
In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.
The P versus NP problem is a major unsolved problem in theoretical computer science. Informally, it asks whether every problem whose solution can be quickly verified can also be quickly solved.
Presburger arithmetic is the first-order theory of the natural numbers with addition, named in honor of Mojżesz Presburger, who introduced it in 1929. The signature of Presburger arithmetic contains only the addition operation and equality, omitting the multiplication operation entirely. The theory is computably axiomatizable; the axioms include a schema of induction.
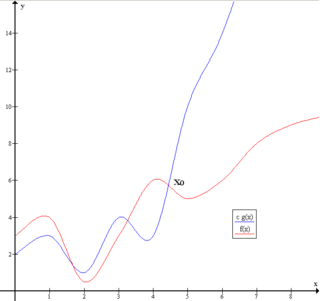
Big O notation is a mathematical notation that describes the limiting behavior of a function when the argument tends towards a particular value or infinity. Big O is a member of a family of notations invented by German mathematicians Paul Bachmann, Edmund Landau, and others, collectively called Bachmann–Landau notation or asymptotic notation. The letter O was chosen by Bachmann to stand for Ordnung, meaning the order of approximation.

Shellsort, also known as Shell sort or Shell's method, is an in-place comparison sort. It can be seen as either a generalization of sorting by exchange or sorting by insertion. The method starts by sorting pairs of elements far apart from each other, then progressively reducing the gap between elements to be compared. By starting with far-apart elements, it can move some out-of-place elements into the position faster than a simple nearest-neighbor exchange. Donald Shell published the first version of this sort in 1959. The running time of Shellsort is heavily dependent on the gap sequence it uses. For many practical variants, determining their time complexity remains an open problem.

In theoretical computer science, the time complexity is the computational complexity that describes the amount of computer time it takes to run an algorithm. Time complexity is commonly estimated by counting the number of elementary operations performed by the algorithm, supposing that each elementary operation takes a fixed amount of time to perform. Thus, the amount of time taken and the number of elementary operations performed by the algorithm are taken to be related by a constant factor.
A randomized algorithm is an algorithm that employs a degree of randomness as part of its logic or procedure. The algorithm typically uses uniformly random bits as an auxiliary input to guide its behavior, in the hope of achieving good performance in the "average case" over all possible choices of random determined by the random bits; thus either the running time, or the output are random variables.
In computer science, a selection algorithm is an algorithm for finding the th smallest value in a collection of ordered values, such as numbers. The value that it finds is called the th order statistic. Selection includes as special cases the problems of finding the minimum, median, and maximum element in the collection. Selection algorithms include quickselect, and the median of medians algorithm. When applied to a collection of values, these algorithms take linear time, as expressed using big O notation. For data that is already structured, faster algorithms may be possible; as an extreme case, selection in an already-sorted array takes time .

In graph theory, a vertex cover of a graph is a set of vertices that includes at least one endpoint of every edge of the graph.
In computational complexity theory, the Cook–Levin theorem, also known as Cook's theorem, states that the Boolean satisfiability problem is NP-complete. That is, it is in NP, and any problem in NP can be reduced in polynomial time by a deterministic Turing machine to the Boolean satisfiability problem.

In computer science, a suffix tree is a compressed trie containing all the suffixes of the given text as their keys and positions in the text as their values. Suffix trees allow particularly fast implementations of many important string operations.
In computational complexity theory, the parallel computation thesis is a hypothesis which states that the time used by a (reasonable) parallel machine is polynomially related to the space used by a sequential machine. The parallel computation thesis was set forth by Chandra and Stockmeyer in 1976.

László "Laci" Babai is a Hungarian professor of computer science and mathematics at the University of Chicago. His research focuses on computational complexity theory, algorithms, combinatorics, and finite groups, with an emphasis on the interactions between these fields.

The Donald E. Knuth Prize is a prize for outstanding contributions to the foundations of computer science, named after the American computer scientist Donald E. Knuth.
Richard Jay Lipton is an American computer scientist who is Associate Dean of Research, Professor, and the Frederick G. Storey Chair in Computing in the College of Computing at the Georgia Institute of Technology. He has worked in computer science theory, cryptography, and DNA computing.

In theoretical computer science, smoothed analysis is a way of measuring the complexity of an algorithm. Since its introduction in 2001, smoothed analysis has been used as a basis for considerable research, for problems ranging from mathematical programming, numerical analysis, machine learning, and data mining. It can give a more realistic analysis of the practical performance of the algorithm compared to analysis that uses worst-case or average-case scenarios.
In computer science, streaming algorithms are algorithms for processing data streams in which the input is presented as a sequence of items and can be examined in only a few passes, typically just one. These algorithms are designed to operate with limited memory, generally logarithmic in the size of the stream and/or in the maximum value in the stream, and may also have limited processing time per item.

Nondeterministic polynomial-time completeness, or NP-completeness is a complexity class of problems in computational complexity theory. A problem is NP-complete when:
- It is a decision problem, meaning that for any input to the problem, the output is either "yes" or "no".
- When the answer is "yes", this can be demonstrated through the existence of a short solution.
- The correctness of each solution can be verified quickly and a brute-force search algorithm can find a solution by trying all possible solutions.
- The problem can be used to simulate every other problem for which we can verify quickly that a solution is correct. In this sense, NP-complete problems are the hardest of the problems to which solutions can be verified quickly. If we could find solutions of some NP-complete problem quickly, we could quickly find the solutions of every other problem to which a given solution can be easily verified.
In computational complexity theory, the exponential time hypothesis is an unproven computational hardness assumption that was formulated by Impagliazzo & Paturi (1999). It states that satisfiability of 3-CNF Boolean formulas cannot be solved in subexponential time, . More precisely, the usual form of the hypothesis asserts the existence of a number such that all algorithms that correctly solve this problem require time at least The exponential time hypothesis, if true, would imply that P ≠ NP, but it is a stronger statement. It implies that many computational problems are equivalent in complexity, in the sense that if one of them has a subexponential time algorithm then they all do, and that many known algorithms for these problems have optimal or near-optimal time complexity.
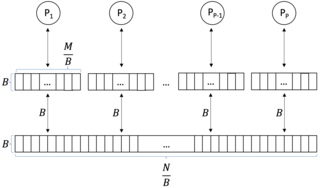
In computer science, a parallel external memory (PEM) model is a cache-aware, external-memory abstract machine. It is the parallel-computing analogy to the single-processor external memory (EM) model. In a similar way, it is the cache-aware analogy to the parallel random-access machine (PRAM). The PEM model consists of a number of processors, together with their respective private caches and a shared main memory.






