Bioinformatics is an interdisciplinary field of science that develops methods and software tools for understanding biological data, especially when the data sets are large and complex. Bioinformatics uses biology, chemistry, physics, computer science, computer programming, information engineering, mathematics and statistics to analyze and interpret biological data. The subsequent process of analyzing and interpreting data is referred to as computational biology.

In bioinformatics, a sequence alignment is a way of arranging the sequences of DNA, RNA, or protein to identify regions of similarity that may be a consequence of functional, structural, or evolutionary relationships between the sequences. Aligned sequences of nucleotide or amino acid residues are typically represented as rows within a matrix. Gaps are inserted between the residues so that identical or similar characters are aligned in successive columns. Sequence alignments are also used for non-biological sequences such as calculating the distance cost between strings in a natural language, or to display financial data.

Structural genomics seeks to describe the 3-dimensional structure of every protein encoded by a given genome. This genome-based approach allows for a high-throughput method of structure determination by a combination of experimental and modeling approaches. The principal difference between structural genomics and traditional structural prediction is that structural genomics attempts to determine the structure of every protein encoded by the genome, rather than focusing on one particular protein. With full-genome sequences available, structure prediction can be done more quickly through a combination of experimental and modeling approaches, especially because the availability of large number of sequenced genomes and previously solved protein structures allows scientists to model protein structure on the structures of previously solved homologs.

Protein structure prediction is the inference of the three-dimensional structure of a protein from its amino acid sequence—that is, the prediction of its secondary and tertiary structure from primary structure. Structure prediction is different from the inverse problem of protein design. Protein structure prediction is one of the most important goals pursued by computational biology; it is important in medicine and biotechnology.
In a chain-like biological molecule, such as a protein or nucleic acid, a structural motif is a common three-dimensional structure that appears in a variety of different, evolutionarily unrelated molecules. A structural motif does not have to be associated with a sequence motif; it can be represented by different and completely unrelated sequences in different proteins or RNA.

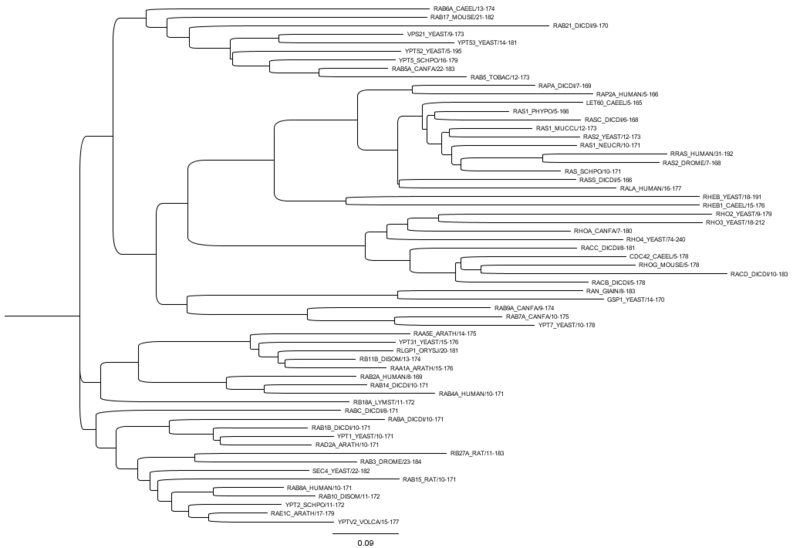
Structural alignment attempts to establish homology between two or more polymer structures based on their shape and three-dimensional conformation. This process is usually applied to protein tertiary structures but can also be used for large RNA molecules. In contrast to simple structural superposition, where at least some equivalent residues of the two structures are known, structural alignment requires no a priori knowledge of equivalent positions. Structural alignment is a valuable tool for the comparison of proteins with low sequence similarity, where evolutionary relationships between proteins cannot be easily detected by standard sequence alignment techniques. Structural alignment can therefore be used to imply evolutionary relationships between proteins that share very little common sequence. However, caution should be used in using the results as evidence for shared evolutionary ancestry because of the possible confounding effects of convergent evolution by which multiple unrelated amino acid sequences converge on a common tertiary structure.

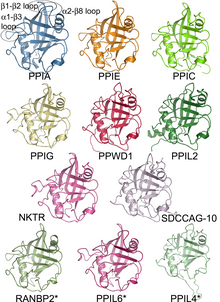
The Structural Classification of Proteins (SCOP) database is a largely manual classification of protein structural domains based on similarities of their structures and amino acid sequences. A motivation for this classification is to determine the evolutionary relationship between proteins. Proteins with the same shapes but having little sequence or functional similarity are placed in different superfamilies, and are assumed to have only a very distant common ancestor. Proteins having the same shape and some similarity of sequence and/or function are placed in "families", and are assumed to have a closer common ancestor.
In evolutionary biology, conserved sequences are identical or similar sequences in nucleic acids or proteins across species, or within a genome, or between donor and receptor taxa. Conservation indicates that a sequence has been maintained by natural selection.
In molecular biology, protein threading, also known as fold recognition, is a method of protein modeling which is used to model those proteins which have the same fold as proteins of known structures, but do not have homologous proteins with known structure. It differs from the homology modeling method of structure prediction as it is used for proteins which do not have their homologous protein structures deposited in the Protein Data Bank (PDB), whereas homology modeling is used for those proteins which do. Threading works by using statistical knowledge of the relationship between the structures deposited in the PDB and the sequence of the protein which one wishes to model.

Pfam is a database of protein families that includes their annotations and multiple sequence alignments generated using hidden Markov models. The most recent version, Pfam 36.0, was released in September 2023 and contains 20,795 families.
InterPro is a database of protein families, protein domains and functional sites in which identifiable features found in known proteins can be applied to new protein sequences in order to functionally characterise them.
Protein–protein interaction prediction is a field combining bioinformatics and structural biology in an attempt to identify and catalog physical interactions between pairs or groups of proteins. Understanding protein–protein interactions is important for the investigation of intracellular signaling pathways, modelling of protein complex structures and for gaining insights into various biochemical processes.

In molecular biology, a protein domain is a region of a protein's polypeptide chain that is self-stabilizing and that folds independently from the rest. Each domain forms a compact folded three-dimensional structure. Many proteins consist of several domains, and a domain may appear in a variety of different proteins. Molecular evolution uses domains as building blocks and these may be recombined in different arrangements to create proteins with different functions. In general, domains vary in length from between about 50 amino acids up to 250 amino acids in length. The shortest domains, such as zinc fingers, are stabilized by metal ions or disulfide bridges. Domains often form functional units, such as the calcium-binding EF hand domain of calmodulin. Because they are independently stable, domains can be "swapped" by genetic engineering between one protein and another to make chimeric proteins.
Protein subfamily is a level of protein classification, based on their close evolutionary relationship. It is below the larger levels of protein superfamily and protein family.
SUPERFAMILY is a database and search platform of structural and functional annotation for all proteins and genomes. It classifies amino acid sequences into known structural domains, especially into SCOP superfamilies. Domains are functional, structural, and evolutionary units that form proteins. Domains of common Ancestry are grouped into superfamilies. The domains and domain superfamilies are defined and described in SCOP. Superfamilies are groups of proteins which have structural evidence to support a common evolutionary ancestor but may not have detectable sequence homology.
Protein function prediction methods are techniques that bioinformatics researchers use to assign biological or biochemical roles to proteins. These proteins are usually ones that are poorly studied or predicted based on genomic sequence data. These predictions are often driven by data-intensive computational procedures. Information may come from nucleic acid sequence homology, gene expression profiles, protein domain structures, text mining of publications, phylogenetic profiles, phenotypic profiles, and protein-protein interaction. Protein function is a broad term: the roles of proteins range from catalysis of biochemical reactions to transport to signal transduction, and a single protein may play a role in multiple processes or cellular pathways.

In molecular biology and genetics, DNA annotation or genome annotation is the process of describing the structure and function of the components of a genome, by analyzing and interpreting them in order to extract their biological significance and understand the biological processes in which they participate. Among other things, it identifies the locations of genes and all the coding regions in a genome and determines what those genes do.

Cyrus Homi Chothia was an English biochemist who was an emeritus scientist at the Medical Research Council (MRC) Laboratory of Molecular Biology (LMB) at the University of Cambridge and emeritus fellow of Wolfson College, Cambridge.
A protein superfamily is the largest grouping (clade) of proteins for which common ancestry can be inferred. Usually this common ancestry is inferred from structural alignment and mechanistic similarity, even if no sequence similarity is evident. Sequence homology can then be deduced even if not apparent. Superfamilies typically contain several protein families which show sequence similarity within each family. The term protein clan is commonly used for protease and glycosyl hydrolases superfamilies based on the MEROPS and CAZy classification systems.

The PA clan is the largest group of proteases with common ancestry as identified by structural homology. Members have a chymotrypsin-like fold and similar proteolysis mechanisms but can have identity of <10%. The clan contains both cysteine and serine proteases. PA clan proteases can be found in plants, animals, fungi, eubacteria, archaea and viruses.