This article needs attention from an expert in statistics. The specific problem is: the definition of paired is incorrect; reference is outside authors' area of expertise. See the talk page for details.WikiProject Statistics may be able to help recruit an expert.(April 2023)
Scientific experiments often require comparing two (or more) sets of data. In some cases, the data sets are paired, in that there is an obvious and meaningful one-to-one correspondence between the data in the first set and the data in the second set.
For example, paired data can arise from measuring a single set of individuals at different points in time.[1] A clinical trial might record the blood pressure in a set of n patients before and after giving them a medicine. In this case the "before" and "after" data sets are paired, in that each patient has a "before" measurement and an "after" measurement, which are probably related. In contrast, another clinical trial might measure n patients before treatment and a different set of m patients after treatment; in that case, the "before" and "after" data are unpaired.
Statistical tests used to compare sets of data have been designed for data sets that are either paired or unpaired, and it is important to use the correct test to prevent erroneous results. Tests for paired data include McNemar's test and the paired permutation test. Tests for unpaired data include Pearson's chi-squared test and Fisher's exact test.
In statistics, the power of a binary hypothesis test is the probability that the test correctly rejects the null hypothesis when a specific alternative hypothesis is true. It is commonly denoted by , and represents the chances of a true positive detection conditional on the actual existence of an effect to detect. Statistical power ranges from 0 to 1, and as the power of a test increases, the probability of making a type II error by wrongly failing to reject the null hypothesis decreases.
Clinical trials are prospective biomedical or behavioral research studies on human participants designed to answer specific questions about biomedical or behavioral interventions, including new treatments and known interventions that warrant further study and comparison. Clinical trials generate data on dosage, safety and efficacy. They are conducted only after they have received health authority/ethics committee approval in the country where approval of the therapy is sought. These authorities are responsible for vetting the risk/benefit ratio of the trial—their approval does not mean the therapy is 'safe' or effective, only that the trial may be conducted.
Rehabilitation of sensory and cognitive function typically involves methods for retraining neural pathways or training new neural pathways to regain or improve neurocognitive functioning that have been diminished by disease or trauma. The main objective outcome for rehabilitation is to assist in regaining physical abilities and improving performance. Three common neuropsychological problems treatable with rehabilitation are attention deficit/hyperactivity disorder (ADHD), concussion, and spinal cord injury. Rehabilitation research and practices are a fertile area for clinical neuropsychologists, rehabilitation psychologists, and others.
A t-test is a type of statistical analysis used to compare the averages of two groups and determine if the differences between them are more likely to arise from random chance. It is any statistical hypothesis test in which the test statistic follows a Student's t-distribution under the null hypothesis. It is most commonly applied when the test statistic would follow a normal distribution if the value of a scaling term in the test statistic were known. When the scaling term is estimated based on the data, the test statistic—under certain conditions—follows a Student's t distribution. The t-test's most common application is to test whether the means of two populations are different.
A scientific control is an experiment or observation designed to minimize the effects of variables other than the independent variable. This increases the reliability of the results, often through a comparison between control measurements and the other measurements. Scientific controls are a part of the scientific method.
In the design of experiments, hypotheses are applied to experimental units in a treatment group. In comparative experiments, members of a control group receive a standard treatment, a placebo, or no treatment at all. There may be more than one treatment group, more than one control group, or both.
Clinical endpoints or clinical outcomes are outcome measures referring to occurrence of disease, symptom, sign or laboratory abnormality constituting a target outcome in clinical research trials. The term may also refer to any disease or sign that strongly motivates withdrawal of an individual or entity from the trial, then often termed a humane (clinical) endpoint.
Clinical study design is the formulation of trials and experiments, as well as observational studies in medical, clinical and other types of research involving human beings. The goal of a clinical study is to assess the safety, efficacy, and / or the mechanism of action of an investigational medicinal product (IMP) or procedure, or new drug or device that is in development, but potentially not yet approved by a health authority. It can also be to investigate a drug, device or procedure that has already been approved but is still in need of further investigation, typically with respect to long-term effects or cost-effectiveness.
In statistics, McNemar's test is a statistical test used on paired nominal data. It is applied to 2 × 2 contingency tables with a dichotomous trait, with matched pairs of subjects, to determine whether the row and column marginal frequencies are equal. It is named after Quinn McNemar, who introduced it in 1947. An application of the test in genetics is the transmission disequilibrium test for detecting linkage disequilibrium.
In medicine, a crossover study or crossover trial is a longitudinal study in which subjects receive a sequence of different treatments. While crossover studies can be observational studies, many important crossover studies are controlled experiments, which are discussed in this article. Crossover designs are common for experiments in many scientific disciplines, for example psychology, pharmaceutical science, and medicine.
A patient-reported outcome (PRO) is a health outcome directly reported by the patient who experienced it. It stands in contrast to an outcome reported by someone else, such as a physician-reported outcome, a nurse-reported outcome, and so on. PRO methods, such as questionnaires, are used in clinical trials or other clinical settings, to help better understand a treatment's efficacy or effectiveness. The use of digitized PROs, or electronic patient-reported outcomes (ePROs), is on the rise in today's health research setting.
Repeated measures design is a research design that involves multiple measures of the same variable taken on the same or matched subjects either under different conditions or over two or more time periods. For instance, repeated measurements are collected in a longitudinal study in which change over time is assessed.
A glossary of terms used in clinical research.
Placebo-controlled studies are a way of testing a medical therapy in which, in addition to a group of subjects that receives the treatment to be evaluated, a separate control group receives a sham "placebo" treatment which is specifically designed to have no real effect. Placebos are most commonly used in blinded trials, where subjects do not know whether they are receiving real or placebo treatment. Often, there is also a further "natural history" group that does not receive any treatment at all.
In statistics, a paired difference test is a type of location test that is used when comparing two sets of paired measurements to assess whether their population means differ. A paired difference test uses additional information about the sample that is not present in an ordinary unpaired testing situation, either to increase the statistical power, or to reduce the effects of confounders.
Behavioral health outcome management (BHOM) involves the use of behavioral health outcome measurement data to help guide and inform the treatment of each individual patient. Like blood pressure, cholesterol and other routine lab work that helps to guide and inform general medical practice, the use of routine measurement in behavioral health is proving to be invaluable in assisting therapists to deliver better quality care.
The minimal important difference (MID) or minimal clinically important difference (MCID) is the smallest change in a treatment outcome that an individual patient would identify as important and which would indicate a change in the patient's management.
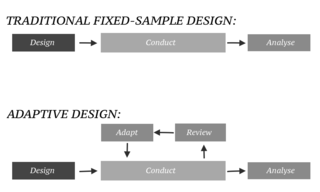
In an adaptive design of a clinical trial, the parameters and conduct of the trial for a candidate drug or vaccine may be changed based on an interim analysis. Adaptive design typically involves advanced statistics to interpret a clinical trial endpoint. This is in contrast to traditional single-arm clinical trials or randomized clinical trials (RCTs) that are static in their protocol and do not modify any parameters until the trial is completed. The adaptation process takes place at certain points in the trial, prescribed in the trial protocol. Importantly, this trial protocol is set before the trial begins with the adaptation schedule and processes specified. Adaptions may include modifications to: dosage, sample size, drug undergoing trial, patient selection criteria and/or "cocktail" mix. The PANDA provides not only a summary of different adaptive designs, but also comprehensive information on adaptive design planning, conduct, analysis and reporting.
A platform trial is a type of prospective, disease-focused, adaptive, randomized clinical trial (RCT) that compares multiple, simultaneous and possibly differently-timed interventions against a single, constant control group. As a disease-focused trial design, platform trials attempt to answer the question "which therapy will best treat this disease". Platform trials are unique in their utilization of both: a common control group and their opportunity to alter the therapies it investigates during its active enrollment phase. Platform trials commonly take advantage of Bayesian statistics, but may incorporate elements of frequentist statistics and/or machine learning.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.