Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition (ASR), computer speech recognition or speech to text (STT). It incorporates knowledge and research in the computer science, linguistics and computer engineering fields. The reverse process is speech synthesis.

Optical character recognition or optical character reader (OCR) is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene photo or from subtitle text superimposed on an image.

Handwriting recognition (HWR), also known as handwritten text recognition (HTR), is the ability of a computer to receive and interpret intelligible handwritten input from sources such as paper documents, photographs, touch-screens and other devices. The image of the written text may be sensed "off line" from a piece of paper by optical scanning or intelligent word recognition. Alternatively, the movements of the pen tip may be sensed "on line", for example by a pen-based computer screen surface, a generally easier task as there are more clues available. A handwriting recognition system handles formatting, performs correct segmentation into characters, and finds the most possible words.
Optical music recognition (OMR) is a field of research that investigates how to computationally read musical notation in documents. The goal of OMR is to teach the computer to read and interpret sheet music and produce a machine-readable version of the written music score. Once captured digitally, the music can be saved in commonly used file formats, e.g. MIDI and MusicXML . In the past it has, misleadingly, also been called "music optical character recognition". Due to significant differences, this term should no longer be used.

Tesseract is an optical character recognition engine for various operating systems. It is free software, released under the Apache License. Originally developed by Hewlett-Packard as proprietary software in the 1980s, it was released as open source in 2005 and development was sponsored by Google in 2006.
Ocrad is an optical character recognition program and part of the GNU Project. It is free software licensed under the GNU GPL.
CuneiForm Cognitive OpenOCR is a freely distributed open-source OCR system developed by Russian software company Cognitive Technologies.

Etherpad is an open-source, web-based collaborative real-time editor, allowing authors to simultaneously edit a text document, and see all of the participants' edits in real-time, with the ability to display each author's text in their own color. There is also a chat box in the sidebar to allow meta communication.
hOCR is an open standard of data representation for formatted text obtained from optical character recognition (OCR). The definition encodes text, style, layout information, recognition confidence metrics and other information using Extensible Markup Language (XML) in the form of Hypertext Markup Language (HTML) or XHTML.
This comparison of optical character recognition software includes:

OpenSCAD is a free software application for creating solid 3D computer-aided design (CAD) objects. It is a script-only based modeller that uses its own description language; the 3D preview can be manipulated interactively, but cannot be interactively modified in 3D. Instead, an OpenSCAD script specifies geometric primitives and defines how they are modified and combined to render a 3D model. As such, the program performs constructive solid geometry (CSG). OpenSCAD is available for Windows, Linux, and macOS.
Xena is open-source software for use in digital preservation. Xena is short for XML Electronic Normalising for Archives.
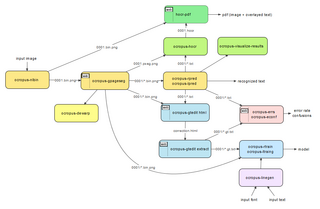
OCRFeeder is an optical character recognition suite for GNOME, which also supports virtually any command-line OCR engine, such as CuneiForm, GOCR, Ocrad and Tesseract. It converts paper documents to digital document files and can serve to make them accessible to visually impaired users.

spaCy is an open-source software library for advanced natural language processing, written in the programming languages Python and Cython. The library is published under the MIT license and its main developers are Matthew Honnibal and Ines Montani, the founders of the software company Explosion.
Indic OCR refers to the process of converting text images written in Indic scripts into e-text using Optical character recognition (OCR) techniques. Broadly, it can also refer to the OCR systems of Brahmic scripts for languages of South Asia and Southeast Asia, not just the scripts of the Indian subcontinent, which are all written in an abugida-based writing system.

Scene text is text that appears in an image captured by a camera in an outdoor environment.
Spark NLP is an open-source text processing library for advanced natural language processing for the Python, Java and Scala programming languages. The library is built on top of Apache Spark and its Spark ML library.
Page Analysis and Ground Truth Elements (PAGE) is an XML standard for encoding digitised documents. Comparable to ALTO (XML), it allows the organisation and structure of a page and its contents to be described.

eScriptorium is a platform for manual or automated segmentation and text recognition of historical manuscripts and prints.