
Principal component analysis (PCA) is a linear dimensionality reduction technique with applications in exploratory data analysis, visualization and data preprocessing.

Nonlinear dimensionality reduction, also known as manifold learning, refers to various related techniques that aim to project high-dimensional data onto lower-dimensional latent manifolds, with the goal of either visualizing the data in the low-dimensional space, or learning the mapping itself. The techniques described below can be understood as generalizations of linear decomposition methods used for dimensionality reduction, such as singular value decomposition and principal component analysis.

In linear algebra, a Jordan normal form, also known as a Jordan canonical form (JCF), is an upper triangular matrix of a particular form called a Jordan matrix representing a linear operator on a finite-dimensional vector space with respect to some basis. Such a matrix has each non-zero off-diagonal entry equal to 1, immediately above the main diagonal, and with identical diagonal entries to the left and below them.
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text. A matrix containing word counts per document is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Documents are then compared by cosine similarity between any two columns. Values close to 1 represent very similar documents while values close to 0 represent very dissimilar documents.
Partial least squares regression is a statistical method that bears some relation to principal components regression; instead of finding hyperplanes of maximum variance between the response and independent variables, it finds a linear regression model by projecting the predicted variables and the observable variables to a new space. Because both the X and Y data are projected to new spaces, the PLS family of methods are known as bilinear factor models. Partial least squares discriminant analysis (PLS-DA) is a variant used when the Y is categorical.
Non-negative matrix factorization, also non-negative matrix approximation is a group of algorithms in multivariate analysis and linear algebra where a matrix V is factorized into (usually) two matrices W and H, with the property that all three matrices have no negative elements. This non-negativity makes the resulting matrices easier to inspect. Also, in applications such as processing of audio spectrograms or muscular activity, non-negativity is inherent to the data being considered. Since the problem is not exactly solvable in general, it is commonly approximated numerically.
Numerical linear algebra, sometimes called applied linear algebra, is the study of how matrix operations can be used to create computer algorithms which efficiently and accurately provide approximate answers to questions in continuous mathematics. It is a subfield of numerical analysis, and a type of linear algebra. Computers use floating-point arithmetic and cannot exactly represent irrational data, so when a computer algorithm is applied to a matrix of data, it can sometimes increase the difference between a number stored in the computer and the true number that it is an approximation of. Numerical linear algebra uses properties of vectors and matrices to develop computer algorithms that minimize the error introduced by the computer, and is also concerned with ensuring that the algorithm is as efficient as possible.

In time series analysis, singular spectrum analysis (SSA) is a nonparametric spectral estimation method. It combines elements of classical time series analysis, multivariate statistics, multivariate geometry, dynamical systems and signal processing. Its roots lie in the classical Karhunen (1946)–Loève spectral decomposition of time series and random fields and in the Mañé (1981)–Takens (1981) embedding theorem. SSA can be an aid in the decomposition of time series into a sum of components, each having a meaningful interpretation. The name "singular spectrum analysis" relates to the spectrum of eigenvalues in a singular value decomposition of a covariance matrix, and not directly to a frequency domain decomposition.
Sparse principal component analysis is a technique used in statistical analysis and, in particular, in the analysis of multivariate data sets. It extends the classic method of principal component analysis (PCA) for the reduction of dimensionality of data by introducing sparsity structures to the input variables.
In graph theory, the cycle rank of a directed graph is a digraph connectivity measure proposed first by Eggan and Büchi. Intuitively, this concept measures how close a digraph is to a directed acyclic graph (DAG), in the sense that a DAG has cycle rank zero, while a complete digraph of order n with a self-loop at each vertex has cycle rank n. The cycle rank of a directed graph is closely related to the tree-depth of an undirected graph and to the star height of a regular language. It has also found use in sparse matrix computations and logic (Rossman 2008).

Multilinear subspace learning is an approach for disentangling the causal factor of data formation and performing dimensionality reduction. The Dimensionality reduction can be performed on a data tensor that contains a collection of observations have been vectorized, or observations that are treated as matrices and concatenated into a data tensor. Here are some examples of data tensors whose observations are vectorized or whose observations are matrices concatenated into data tensor images (2D/3D), video sequences (3D/4D), and hyperspectral cubes (3D/4D).
Multilinear principal component analysis (MPCA) is a multilinear extension of principal component analysis (PCA). MPCA is employed in the analysis of M-way arrays, i.e. a cube or hyper-cube of numbers, also informally referred to as a "data tensor". M-way arrays may be modeled by
In numerical mathematics, hierarchical matrices (H-matrices) are used as data-sparse approximations of non-sparse matrices. While a sparse matrix of dimension can be represented efficiently in units of storage by storing only its non-zero entries, a non-sparse matrix would require units of storage, and using this type of matrices for large problems would therefore be prohibitively expensive in terms of storage and computing time. Hierarchical matrices provide an approximation requiring only units of storage, where is a parameter controlling the accuracy of the approximation. In typical applications, e.g., when discretizing integral equations, preconditioning the resulting systems of linear equations, or solving elliptic partial differential equations, a rank proportional to with a small constant is sufficient to ensure an accuracy of . Compared to many other data-sparse representations of non-sparse matrices, hierarchical matrices offer a major advantage: the results of matrix arithmetic operations like matrix multiplication, factorization or inversion can be approximated in operations, where
In mathematics, low-rank approximation is a minimization problem, in which the cost function measures the fit between a given matrix and an approximating matrix, subject to a constraint that the approximating matrix has reduced rank. The problem is used for mathematical modeling and data compression. The rank constraint is related to a constraint on the complexity of a model that fits the data. In applications, often there are other constraints on the approximating matrix apart from the rank constraint, e.g., non-negativity and Hankel structure.
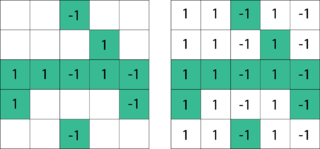
Matrix completion is the task of filling in the missing entries of a partially observed matrix, which is equivalent to performing data imputation in statistics. A wide range of datasets are naturally organized in matrix form. One example is the movie-ratings matrix, as appears in the Netflix problem: Given a ratings matrix in which each entry represents the rating of movie by customer , if customer has watched movie and is otherwise missing, we would like to predict the remaining entries in order to make good recommendations to customers on what to watch next. Another example is the document-term matrix: The frequencies of words used in a collection of documents can be represented as a matrix, where each entry corresponds to the number of times the associated term appears in the indicated document.
A CUR matrix approximation is a set of three matrices that, when multiplied together, closely approximate a given matrix. A CUR approximation can be used in the same way as the low-rank approximation of the singular value decomposition (SVD). CUR approximations are less accurate than the SVD, but they offer two key advantages, both stemming from the fact that the rows and columns come from the original matrix :

Foreground detection is one of the major tasks in the field of computer vision and image processing whose aim is to detect changes in image sequences. Background subtraction is any technique which allows an image's foreground to be extracted for further processing.

L1-norm principal component analysis (L1-PCA) is a general method for multivariate data analysis. L1-PCA is often preferred over standard L2-norm principal component analysis (PCA) when the analyzed data may contain outliers.
In numerical linear algebra, the Bartels–Stewart algorithm is used to numerically solve the Sylvester matrix equation . Developed by R.H. Bartels and G.W. Stewart in 1971, it was the first numerically stable method that could be systematically applied to solve such equations. The algorithm works by using the real Schur decompositions of and to transform into a triangular system that can then be solved using forward or backward substitution. In 1979, G. Golub, C. Van Loan and S. Nash introduced an improved version of the algorithm, known as the Hessenberg–Schur algorithm. It remains a standard approach for solving Sylvester equations when is of small to moderate size.
Namrata Vaswani is an Indian-American electrical engineer known for her research in compressed sensing, robust principal component analysis, signal processing, statistical learning theory, and computer vision. She is a Joseph and Elizabeth Anderlik Professor in Electrical and Computer Engineering at Iowa State University, and a professor of mathematics at Iowa State.














