Alternatively, a regular language can be defined as a language recognised by a finite automaton. The equivalence of regular expressions and finite automata is known as Kleene's theorem[3] (after American mathematician Stephen Cole Kleene). In the Chomsky hierarchy, regular languages are the languages generated by Type-3 grammars.
Formal definition
The collection of regular languages over an alphabet Σ is defined recursively as follows:
The empty language Ø is a regular language.
For each a ∈ Σ (a belongs to Σ), the singleton language {a} is a regular language.
If A is a regular language, A* (Kleene star) is a regular language. Due to this, the empty string language {ε} is also regular.
If A and B are regular languages, then A ∪ B (union) and A • B (concatenation) are regular languages.
All finite languages are regular; in particular the empty string language {ε} = Ø* is regular. Other typical examples include the language consisting of all strings over the alphabet {a, b} which contain an even number of a's, or the language consisting of all strings of the form: several a's followed by several b's.
A simple example of a language that is not regular is the set of strings {anbn | n ≥ 0}.[4] Intuitively, it cannot be recognized with a finite automaton, since a finite automaton has finite memory and it cannot remember the exact number of a's. Techniques to prove this fact rigorously are given below.
Equivalent formalisms
A regular language satisfies the following equivalent properties:
it is the language of a regular expression (by the above definition)
Properties 10. and 11. are purely algebraic approaches to define regular languages; a similar set of statements can be formulated for a monoid M ⊆ Σ*. In this case, equivalence over M leads to the concept of a recognizable language.
Some authors use one of the above properties different from "1." as an alternative definition of regular languages.
Some of the equivalences above, particularly those among the first four formalisms, are called Kleene's theorem in textbooks. Precisely which one (or which subset) is called such varies between authors. One textbook calls the equivalence of regular expressions and NFAs ("1." and "2." above) "Kleene's theorem".[6] Another textbook calls the equivalence of regular expressions and DFAs ("1." and "3." above) "Kleene's theorem".[7] Two other textbooks first prove the expressive equivalence of NFAs and DFAs ("2." and "3.") and then state "Kleene's theorem" as the equivalence between regular expressions and finite automata (the latter said to describe "recognizable languages").[2][8] A linguistically oriented text first equates regular grammars ("4." above) with DFAs and NFAs, calls the languages generated by (any of) these "regular", after which it introduces regular expressions which it terms to describe "rational languages", and finally states "Kleene's theorem" as the coincidence of regular and rational languages.[9] Other authors simply define "rational expression" and "regular expressions" as synonymous and do the same with "rational languages" and "regular languages".[1][2]
Apparently, the term "regular" originates from a 1951 technical report where Kleene introduced "regular events" and explicitly welcomed "any suggestions as to a more descriptive term".[10]Noam Chomsky, in his 1959 seminal article, used the term "regular" in a different meaning at first (referring to what is called "Chomsky normal form" today),[11] but noticed that his "finite state languages" were equivalent to Kleene's "regular events".[12]
Closure properties
The regular languages are closed under various operations, that is, if the languages K and L are regular, so is the result of the following operations:
the trio operations: string homomorphism, inverse string homomorphism, and intersection with regular languages. As a consequence they are closed under arbitrary finite state transductions, like quotientK / L with a regular language. Even more, regular languages are closed under quotients with arbitrary languages: If L is regular then L / K is regular for any K.[15]
the reverse (or mirror image) LR.[16] Given a nondeterministic finite automaton to recognize L, an automaton for LR can be obtained by reversing all transitions and interchanging starting and finishing states. This may result in multiple starting states; ε-transitions can be used to join them.
Decidability properties
Given two deterministic finite automata A and B, it is decidable whether they accept the same language.[17] As a consequence, using the above closure properties, the following problems are also decidable for arbitrarily given deterministic finite automata A and B, with accepted languages LA and LB, respectively:
For regular expressions, the universality problem is NP-complete already for a singleton alphabet.[18] For larger alphabets, that problem is PSPACE-complete.[19] If regular expressions are extended to allow also a squaring operator, with "A2" denoting the same as "AA", still just regular languages can be described, but the universality problem has an exponential space lower bound,[20][21][22] and is in fact complete for exponential space with respect to polynomial-time reduction.[23]
For a fixed finite alphabet, the theory of the set of all languages — together with strings, membership of a string in a language, and for each character, a function to append the character to a string (and no other operations) — is decidable, and its minimal elementary substructure consists precisely of regular languages. For a binary alphabet, the theory is called S2S.[24]
Complexity results
In computational complexity theory, the complexity class of all regular languages is sometimes referred to as REGULAR or REG and equals DSPACE(O(1)), the decision problems that can be solved in constant space (the space used is independent of the input size). REGULAR ≠ AC0, since it (trivially) contains the parity problem of determining whether the number of 1 bits in the input is even or odd and this problem is not in AC0.[25] On the other hand, REGULAR does not contain AC0, because the nonregular language of palindromes, or the nonregular language can both be recognized in AC0.[26]
If a language is not regular, it requires a machine with at least Ω(loglogn) space to recognize (where n is the input size).[27] In other words, DSPACE(o(loglogn)) equals the class of regular languages. In practice, most nonregular problems are solved by machines taking at least logarithmic space.
Location in the Chomsky hierarchy
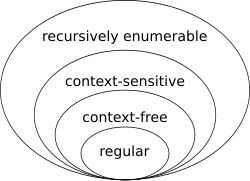
Regular language in classes of Chomsky hierarchy
To locate the regular languages in the Chomsky hierarchy, one notices that every regular language is context-free. The converse is not true: for example, the language consisting of all strings having the same number of a's as b's is context-free but not regular. To prove that a language is not regular, one often uses the Myhill–Nerode theorem and the pumping lemma. Other approaches include using the closure properties of regular languages[28] or quantifying Kolmogorov complexity.[29]
Important subclasses of regular languages include
Finite languages, those containing only a finite number of words.[30] These are regular languages, as one can create a regular expression that is the union of every word in the language.
Star-free languages, those that can be described by a regular expression constructed from the empty symbol, letters, concatenation and all boolean operators (see algebra of sets) including complementation but not the Kleene star: this class includes all finite languages.[31]
Thus, non-regularity of certain languages can be proved by counting the words of a given length in . Consider, for example, the Dyck language of strings of balanced parentheses. The number of words of length in the Dyck language is equal to the Catalan number, which is not of the form , witnessing the non-regularity of the Dyck language. Care must be taken since some of the eigenvalues could have the same magnitude. For example, the number of words of length in the language of all even binary words is not of the form , but the number of words of even or odd length are of this form; the corresponding eigenvalues are . In general, for every regular language there exists a constant such that for all , the number of words of length is asymptotically .[37]
The zeta function of a regular language is not in general rational, but that of an arbitrary cyclic language is.[38][39]
Generalizations
The notion of a regular language has been generalized to infinite words (see ω-automata) and to trees (see tree automaton).
Rational set generalizes the notion (of regular/rational language) to monoids that are not necessarily free. Likewise, the notion of a recognizable language (by a finite automaton) has namesake as recognizable set over a monoid that is not necessarily free. Howard Straubing notes in relation to these facts that “The term "regular language" is a bit unfortunate. Papers influenced by Eilenberg's monograph[40] often use either the term "recognizable language", which refers to the behavior of automata, or "rational language", which refers to important analogies between regular expressions and rational power series. (In fact, Eilenberg defines rational and recognizable subsets of arbitrary monoids; the two notions do not, in general, coincide.) This terminology, while better motivated, never really caught on, and "regular language" is used almost universally.”[41]
↑ Check if LA ∩ LB = LA. Deciding this property is NP-hard in general; see File:RegSubsetNP.pdf for an illustration of the proof idea.
Related Research Articles
In formal language theory, a context-free language (CFL),also called Chomsky type-2 language, is a language generated by a context-free grammar (CFG).
In logic, mathematics, computer science, and linguistics, a formal language consists of words whose letters are taken from an alphabet and are well-formed according to a specific set of rules called a formal grammar.
Automata theory is the study of abstract machines and automata, as well as the computational problems that can be solved using them. It is a theory in theoretical computer science with close connections to mathematical logic. The word automata comes from the Greek word αὐτόματος, which means "self-acting, self-willed, self-moving". An automaton is an abstract self-propelled computing device which follows a predetermined sequence of operations automatically. An automaton with a finite number of states is called a Finite Automaton (FA) or Finite-State Machine (FSM). The figure on the right illustrates a finite-state machine, which is a well-known type of automaton. This automaton consists of states and transitions. As the automaton sees a symbol of input, it makes a transition to another state, according to its transition function, which takes the previous state and current input symbol as its arguments.
In mathematics, a Kleene algebra is an idempotent semiring endowed with a closure operator. It generalizes the operations known from regular expressions.
In the theory of formal languages, the Myhill–Nerode theorem provides a necessary and sufficient condition for a language to be regular. The theorem is named for John Myhill and Anil Nerode, who proved it at the University of Chicago in 1957.
In abstract algebra, the free monoid on a set is the monoid whose elements are all the finite sequences of zero or more elements from that set, with string concatenation as the monoid operation and with the unique sequence of zero elements, often called the empty string and denoted by ε or λ, as the identity element. The free monoid on a set A is usually denoted A∗. The free semigroup on A is the subsemigroup of A∗ containing all elements except the empty string. It is usually denoted A+.
In the theory of computation, a branch of theoretical computer science, a deterministic finite automaton (DFA)—also known as deterministic finite acceptor (DFA), deterministic finite-state machine (DFSM), or deterministic finite-state automaton (DFSA)—is a finite-state machine that accepts or rejects a given string of symbols, by running through a state sequence uniquely determined by the string. Deterministic refers to the uniqueness of the computation run. In search of the simplest models to capture finite-state machines, Warren McCulloch and Walter Pitts were among the first researchers to introduce a concept similar to finite automata in 1943.
In automata theory, a finite-state machine is called a deterministic finite automaton (DFA), if
In theoretical computer science, more precisely in the theory of formal languages, the star height is a measure for the structural complexity of regular expressions and regular languages. The star height of a regular expression equals the maximum nesting depth of stars appearing in that expression. The star height of a regular language is the least star height of any regular expression for that language. The concept of star height was first defined and studied by Eggan (1963).
In mathematics and computer science, the syntactic monoid of a formal language is the smallest monoid that recognizes the language .
In automata theory, a deterministic pushdown automaton is a variation of the pushdown automaton. The class of deterministic pushdown automata accepts the deterministic context-free languages, a proper subset of context-free languages.
In formal language theory, an alphabet, sometimes called a vocabulary, is a non-empty set of indivisible symbols/glyphs, typically thought of as representing letters, characters, digits, phonemes, or even words. Alphabets in this technical sense of a set are used in a diverse range of fields including logic, mathematics, computer science, and linguistics. An alphabet may have any cardinality ("size") and, depending on its purpose, may be finite, countable, or even uncountable.
A regular language is said to be star-free if it can be described by a regular expression constructed from the letters of the alphabet, the empty word, the empty set symbol, all boolean operators – including complementation – and concatenation but no Kleene star. The condition is equivalent to having generalized star height zero.
In computer science, in the area of formal language theory, frequent use is made of a variety of string functions; however, the notation used is different from that used for computer programming, and some commonly used functions in the theoretical realm are rarely used when programming. This article defines some of these basic terms.
In automata theory, DFA minimization is the task of transforming a given deterministic finite automaton (DFA) into an equivalent DFA that has a minimum number of states. Here, two DFAs are called equivalent if they recognize the same regular language. Several different algorithms accomplishing this task are known and described in standard textbooks on automata theory.
In computer science, more specifically in automata and formal language theory, nested words are a concept proposed by Alur and Madhusudan as a joint generalization of words, as traditionally used for modelling linearly ordered structures, and of ordered unranked trees, as traditionally used for modelling hierarchical structures. Finite-state acceptors for nested words, so-called nested word automata, then give a more expressive generalization of finite automata on words. The linear encodings of languages accepted by finite nested word automata gives the class of visibly pushdown languages. The latter language class lies properly between the regular languages and the deterministic context-free languages. Since their introduction in 2004, these concepts have triggered much research in that area.
In computer science, more precisely in automata theory, a recognizable set of a monoid is a subset that can be distinguished by some homomorphism to a finite monoid. Recognizable sets are useful in automata theory, formal languages and algebra.
In computer science, more precisely in automata theory, a rational set of a monoid is an element of the minimal class of subsets of this monoid that contains all finite subsets and is closed under union, product and Kleene star. Rational sets are useful in automata theory, formal languages and algebra.
In theoretical computer science, in particular in formal language theory, Kleene's algorithm transforms a given nondeterministic finite automaton (NFA) into a regular expression. Together with other conversion algorithms, it establishes the equivalence of several description formats for regular languages. Alternative presentations of the same method include the "elimination method" attributed to Brzozowski and McCluskey, the algorithm of McNaughton and Yamada, and the use of Arden's lemma.
In computer science, in particular in formal language theory, a quotient automaton can be obtained from a given nondeterministic finite automaton by joining some of its states. The quotient recognizes a superset of the given automaton; in some cases, handled by the Myhill–Nerode theorem, both languages are equal.
↑ Sheng Yu (1997). "Regular languages". In Grzegorz Rozenberg; Arto Salomaa (eds.). Handbook of Formal Languages: Volume 1. Word, Language, Grammar. Springer. p.41. ISBN978-3-540-60420-4.
↑ Eilenberg (1974), p. 16 (Example II, 2.8) and p. 25 (Example II, 5.2).
↑ M. Weyer: Chapter 12 - Decidability of S1S and S2S, p. 219, Theorem 12.26. In: Erich Grädel, Wolfgang Thomas, Thomas Wilke (Eds.): Automata, Logics, and Infinite Games: A Guide to Current Research. Lecture Notes in Computer Science 2500, Springer 2002.
↑ Fellows, Michael R.; Langston, Michael A. (1991). "Constructivity issues in graph algorithms". In Myers, J. Paul Jr.; O'Donnell, Michael J. (eds.). Constructivity in Computer Science, Summer Symposium, San Antonio, Texas, USA, June 19-22, Proceedings. Lecture Notes in Computer Science. Vol.613. Springer. pp.150–158. doi:10.1007/BFB0021088.
↑ Hopcroft, Ullman (1979), Chapter 3, Exercise 3.4g, p. 72
↑ Hopcroft, Ullman (1979), Theorem 3.8, p.64; see also Theorem 3.10, p.67
↑ Cook, Stephen; Nguyen, Phuong (2010). Logical foundations of proof complexity (1. publ.ed.). Ithaca, NY: Association for Symbolic Logic. p.75. ISBN978-0-521-51729-4.
↑ J. Hartmanis, P. L. Lewis II, and R. E. Stearns. Hierarchies of memory-limited computations. Proceedings of the 6th Annual IEEE Symposium on Switching Circuit Theory and Logic Design, pp. 179–190. 1965.
↑ Samuel Eilenberg. Automata, languages, and machines. Academic Press. in two volumes "A" (1974, ISBN9780080873749) and "B" (1976, ISBN9780080873756), the latter with two chapters by Bret Tilson.
Kleene, S.C.: Representation of events in nerve nets and finite automata. In: Shannon, C.E., McCarthy, J. (eds.) Automata Studies, pp.3–41. Princeton University Press, Princeton (1956); it is a slightly modified version of his 1951 RAND Corporation report of the same title, RM704.
Sakarovitch, J (1987). "Kleene's theorem revisited". Trends, Techniques, and Problems in Theoretical Computer Science. Lecture Notes in Computer Science. Vol.1987. pp.39–50. doi:10.1007/3540185356_29. ISBN978-3-540-18535-2.
Each category of languages, except those marked by a *, is a proper subset of the category directly above it.Any language in each category is generated by a grammar and by an automaton in the category in the same line.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.