proportionality.

In probability theory and information theory, the mutual information (MI) of two random variables is a measure of the mutual dependence between the two variables. More specifically, it quantifies the "amount of information" obtained about one random variable by observing the other random variable. The concept of mutual information is intimately linked to that of entropy of a random variable, a fundamental notion in information theory that quantifies the expected "amount of information" held in a random variable.

Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group are more similar to each other than to those in other groups (clusters). It is a main task of exploratory data analysis, and a common technique for statistical data analysis, used in many fields, including pattern recognition, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning.
The scale-invariant feature transform (SIFT) is a computer vision algorithm to detect, describe, and match local features in images, invented by David Lowe in 1999. Applications include object recognition, robotic mapping and navigation, image stitching, 3D modeling, gesture recognition, video tracking, individual identification of wildlife and match moving.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity. These are mathematical tools used to estimate the strength of the semantic relationship between units of language, concepts or instances, through a numerical description obtained according to the comparison of information supporting their meaning or describing their nature. The term semantic similarity is often confused with semantic relatedness. Semantic relatedness includes any relation between two terms, while semantic similarity only includes "is a" relations. For example, "car" is similar to "bus", but is also related to "road" and "driving".
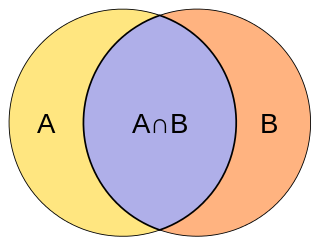
The Jaccard index, also known as the Jaccard similarity coefficient, is a statistic used for gauging the similarity and diversity of sample sets.
The structural similarityindex measure (SSIM) is a method for predicting the perceived quality of digital television and cinematic pictures, as well as other kinds of digital images and videos. It is also used for measuring the similarity between two images. The SSIM index is a full reference metric; in other words, the measurement or prediction of image quality is based on an initial uncompressed or distortion-free image as reference.
Nearest neighbor search (NNS), as a form of proximity search, is the optimization problem of finding the point in a given set that is closest to a given point. Closeness is typically expressed in terms of a dissimilarity function: the less similar the objects, the larger the function values.
In computer science, locality-sensitive hashing (LSH) is a fuzzy hashing technique that hashes similar input items into the same "buckets" with high probability. Since similar items end up in the same buckets, this technique can be used for data clustering and nearest neighbor search. It differs from conventional hashing techniques in that hash collisions are maximized, not minimized. Alternatively, the technique can be seen as a way to reduce the dimensionality of high-dimensional data; high-dimensional input items can be reduced to low-dimensional versions while preserving relative distances between items.
Shape context is a feature descriptor used in object recognition. Serge Belongie and Jitendra Malik proposed the term in their paper "Matching with Shape Contexts" in 2000.
In 1973, Andrey Kolmogorov proposed a non-probabilistic approach to statistics and model selection. Let each datum be a finite binary string and a model be a finite set of binary strings. Consider model classes consisting of models of given maximal Kolmogorov complexity. The Kolmogorov structure function of an individual data string expresses the relation between the complexity level constraint on a model class and the least log-cardinality of a model in the class containing the data. The structure function determines all stochastic properties of the individual data string: for every constrained model class it determines the individual best-fitting model in the class irrespective of whether the true model is in the model class considered or not. In the classical case we talk about a set of data with a probability distribution, and the properties are those of the expectations. In contrast, here we deal with individual data strings and the properties of the individual string focused on. In this setting, a property holds with certainty rather than with high probability as in the classical case. The Kolmogorov structure function precisely quantifies the goodness-of-fit of an individual model with respect to individual data.

PageRank (PR) is an algorithm used by Google Search to rank web pages in their search engine results. It is named after both the term "web page" and co-founder Larry Page. PageRank is a way of measuring the importance of website pages. According to Google:
PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites.
In computer science and data mining, MinHash is a technique for quickly estimating how similar two sets are. The scheme was invented by Andrei Broder, and initially used in the AltaVista search engine to detect duplicate web pages and eliminate them from search results. It has also been applied in large-scale clustering problems, such as clustering documents by the similarity of their sets of words.
Normalized compression distance (NCD) is a way of measuring the similarity between two objects, be it two documents, two letters, two emails, two music scores, two languages, two programs, two pictures, two systems, two genomes, to name a few. Such a measurement should not be application dependent or arbitrary. A reasonable definition for the similarity between two objects is how difficult it is to transform them into each other.
Similarity learning is an area of supervised machine learning in artificial intelligence. It is closely related to regression and classification, but the goal is to learn a similarity function that measures how similar or related two objects are. It has applications in ranking, in recommendation systems, visual identity tracking, face verification, and speaker verification.

t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map. It is based on Stochastic Neighbor Embedding originally developed by Geoffrey Hinton and Sam Roweis, where Laurens van der Maaten proposed the t-distributed variant. It is a nonlinear dimensionality reduction technique for embedding high-dimensional data for visualization in a low-dimensional space of two or three dimensions. Specifically, it models each high-dimensional object by a two- or three-dimensional point in such a way that similar objects are modeled by nearby points and dissimilar objects are modeled by distant points with high probability.
In bioinformatics, alignment-free sequence analysis approaches to molecular sequence and structure data provide alternatives over alignment-based approaches.
Information distance is the distance between two finite objects expressed as the number of bits in the shortest program which transforms one object into the other one or vice versa on a universal computer. This is an extension of Kolmogorov complexity. The Kolmogorov complexity of a single finite object is the information in that object; the information distance between a pair of finite objects is the minimum information required to go from one object to the other or vice versa. Information distance was first defined and investigated in based on thermodynamic principles, see also. Subsequently, it achieved final form in. It is applied in the normalized compression distance and the normalized Google distance.
In mathematics, the incompressibility method is a proof method like the probabilistic method, the counting method or the pigeonhole principle. To prove that an object in a certain class satisfies a certain property, select an object of that class that is incompressible. If it does not satisfy the property, it can be compressed by computable coding. Since it can be generally proven that almost all objects in a given class are incompressible, the argument demonstrates that almost all objects in the class have the property involved. To select an incompressible object is ineffective, and cannot be done by a computer program. However, a simple counting argument usually shows that almost all objects of a given class can be compressed by only a few bits.





