In mathematics, a combination is a selection of items from a set that has distinct members, such that the order of selection does not matter. For example, given three fruits, say an apple, an orange and a pear, there are three combinations of two that can be drawn from this set: an apple and a pear; an apple and an orange; or a pear and an orange. More formally, a k-combination of a set S is a subset of k distinct elements of S. So, two combinations are identical if and only if each combination has the same members. If the set has n elements, the number of k-combinations, denoted by or , is equal to the binomial coefficient
In mathematics, a set is countable if either it is finite or it can be made in one to one correspondence with the set of natural numbers. Equivalently, a set is countable if there exists an injective function from it into the natural numbers; this means that each element in the set may be associated to a unique natural number, or that the elements of the set can be counted one at a time, although the counting may never finish due to an infinite number of elements.
In mathematics, one can often define a direct product of objects already known, giving a new one. This induces a structure on the Cartesian product of the underlying sets from that of the contributing objects. More abstractly, one talks about the product in category theory, which formalizes these notions.

In mathematics, an equivalence relation is a binary relation that is reflexive, symmetric and transitive. The equipollence relation between line segments in geometry is a common example of an equivalence relation. A simpler example is equality. Any number is equal to itself (reflexive). If , then (symmetric). If and , then (transitive).

In mathematics, when the elements of some set have a notion of equivalence, then one may naturally split the set into equivalence classes. These equivalence classes are constructed so that elements and belong to the same equivalence class if, and only if, they are equivalent.
In mathematics, the branch of real analysis studies the behavior of real numbers, sequences and series of real numbers, and real functions. Some particular properties of real-valued sequences and functions that real analysis studies include convergence, limits, continuity, smoothness, differentiability and integrability.

In mathematics, a sequence is an enumerated collection of objects in which repetitions are allowed and order matters. Like a set, it contains members. The number of elements is called the length of the sequence. Unlike a set, the same elements can appear multiple times at different positions in a sequence, and unlike a set, the order does matter. Formally, a sequence can be defined as a function from natural numbers to the elements at each position. The notion of a sequence can be generalized to an indexed family, defined as a function from an arbitrary index set.
In mathematics, a surjective function (also known as surjection, or onto function ) is a function f such that, for every element y of the function's codomain, there exists at least one element x in the function's domain such that f(x) = y. In other words, for a function f : X → Y, the codomain Y is the image of the function's domain X. It is not required that x be unique; the function f may map one or more elements of X to the same element of Y.
In combinatorial mathematics, the theory of combinatorial species is an abstract, systematic method for deriving the generating functions of discrete structures, which allows one to not merely count these structures but give bijective proofs involving them. Examples of combinatorial species are graphs, permutations, trees, and so on; each of these has an associated generating function which counts how many structures there are of a certain size. One goal of species theory is to be able to analyse complicated structures by describing them in terms of transformations and combinations of simpler structures. These operations correspond to equivalent manipulations of generating functions, so producing such functions for complicated structures is much easier than with other methods. The theory was introduced, carefully elaborated and applied by Canadian researchers around André Joyal.
In order theory, a field of mathematics, an incidence algebra is an associative algebra, defined for every locally finite partially ordered set and commutative ring with unity. Subalgebras called reduced incidence algebras give a natural construction of various types of generating functions used in combinatorics and number theory.
In combinatorial mathematics, the Bell numbers count the possible partitions of a set. These numbers have been studied by mathematicians since the 19th century, and their roots go back to medieval Japan. In an example of Stigler's law of eponymy, they are named after Eric Temple Bell, who wrote about them in the 1930s.

In combinatorial mathematics, the Catalan numbers are a sequence of natural numbers that occur in various counting problems, often involving recursively defined objects. They are named after the French-Belgian mathematician Eugène Charles Catalan.
In information theory, the asymptotic equipartition property (AEP) is a general property of the output samples of a stochastic source. It is fundamental to the concept of typical set used in theories of data compression.
The ultraproduct is a mathematical construction that appears mainly in abstract algebra and mathematical logic, in particular in model theory and set theory. An ultraproduct is a quotient of the direct product of a family of structures. All factors need to have the same signature. The ultrapower is the special case of this construction in which all factors are equal.

In mathematics, a partition of a set is a grouping of its elements into non-empty subsets, in such a way that every element is included in exactly one subset.

In combinatorics, a branch of mathematics, the inclusion–exclusion principle is a counting technique which generalizes the familiar method of obtaining the number of elements in the union of two finite sets; symbolically expressed as
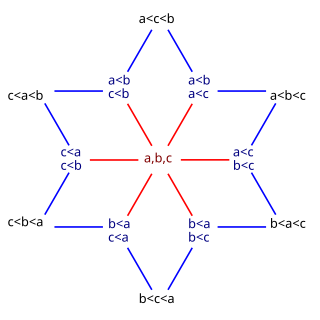
In mathematics, especially order theory, a weak ordering is a mathematical formalization of the intuitive notion of a ranking of a set, some of whose members may be tied with each other. Weak orders are a generalization of totally ordered sets and are in turn generalized by (strictly) partially ordered sets and preorders.

In combinatorics, the Eulerian number is the number of permutations of the numbers 1 to in which exactly elements are greater than the previous element.
In probability theory and statistics, a collection of random variables is independent and identically distributed if each random variable has the same probability distribution as the others and all are mutually independent. This property is usually abbreviated as i.i.d., iid, or IID. IID was first defined in statistics and finds application in different fields such as data mining and signal processing.
In mathematics, Kingman's subadditive ergodic theorem is one of several ergodic theorems. It can be seen as a generalization of Birkhoff's ergodic theorem. Intuitively, the subadditive ergodic theorem is a kind of random variable version of Fekete's lemma. As a result, it can be rephrased in the language of probability, e.g. using a sequence of random variables and expected values. The theorem is named after John Kingman.











































































