
In physics and mathematics, the Lorentz group is the group of all Lorentz transformations of Minkowski spacetime, the classical and quantum setting for all (non-gravitational) physical phenomena. The Lorentz group is named for the Dutch physicist Hendrik Lorentz.
In mathematics, a Gaussian function, often simply referred to as a Gaussian, is a function of the base form
In statistics, Cochran's theorem, devised by William G. Cochran, is a theorem used to justify results relating to the probability distributions of statistics that are used in the analysis of variance.
Ridge regression is a method of estimating the coefficients of multiple-regression models in scenarios where the independent variables are highly correlated. It has been used in many fields including econometrics, chemistry, and engineering. Also known as Tikhonov regularization, named for Andrey Tikhonov, it is a method of regularization of ill-posed problems. It is particularly useful to mitigate the problem of multicollinearity in linear regression, which commonly occurs in models with large numbers of parameters. In general, the method provides improved efficiency in parameter estimation problems in exchange for a tolerable amount of bias.
In mathematics, the Weierstrass functions are special functions of a complex variable that are auxiliary to the Weierstrass elliptic function. They are named for Karl Weierstrass. The relation between the sigma, zeta, and functions is analogous to that between the sine, cotangent, and squared cosecant functions: the logarithmic derivative of the sine is the cotangent, whose derivative is negative the squared cosecant.
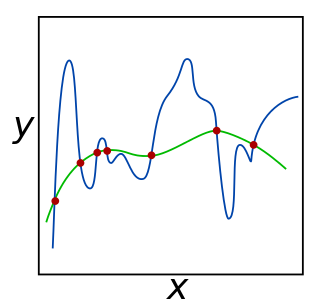
In mathematics, statistics, finance, and computer science, particularly in machine learning and inverse problems, regularization is a process that changes the result answer to be "simpler". It is often used to obtain results for ill-posed problems or to prevent overfitting.
The quantum Heisenberg model, developed by Werner Heisenberg, is a statistical mechanical model used in the study of critical points and phase transitions of magnetic systems, in which the spins of the magnetic systems are treated quantum mechanically. It is related to the prototypical Ising model, where at each site of a lattice, a spin represents a microscopic magnetic dipole to which the magnetic moment is either up or down. Except the coupling between magnetic dipole moments, there is also a multipolar version of Heisenberg model called the multipolar exchange interaction.
In the mathematical discipline of functional analysis, the concept of a compact operator on Hilbert space is an extension of the concept of a matrix acting on a finite-dimensional vector space; in Hilbert space, compact operators are precisely the closure of finite-rank operators in the topology induced by the operator norm. As such, results from matrix theory can sometimes be extended to compact operators using similar arguments. By contrast, the study of general operators on infinite-dimensional spaces often requires a genuinely different approach.
Covariance matrix adaptation evolution strategy (CMA-ES) is a particular kind of strategy for numerical optimization. Evolution strategies (ES) are stochastic, derivative-free methods for numerical optimization of non-linear or non-convex continuous optimization problems. They belong to the class of evolutionary algorithms and evolutionary computation. An evolutionary algorithm is broadly based on the principle of biological evolution, namely the repeated interplay of variation and selection: in each generation (iteration) new individuals are generated by variation, usually in a stochastic way, of the current parental individuals. Then, some individuals are selected to become the parents in the next generation based on their fitness or objective function value . Like this, over the generation sequence, individuals with better and better -values are generated.
In mathematics and mathematical physics, raising and lowering indices are operations on tensors which change their type. Raising and lowering indices are a form of index manipulation in tensor expressions.
In mathematics, every analytic function can be used for defining a matrix function that maps square matrices with complex entries to square matrices of the same size.
In the fields of computer vision and image analysis, the Harris affine region detector belongs to the category of feature detection. Feature detection is a preprocessing step of several algorithms that rely on identifying characteristic points or interest points so to make correspondences between images, recognize textures, categorize objects or build panoramas.
In mathematics, the spectral theory of ordinary differential equations is the part of spectral theory concerned with the determination of the spectrum and eigenfunction expansion associated with a linear ordinary differential equation. In his dissertation, Hermann Weyl generalized the classical Sturm–Liouville theory on a finite closed interval to second order differential operators with singularities at the endpoints of the interval, possibly semi-infinite or infinite. Unlike the classical case, the spectrum may no longer consist of just a countable set of eigenvalues, but may also contain a continuous part. In this case the eigenfunction expansion involves an integral over the continuous part with respect to a spectral measure, given by the Titchmarsh–Kodaira formula. The theory was put in its final simplified form for singular differential equations of even degree by Kodaira and others, using von Neumann's spectral theorem. It has had important applications in quantum mechanics, operator theory and harmonic analysis on semisimple Lie groups.
In computer science, online machine learning is a method of machine learning in which data becomes available in a sequential order and is used to update the best predictor for future data at each step, as opposed to batch learning techniques which generate the best predictor by learning on the entire training data set at once. Online learning is a common technique used in areas of machine learning where it is computationally infeasible to train over the entire dataset, requiring the need of out-of-core algorithms. It is also used in situations where it is necessary for the algorithm to dynamically adapt to new patterns in the data, or when the data itself is generated as a function of time, e.g., stock price prediction. Online learning algorithms may be prone to catastrophic interference, a problem that can be addressed by incremental learning approaches.
Within bayesian statistics for machine learning, kernel methods arise from the assumption of an inner product space or similarity structure on inputs. For some such methods, such as support vector machines (SVMs), the original formulation and its regularization were not Bayesian in nature. It is helpful to understand them from a Bayesian perspective. Because the kernels are not necessarily positive semidefinite, the underlying structure may not be inner product spaces, but instead more general reproducing kernel Hilbert spaces. In Bayesian probability kernel methods are a key component of Gaussian processes, where the kernel function is known as the covariance function. Kernel methods have traditionally been used in supervised learning problems where the input space is usually a space of vectors while the output space is a space of scalars. More recently these methods have been extended to problems that deal with multiple outputs such as in multi-task learning.
In machine learning, the kernel embedding of distributions comprises a class of nonparametric methods in which a probability distribution is represented as an element of a reproducing kernel Hilbert space (RKHS). A generalization of the individual data-point feature mapping done in classical kernel methods, the embedding of distributions into infinite-dimensional feature spaces can preserve all of the statistical features of arbitrary distributions, while allowing one to compare and manipulate distributions using Hilbert space operations such as inner products, distances, projections, linear transformations, and spectral analysis. This learning framework is very general and can be applied to distributions over any space on which a sensible kernel function may be defined. For example, various kernels have been proposed for learning from data which are: vectors in , discrete classes/categories, strings, graphs/networks, images, time series, manifolds, dynamical systems, and other structured objects. The theory behind kernel embeddings of distributions has been primarily developed by Alex Smola, Le Song , Arthur Gretton, and Bernhard Schölkopf. A review of recent works on kernel embedding of distributions can be found in.
In the field of statistical learning theory, matrix regularization generalizes notions of vector regularization to cases where the object to be learned is a matrix. The purpose of regularization is to enforce conditions, for example sparsity or smoothness, that can produce stable predictive functions. For example, in the more common vector framework, Tikhonov regularization optimizes over
Regularized least squares (RLS) is a family of methods for solving the least-squares problem while using regularization to further constrain the resulting solution.
Low-rank matrix approximations are essential tools in the application of kernel methods to large-scale learning problems.
The quaternion estimator algorithm (QUEST) is an algorithm designed to solve Wahba's problem, that consists of finding a rotation matrix between two coordinate systems from two sets of observations sampled in each system respectively. The key idea behind the algorithm is to find an expression of the loss function for the Wahba's problem as a quadratic form, using the Cayley–Hamilton theorem and the Newton–Raphson method to efficiently solve the eigenvalue problem and construct a numerically stable representation of the solution.


























































