Related Research Articles
C is a general-purpose computer programming language. It was created in the 1970s by Dennis Ritchie, and remains very widely used and influential. By design, C's features cleanly reflect the capabilities of the targeted CPUs. It has found lasting use in operating systems, device drivers, protocol stacks, though decreasingly for application software, and is common in computer architectures that range from the largest supercomputers to the smallest microcontrollers and embedded systems.
Common Lisp (CL) is a dialect of the Lisp programming language, published in ANSI standard document ANSI INCITS 226-1994 (S20018). The Common Lisp HyperSpec, a hyperlinked HTML version, has been derived from the ANSI Common Lisp standard.

A Java virtual machine (JVM) is a virtual machine that enables a computer to run Java programs as well as programs written in other languages that are also compiled to Java bytecode. The JVM is detailed by a specification that formally describes what is required in a JVM implementation. Having a specification ensures interoperability of Java programs across different implementations so that program authors using the Java Development Kit (JDK) need not worry about idiosyncrasies of the underlying hardware platform.
Common Intermediate Language (CIL), formerly called Microsoft Intermediate Language (MSIL) or Intermediate Language (IL), is the intermediate language binary instruction set defined within the Common Language Infrastructure (CLI) specification. CIL instructions are executed by a CLI-compatible runtime environment such as the Common Language Runtime. Languages which target the CLI compile to CIL. CIL is object-oriented, stack-based bytecode. Runtimes typically just-in-time compile CIL instructions into native code.
Lua is a lightweight, high-level, multi-paradigm programming language designed primarily for embedded use in applications. Lua is cross-platform, since the interpreter of compiled bytecode is written in ANSI C, and Lua has a relatively simple C API to embed it into applications.

In computer science, an interpreter is a computer program that directly executes instructions written in a programming or scripting language, without requiring them previously to have been compiled into a machine language program. An interpreter generally uses one of the following strategies for program execution:
- Parse the source code and perform its behavior directly;
- Translate source code into some efficient intermediate representation or object code and immediately execute that;
- Explicitly execute stored precompiled bytecode made by a compiler and matched with the interpreter Virtual Machine.
In programming languages, a closure, also lexical closure or function closure, is a technique for implementing lexically scoped name binding in a language with first-class functions. Operationally, a closure is a record storing a function together with an environment. The environment is a mapping associating each free variable of the function with the value or reference to which the name was bound when the closure was created. Unlike a plain function, a closure allows the function to access those captured variables through the closure's copies of their values or references, even when the function is invoked outside their scope.
Bytecode, also termed p-code, is a form of instruction set designed for efficient execution by a software interpreter. Unlike human-readable source code, bytecodes are compact numeric codes, constants, and references that encode the result of compiler parsing and performing semantic analysis of things like type, scope, and nesting depths of program objects.
x86 assembly language is the name for the family of assembly languages which provide some level of backward compatibility with CPUs back to the Intel 8008 microprocessor, which was launched in April 1972. It is used to produce object code for the x86 class of processors.
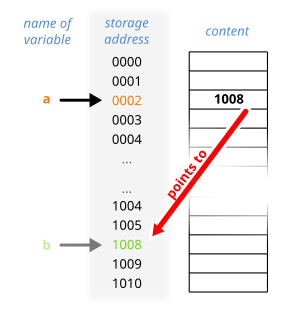
In computer science, a pointer is an object in many programming languages that stores a memory address. This can be that of another value located in computer memory, or in some cases, that of memory-mapped computer hardware. A pointer references a location in memory, and obtaining the value stored at that location is known as dereferencing the pointer. As an analogy, a page number in a book's index could be considered a pointer to the corresponding page; dereferencing such a pointer would be done by flipping to the page with the given page number and reading the text found on that page. The actual format and content of a pointer variable is dependent on the underlying computer architecture.
ActionScript is an object-oriented programming language originally developed by Macromedia Inc.. It is influenced by HyperTalk, the scripting language for HyperCard. It is now an implementation of ECMAScript, though it originally arose as a sibling, both being influenced by HyperTalk. ActionScript code is usually converted to byte-code format by the compiler.
This article compares two programming languages: C# with Java. While the focus of this article is mainly the languages and their features, such a comparison will necessarily also consider some features of platforms and libraries. For a more detailed comparison of the platforms, see Comparison of the Java and .NET platforms.
Partial template specialization is a particular form of class template specialization. Usually used in reference to the C++ programming language, it allows the programmer to specialize only some arguments of a class template, as opposed to explicit full specialization, where all the template arguments are provided.
typedef is a reserved keyword in the programming languages C and C++. It is used to create an additional name (alias) for another data type, but does not create a new type, except in the obscure case of a qualified typedef of an array type where the typedef qualifiers are transferred to the array element type. As such, it is often used to simplify the syntax of declaring complex data structures consisting of struct and union types, although it is also commonly used to provide specific descriptive type names for integer data types of varying sizes.

In computer science, recursion is a method of solving a computational problem where the solution depends on solutions to smaller instances of the same problem. Recursion solves such recursive problems by using functions that call themselves from within their own code. The approach can be applied to many types of problems, and recursion is one of the central ideas of computer science.
The power of recursion evidently lies in the possibility of defining an infinite set of objects by a finite statement. In the same manner, an infinite number of computations can be described by a finite recursive program, even if this program contains no explicit repetitions.
This article describes the syntax of the C# programming language. The features described are compatible with .NET Framework and Mono.

C# Open Source Managed Operating System (Cosmos) is a toolkit for building operating systems, written mostly in the programming language C# and small amounts of a high level assembly language named X#. Cosmos is a backronym, in that the acronym was chosen before the meaning. It is open-source software released under a BSD license.
This comparison of programming languages compares how object-oriented programming languages such as C++, Java, Smalltalk, Object Pascal, Perl, Python, and others manipulate data structures.
Java bytecode is the bytecode-structured instruction set of the Java virtual machine (JVM).
Kotlin is a cross-platform, statically typed, general-purpose programming language with type inference. Kotlin is designed to interoperate fully with Java, and the JVM version of Kotlin's standard library depends on the Java Class Library, but type inference allows its syntax to be more concise. Kotlin mainly targets the JVM, but also compiles to JavaScript or native code via LLVM. Language development costs are borne by JetBrains, while the Kotlin Foundation protects the Kotlin trademark.
References
- ↑ "bannana/language". GitHub . 17 February 2021.
- ↑ "banna - useless things". Archived from the original on 2016-10-24. Retrieved 2016-10-23.
- ↑ "bannana/language". GitHub . 17 February 2021.
- ↑ "SPECIFICATION - language - some fools attempt at an interpreted language".