The Semantic Web is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable. To enable the encoding of semantics with the data, technologies such as Resource Description Framework (RDF) and Web Ontology Language (OWL) are used. These technologies are used to formally represent metadata. For example, ontology can describe concepts, relationships between entities, and categories of things. These embedded semantics offer significant advantages such as reasoning over data and operating with heterogeneous data sources.
The Resource Description Framework (RDF) is a family of World Wide Web Consortium (W3C) specifications originally designed as a metadata data model. It has come to be used as a general method for conceptual description or modeling of information that is implemented in web resources, using a variety of syntax notations and data serialization formats. It is also used in knowledge management applications.
The Web Ontology Language (OWL) is a family of knowledge representation languages for authoring ontologies. Ontologies are a formal way to describe taxonomies and classification networks, essentially defining the structure of knowledge for various domains: the nouns representing classes of objects and the verbs representing relations between the objects. Ontologies resemble class hierarchies in object-oriented programming but there are several critical differences. Class hierarchies are meant to represent structures used in source code that evolve fairly slowly whereas ontologies are meant to represent information on the Internet and are expected to be evolving almost constantly. Similarly, ontologies are typically far more flexible as they are meant to represent information on the Internet coming from all sorts of heterogeneous data sources. Class hierarchies on the other hand are meant to be fairly static and rely on far less diverse and more structured sources of data such as corporate databases.
RDF Schema is a set of classes with certain properties using the RDF extensible knowledge representation data model, providing basic elements for the description of ontologies, otherwise called RDF vocabularies, intended to structure RDF resources. These resources can be saved in a triplestore to reach them with the query language SPARQL.

The Extensible Metadata Platform (XMP) is an ISO standard, originally created by Adobe Systems Inc., for the creation, processing and interchange of standardized and custom metadata for digital documents and data sets.
SPARQL is an RDF query language—that is, a semantic query language for databases—able to retrieve and manipulate data stored in Resource Description Framework (RDF) format. It was made a standard by the RDF Data Access Working Group (DAWG) of the World Wide Web Consortium, and is recognized as one of the key technologies of the semantic web. On 15 January 2008, SPARQL 1.0 was acknowledged by W3C as an official recommendation, and SPARQL 1.1 in March, 2013.

FOAF is a machine-readable ontology describing persons, their activities and their relations to other people and objects. Anyone can use FOAF to describe themselves. FOAF allows groups of people to describe social networks without the need for a centralised database.
Notation3, or N3 as it is more commonly known, is a shorthand non-XML serialization of Resource Description Framework models, designed with human-readability in mind: N3 is much more compact and readable than XML RDF notation. The format is being developed by Tim Berners-Lee and others from the Semantic Web community. A formalization of the logic underlying N3 was published by Berners-Lee and others in 2008.
RDFa is a W3C Recommendation that adds a set of attribute-level extensions to HTML, XHTML and various XML-based document types for embedding rich metadata within Web documents. The RDF data-model mapping enables its use for embedding RDF subject-predicate-object expressions within XHTML documents. It also enables the extraction of RDF model triples by compliant user agents.

RDFLib is a Python library for working with RDF, a simple yet powerful language for representing information. Through this library, Python is one of the main RDF manipulation languages, the other being Java. This library contains parsers/serializers for almost all of the known RDF serializations, such as RDF/XML, Turtle, N-Triples, & JSON-LD, many of which are now supported in their updated form. The library also contains both in-memory and persistent Graph back-ends for storing RDF information and numerous convenience functions for declaring graph namespaces, lodging SPARQL queries and so on. It is in continuous development with the most recent stable release, rdflib 5.0.0 having been released on 18 April, 2020. It was originally created by Daniel Krech with the first release in November, 2002.
Terse RDF Triple Language (Turtle) is a syntax and file format for expressing data in the Resource Description Framework (RDF) data model. Turtle syntax is similar to that of SPARQL, an RDF query language. It is a common data format for storing RDF data, along with N-Triples, JSON-LD and RDF/XML.
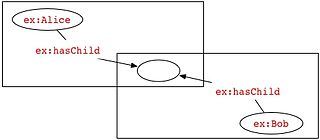
In RDF, a blank node is a node in an RDF graph representing a resource for which a URI or literal is not given. The resource represented by a blank node is also called an anonymous resource. According to the RDF standard a blank node can only be used as subject or object of an RDF triple.
The Rule Interchange Format (RIF) is a W3C Recommendation. RIF is part of the infrastructure for the semantic web, along with (principally) SPARQL, RDF and OWL. Although originally envisioned by many as a "rules layer" for the semantic web, in reality the design of RIF is based on the observation that there are many "rules languages" in existence, and what is needed is to exchange rules between them.
TriG is a serialization format for RDF graphs. It is a plain text format for serializing named graphs and RDF Datasets which offers a compact and readable alternative to the XML-based TriX syntax.

Named graphs are a key concept of Semantic Web architecture in which a set of Resource Description Framework statements are identified using a URI, allowing descriptions to be made of that set of statements such as context, provenance information or other such metadata.
XHTML+RDFa is an extended version of the XHTML markup language for supporting RDF through a collection of attributes and processing rules in the form of well-formed XML documents. XHTML+RDFa is one of the techniques used to develop Semantic Web content by embedding rich semantic markup. Version 1.1 of the language is a superset of XHTML 1.1, integrating the attributes according to RDFa Core 1.1. In other words, it is an RDFa support through XHTML Modularization.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criteria is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
JSON-LD is a method of encoding linked data using JSON. One goal for JSON-LD was to require as little effort as possible from developers to transform their existing JSON to JSON-LD. JSON-LD allows data to be serialized in a way that is similar to traditional JSON. It was initially developed by the JSON for Linking Data Community Group before being transferred to the RDF Working Group for review, improvement, and standardization. JSON-LD is a World Wide Web Consortium Recommendation.
gSOAP is a C and C++ software development toolkit for SOAP/XML web services and generic XML data bindings. Given a set of C/C++ type declarations, the compiler-based gSOAP tools generate serialization routines in source code for efficient XML serialization of the specified C and C++ data structures. Serialization takes zero-copy overhead.
Shape Expressions (ShEx) is a language for validating and describing RDF.
