
An alpha helix is a sequence of amino acids in a protein that are twisted into a coil.
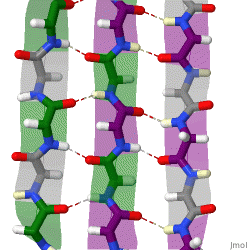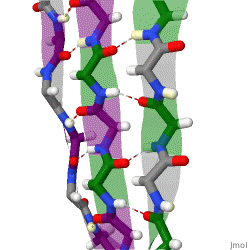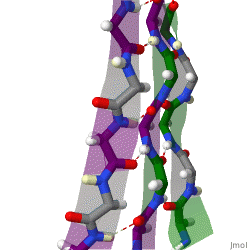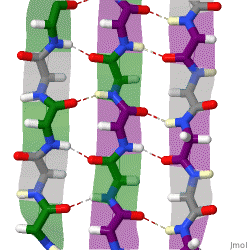
The beta sheet is a common motif of the regular protein secondary structure. Beta sheets consist of beta strands (β-strands) connected laterally by at least two or three backbone hydrogen bonds, forming a generally twisted, pleated sheet. A β-strand is a stretch of polypeptide chain typically 3 to 10 amino acids long with backbone in an extended conformation. The supramolecular association of β-sheets has been implicated in the formation of the fibrils and protein aggregates observed in amyloidosis, Alzheimer's disease and other proteinopathies.

Protein structure prediction is the inference of the three-dimensional structure of a protein from its amino acid sequence—that is, the prediction of its secondary and tertiary structure from primary structure. Structure prediction is different from the inverse problem of protein design. Protein structure prediction is one of the most important goals pursued by computational biology; it is important in medicine and biotechnology.
In bioinformatics and evolutionary biology, a substitution matrix describes the frequency at which a character in a nucleotide sequence or a protein sequence changes to other character states over evolutionary time. The information is often in the form of log odds of finding two specific character states aligned and depends on the assumed number of evolutionary changes or sequence dissimilarity between compared sequences. It is an application of a stochastic matrix. Substitution matrices are usually seen in the context of amino acid or DNA sequence alignments, where they are used to calculate similarity scores between the aligned sequences.
In biology, a sequence motif is a nucleotide or amino-acid sequence pattern that is widespread and usually assumed to be related to biological function of the macromolecule. For example, an N-glycosylation site motif can be defined as Asn, followed by anything but Pro, followed by either Ser or Thr, followed by anything but Pro residue.

Structural bioinformatics is the branch of bioinformatics that is related to the analysis and prediction of the three-dimensional structure of biological macromolecules such as proteins, RNA, and DNA. It deals with generalizations about macromolecular 3D structures such as comparisons of overall folds and local motifs, principles of molecular folding, evolution, binding interactions, and structure/function relationships, working both from experimentally solved structures and from computational models. The term structural has the same meaning as in structural biology, and structural bioinformatics can be seen as a part of computational structural biology. The main objective of structural bioinformatics is the creation of new methods of analysing and manipulating biological macromolecular data in order to solve problems in biology and generate new knowledge.

Protein structure is the three-dimensional arrangement of atoms in an amino acid-chain molecule. Proteins are polymers – specifically polypeptides – formed from sequences of amino acids, which are the monomers of the polymer. A single amino acid monomer may also be called a residue, which indicates a repeating unit of a polymer. Proteins form by amino acids undergoing condensation reactions, in which the amino acids lose one water molecule per reaction in order to attach to one another with a peptide bond. By convention, a chain under 30 amino acids is often identified as a peptide, rather than a protein. To be able to perform their biological function, proteins fold into one or more specific spatial conformations driven by a number of non-covalent interactions, such as hydrogen bonding, ionic interactions, Van der Waals forces, and hydrophobic packing. To understand the functions of proteins at a molecular level, it is often necessary to determine their three-dimensional structure. This is the topic of the scientific field of structural biology, which employs techniques such as X-ray crystallography, NMR spectroscopy, cryo-electron microscopy (cryo-EM) and dual polarisation interferometry, to determine the structure of proteins.
Protein design is the rational design of new protein molecules to design novel activity, behavior, or purpose, and to advance basic understanding of protein function. Proteins can be designed from scratch or by making calculated variants of a known protein structure and its sequence. Rational protein design approaches make protein-sequence predictions that will fold to specific structures. These predicted sequences can then be validated experimentally through methods such as peptide synthesis, site-directed mutagenesis, or artificial gene synthesis.
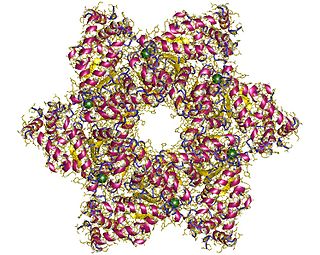
SV40 large T antigen is a hexamer protein that is a dominant-acting oncoprotein derived from the polyomavirus SV40. TAg is capable of inducing malignant transformation of a variety of cell types. The transforming activity of TAg is due in large part to its perturbation of the retinoblastoma (pRb) and p53 tumor suppressor proteins. In addition, TAg binds to several other cellular factors, including the transcriptional co-activators p300 and CBP, which may contribute to its transformation function. Similar proteins from related viruses are known as large tumor antigen in general.

The TIM barrel, also known as an alpha/beta barrel, is a conserved protein fold consisting of eight alpha helices (α-helices) and eight parallel beta strands (β-strands) that alternate along the peptide backbone. The structure is named after triose-phosphate isomerase, a conserved metabolic enzyme. TIM barrels are ubiquitous, with approximately 10% of all enzymes adopting this fold. Further, five of seven enzyme commission (EC) enzyme classes include TIM barrel proteins. The TIM barrel fold is evolutionarily ancient, with many of its members possessing little similarity today, instead falling within the twilight zone of sequence similarity.

The beta hairpin is a simple protein structural motif involving two beta strands that look like a hairpin. The motif consists of two strands that are adjacent in primary structure, oriented in an antiparallel direction, and linked by a short loop of two to five amino acids. Beta hairpins can occur in isolation or as part of a series of hydrogen bonded strands that collectively comprise a beta sheet.
Phi value analysis, analysis, or -value analysis is an experimental protein engineering technique for studying the structure of the folding transition state of small protein domains that fold in a two-state manner. The structure of the folding transition state is hard to find using methods such as protein NMR or X-ray crystallography because folding transitions states are mobile and partly unstructured by definition. In -value analysis, the folding kinetics and conformational folding stability of the wild-type protein are compared with those of point mutants to find phi values. These measure the mutant residue's energetic contribution to the folding transition state, which reveals the degree of native structure around the mutated residue in the transition state, by accounting for the relative free energies of the unfolded state, the folded state, and the transition state for the wild-type and mutant proteins.

Prolyl isomerase is an enzyme found in both prokaryotes and eukaryotes that interconverts the cis and trans isomers of peptide bonds with the amino acid proline. Proline has an unusually conformationally restrained peptide bond due to its cyclic structure with its side chain bonded to its secondary amine nitrogen. Most amino acids have a strong energetic preference for the trans peptide bond conformation due to steric hindrance, but proline's unusual structure stabilizes the cis form so that both isomers are populated under biologically relevant conditions. Proteins with prolyl isomerase activity include cyclophilin, FKBPs, and parvulin, although larger proteins can also contain prolyl isomerase domains.

In protein structure prediction, statistical potentials or knowledge-based potentials are scoring functions derived from an analysis of known protein structures in the Protein Data Bank (PDB).

In molecular biology, a protein domain is a region of a protein's polypeptide chain that is self-stabilizing and that folds independently from the rest. Each domain forms a compact folded three-dimensional structure. Many proteins consist of several domains, and a domain may appear in a variety of different proteins. Molecular evolution uses domains as building blocks and these may be recombined in different arrangements to create proteins with different functions. In general, domains vary in length from between about 50 amino acids up to 250 amino acids in length. The shortest domains, such as zinc fingers, are stabilized by metal ions or disulfide bridges. Domains often form functional units, such as the calcium-binding EF hand domain of calmodulin. Because they are independently stable, domains can be "swapped" by genetic engineering between one protein and another to make chimeric proteins.

The Gaussian network model (GNM) is a representation of a biological macromolecule as an elastic mass-and-spring network to study, understand, and characterize the mechanical aspects of its long-time large-scale dynamics. The model has a wide range of applications from small proteins such as enzymes composed of a single domain, to large macromolecular assemblies such as a ribosome or a viral capsid. Protein domain dynamics plays key roles in a multitude of molecular recognition and cell signalling processes. Protein domains, connected by intrinsically disordered flexible linker domains, induce long-range allostery via protein domain dynamics. The resultant dynamic modes cannot be generally predicted from static structures of either the entire protein or individual domains.
The Walker A and Walker B motifs are protein sequence motifs, known to have highly conserved three-dimensional structures. These were first reported in ATP-binding proteins by Walker and co-workers in 1982.

The WW domain is a modular protein domain that mediates specific interactions with protein ligands. This domain is found in a number of unrelated signaling and structural proteins and may be repeated up to four times in some proteins. Apart from binding preferentially to proteins that are proline-rich, with particular proline-motifs, [AP]-P-P-[AP]-Y, some WW domains bind to phosphoserine- and phosphothreonine-containing motifs.
A protein superfamily is the largest grouping (clade) of proteins for which common ancestry can be inferred. Usually this common ancestry is inferred from structural alignment and mechanistic similarity, even if no sequence similarity is evident. Sequence homology can then be deduced even if not apparent. Superfamilies typically contain several protein families which show sequence similarity within each family. The term protein clan is commonly used for protease and glycosyl hydrolases superfamilies based on the MEROPS and CAZy classification systems.
Direct coupling analysis or DCA is an umbrella term comprising several methods for analyzing sequence data in computational biology. The common idea of these methods is to use statistical modeling to quantify the strength of the direct relationship between two positions of a biological sequence, excluding effects from other positions. This contrasts usual measures of correlation, which can be large even if there is no direct relationship between the positions. Such a direct relationship can for example be the evolutionary pressure for two positions to maintain mutual compatibility in the biomolecular structure of the sequence, leading to molecular coevolution between the two positions.



