Related Research Articles
Econometrics is the application of statistical methods to economic data in order to give empirical content to economic relationships. More precisely, it is "the quantitative analysis of actual economic phenomena based on the concurrent development of theory and observation, related by appropriate methods of inference". An introductory economics textbook describes econometrics as allowing economists "to sift through mountains of data to extract simple relationships". Jan Tinbergen is one of the two founding fathers of econometrics. The other, Ragnar Frisch, also coined the term in the sense in which it is used today.

Field experiments are experiments carried out outside of laboratory settings.
In statistics, econometrics, epidemiology and related disciplines, the method of instrumental variables (IV) is used to estimate causal relationships when controlled experiments are not feasible or when a treatment is not successfully delivered to every unit in a randomized experiment. Intuitively, IVs are used when an explanatory variable of interest is correlated with the error term, in which case ordinary least squares and ANOVA give biased results. A valid instrument induces changes in the explanatory variable but has no independent effect on the dependent variable, allowing a researcher to uncover the causal effect of the explanatory variable on the dependent variable.

In statistics, a confounder is a variable that influences both the dependent variable and independent variable, causing a spurious association. Confounding is a causal concept, and as such, cannot be described in terms of correlations or associations. The existence of confounders is an important quantitative explanation why correlation does not imply causation.
The Rubin causal model (RCM), also known as the Neyman–Rubin causal model, is an approach to the statistical analysis of cause and effect based on the framework of potential outcomes, named after Donald Rubin. The name "Rubin causal model" was first coined by Paul W. Holland. The potential outcomes framework was first proposed by Jerzy Neyman in his 1923 Master's thesis, though he discussed it only in the context of completely randomized experiments. Rubin extended it into a general framework for thinking about causation in both observational and experimental studies.
In statistics, ignorability is a feature of an experiment design whereby the method of data collection does not depend on the missing data. A missing data mechanism such as a treatment assignment or survey sampling strategy is "ignorable" if the missing data matrix, which indicates which variables are observed or missing, is independent of the missing data conditional on the observed data.

Joshua David Angrist is an Israeli-American economist and Ford Professor of Economics at the Massachusetts Institute of Technology. Angrist, together with Guido Imbens, was awarded the Nobel Memorial Prize in Economics in 2021 "for their methodological contributions to the analysis of causal relationships".
The average treatment effect (ATE) is a measure used to compare treatments in randomized experiments, evaluation of policy interventions, and medical trials. The ATE measures the difference in mean (average) outcomes between units assigned to the treatment and units assigned to the control. In a randomized trial, the average treatment effect can be estimated from a sample using a comparison in mean outcomes for treated and untreated units. However, the ATE is generally understood as a causal parameter that a researcher desires to know, defined without reference to the study design or estimation procedure. Both observational studies and experimental study designs with random assignment may enable one to estimate an ATE in a variety of ways.
In statistics, econometrics, political science, epidemiology, and related disciplines, a regression discontinuity design (RDD) is a quasi-experimental pretest-posttest design that aims to determine the causal effects of interventions by assigning a cutoff or threshold above or below which an intervention is assigned. By comparing observations lying closely on either side of the threshold, it is possible to estimate the average treatment effect in environments in which randomisation is unfeasible. However, it remains impossible to make true causal inference with this method alone, as it does not automatically reject causal effects by any potential confounding variable. First applied by Donald Thistlethwaite and Donald Campbell (1960) to the evaluation of scholarship programs, the RDD has become increasingly popular in recent years. Recent study comparisons of randomised controlled trials (RCTs) and RDDs have empirically demonstrated the internal validity of the design.
In the statistical analysis of observational data, propensity score matching (PSM) is a statistical matching technique that attempts to estimate the effect of a treatment, policy, or other intervention by accounting for the covariates that predict receiving the treatment. PSM attempts to reduce the bias due to confounding variables that could be found in an estimate of the treatment effect obtained from simply comparing outcomes among units that received the treatment versus those that did not. Paul R. Rosenbaum and Donald Rubin introduced the technique in 1983.
Matching is a statistical technique which is used to evaluate the effect of a treatment by comparing the treated and the non-treated units in an observational study or quasi-experiment. The goal of matching is to reduce bias for the estimated treatment effect in an observational-data study, by finding, for every treated unit, one non-treated unit(s) with similar observable characteristics against which the covariates are balanced out. By matching treated units to similar non-treated units, matching enables a comparison of outcomes among treated and non-treated units to estimate the effect of the treatment reducing bias due to confounding. Propensity score matching, an early matching technique, was developed as part of the Rubin causal model, but has been shown to increase model dependence, bias, inefficiency, and power and is no longer recommended compared to other matching methods.
In statistics, the Cochran–Mantel–Haenszel test (CMH) is a test used in the analysis of stratified or matched categorical data. It allows an investigator to test the association between a binary predictor or treatment and a binary outcome such as case or control status while taking into account the stratification. Unlike the McNemar test which can only handle pairs, the CMH test handles arbitrary strata size. It is named after William G. Cochran, Nathan Mantel and William Haenszel. Extensions of this test to a categorical response and/or to several groups are commonly called Cochran–Mantel–Haenszel statistics. It is often used in observational studies where random assignment of subjects to different treatments cannot be controlled, but confounding covariates can be measured.
Causal inference is the process of determining the independent, actual effect of a particular phenomenon that is a component of a larger system. The main difference between causal inference and inference of association is that causal inference analyzes the response of an effect variable when a cause of the effect variable is changed. The science of why things occur is called etiology. Causal inference is said to provide the evidence of causality theorized by causal reasoning.
In statistics, Lord's paradox raises the issue of when it is appropriate to control for baseline status. In three papers, Frederic M. Lord gave examples when statisticians could reach different conclusions depending on whether they adjust for pre-existing differences. Holland & Rubin (1983) use these examples to illustrate how there may be multiple valid descriptive comparisons in the data, but causal conclusions require an underlying (untestable) causal model.

Guido Wilhelmus Imbens is a Dutch-American economist whose research concerns econometrics and statistics. He holds the Applied Econometrics Professorship in Economics at the Stanford Graduate School of Business at Stanford University, where he has taught since 2012.
Control functions are statistical methods to correct for endogeneity problems by modelling the endogeneity in the error term. The approach thereby differs in important ways from other models that try to account for the same econometric problem. Instrumental variables, for example, attempt to model the endogenous variable X as an often invertible model with respect to a relevant and exogenous instrument Z. Panel analysis uses special data properties to difference out unobserved heterogeneity that is assumed to be fixed over time.
Experimental benchmarking allows researchers to learn about the accuracy of non-experimental research designs. Specifically, one can compare observational results to experimental findings to calibrate bias. Under ordinary conditions, carrying out an experiment gives the researchers an unbiased estimate of their parameter of interest. This estimate can then be compared to the findings of observational research. Note that benchmarking is an attempt to calibrate non-statistical uncertainty. When combined with meta-analysis this method can be used to understand the scope of bias associated with a specific area of research.
In econometrics and related fields, the local average treatment effect (LATE), also known as the complier average causal effect (CACE), is the effect of a treatment for subjects who comply with the treatment assigned to their sample group. It is not to be confused with the average treatment effect (ATE), which includes compliers and non-compliers together. The LATE is similar to the ATE, but excludes non-compliers. The LATE can be estimated by a ratio of the estimated intent-to-treat effect and the estimated proportion of compliers, or alternatively through an instrumental variable estimator.
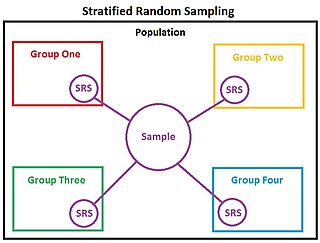
In statistics, stratified randomization is a method of sampling which first stratifies the whole study population into subgroups with same attributes or characteristics, known as strata, then followed by simple random sampling from the stratified groups, where each element within the same subgroup are selected unbiasedly during any stage of the sampling process, randomly and entirely by chance. Stratified randomization is considered a subdivision of stratified sampling, and should be adopted when shared attributes exist partially and vary widely between subgroups of the investigated population, so that they require special considerations or clear distinctions during sampling. This sampling method should be distinguished from cluster sampling, where a simple random sample of several entire clusters is selected to represent the whole population, or stratified systematic sampling, where a systematic sampling is carried out after the stratification process. Stratified random sampling is sometimes also known as "quota random sampling".
Differential effects play a special role in certain observational studies in which treatments are not assigned to subjects at random, where differing outcomes may reflect biased assignments rather than effects caused by the treatments.
References
- ↑ Imbens, Guido W.; Angrist, Joshua D. (March 1994). "Identification and Estimation of Local Average Treatment Effects". Econometrica. 62 (2): 467. doi:10.2307/2951620. ISSN 0012-9682.
- ↑ Baker, Stuart G.; Lindeman, Karen S. (1994-11-15). "The paired availability design: A proposal for evaluating epidural analgesia during labor". Statistics in Medicine. 13 (21): 2269–2278. doi:10.1002/sim.4780132108. ISSN 0277-6715.
- ↑ Baker, Stuart G.; Kramer, Barnett S.; Lindeman, Karen S. (2018-10-30). "Correction to "Latent class instrumental variables: A clinical and biostatistical perspective"". Statistics in Medicine. 38 (5): 901–901. doi:10.1002/sim.8035. ISSN 0277-6715.
- Frangakis, Constantine E.; Rubin, Donald B. (March 2002). "Principal stratification in causal inference". Biometrics. 58 (1): 21–9. doi:10.1111/j.0006-341X.2002.00021.x. PMC 4137767 . PMID 11890317. Preprint
- Zhang, Junni L.; Rubin, Donald B. (2003) "Estimation of Causal Effects via Principal Stratification When Some Outcomes are Truncated by "Death"", Journal of Educational and Behavioral Statistics, 28: 353–368 doi : 10.3102/10769986028004353
- Barnard, John; Frangakis, Constantine E.; Hill, Jennifer L.; Rubin, Donald B. (2003) "Principal Stratification Approach to Broken Randomized Experiments", Journal of the American Statistical Association , 98, 299–323 doi : 10.1198/016214503000071
- Roy, Jason; Hogan, Joseph W.; Marcus, Bess H. (2008) "Principal stratification with predictors of compliance for randomized trials with 2 active treatments", Biostatistics, 9 (2), 277–289. doi : 10.1093/biostatistics/kxm027
- Egleston, Brian L.; Cropsey, Karen L.; Lazev, Amy B.; Heckman, Carolyn J.; (2010) "A tutorial on principal stratification-based sensitivity analysis: application to smoking cessation studies", Clinical Trials, 7 (3), 286–298. doi : 10.1177/1740774510367811
- Peck, L. R.; (2013) "On estimating experimental impacts on endogenous subgroups: Part one of a methods note in three parts", American Journal of Evaluation, 34 (2), 225–236. doi : 10.1177/1098214013481666
| | This statistics-related article is a stub. You can help Wikipedia by expanding it. |