Related Research Articles
In information science, an ontology encompasses a representation, formal naming, and definitions of the categories, properties, and relations between the concepts, data, or entities that pertain to one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of terms and relational expressions that represent the entities in that subject area. The field which studies ontologies so conceived is sometimes referred to as applied ontology.

A glossary, also known as a vocabulary or clavis, is an alphabetical list of terms in a particular domain of knowledge with the definitions for those terms. Traditionally, a glossary appears at the end of a book and includes terms within that book that are either newly introduced, uncommon, or specialized. While glossaries are most commonly associated with non-fiction books, in some cases, fiction novels sometimes include a glossary for unfamiliar terms.
A medical classification is used to transform descriptions of medical diagnoses or procedures into standardized statistical code in a process known as clinical coding. Diagnosis classifications list diagnosis codes, which are used to track diseases and other health conditions, inclusive of chronic diseases such as diabetes mellitus and heart disease, and infectious diseases such as norovirus, the flu, and athlete's foot. Procedure classifications list procedure code, which are used to capture interventional data. These diagnosis and procedure codes are used by health care providers, government health programs, private health insurance companies, workers' compensation carriers, software developers, and others for a variety of applications in medicine, public health and medical informatics, including:
OpenGALEN is a not-for-profit organisation that provides an open source medical terminology. This terminology is written in a formal language called GRAIL and also distributed in OWL.
The Systematized Nomenclature of Medicine (SNOMED) is a systematic, computer-processable collection of medical terms, in human and veterinary medicine, to provide codes, terms, synonyms and definitions which cover anatomy, diseases, findings, procedures, microorganisms, substances, etc. It allows a consistent way to index, store, retrieve, and aggregate medical data across specialties and sites of care. Although now international, SNOMED was started in the U.S. by the College of American Pathologists (CAP) in 1973 and revised into the 1990s. In 2002 CAP's SNOMED Reference Terminology was merged with, and expanded by, the National Health Service's Clinical Terms Version 3 to produce SNOMED CT.
Biomedical text mining refers to the methods and study of how text mining may be applied to texts and literature of the biomedical domain. As a field of research, biomedical text mining incorporates ideas from natural language processing, bioinformatics, medical informatics and computational linguistics. The strategies in this field have been applied to the biomedical literature available through services such as PubMed.
Logical Observation Identifiers Names and Codes (LOINC) is a database and universal standard for identifying medical laboratory observations. First developed in 1994, it was created and is maintained by the Regenstrief Institute, a US nonprofit medical research organization. LOINC was created in response to the demand for an electronic clinical care and management database and is publicly available at no cost.

SNOMED CT or SNOMED Clinical Terms is a systematically organized computer-processable collection of medical terms providing codes, terms, synonyms and definitions used in clinical documentation and reporting. SNOMED CT is considered to be the most comprehensive, multilingual clinical healthcare terminology in the world. The primary purpose of SNOMED CT is to encode the meanings that are used in health information and to support the effective clinical recording of data with the aim of improving patient care. SNOMED CT provides the core general terminology for electronic health records. SNOMED CT comprehensive coverage includes: clinical findings, symptoms, diagnoses, procedures, body structures, organisms and other etiologies, substances, pharmaceuticals, devices and specimens.
The Diseases Database is a free website that provides information about the relationships between medical conditions, symptoms, and medications. The database is run by Medical Object Oriented Software Enterprises Ltd, a company based in London.
Medcin, is a system of standardized medical terminology, a proprietary medical vocabulary and was developed by Medicomp Systems, Inc. MEDCIN is a point-of-care terminology, intended for use in Electronic Health Record (EHR) systems, and it includes over 280,000 clinical data elements encompassing symptoms, history, physical examination, tests, diagnoses and therapy. This clinical vocabulary contains over 38 years of research and development as well as the capability to cross map to leading codification systems such as SNOMED CT, CPT, ICD-9-CM/ICD-10-CM, DSM, LOINC, CDT, CVX, and the Clinical Care Classification (CCC) System for nursing and allied health.
DeCS – Health Sciences Descriptors is a structured and trilingual thesaurus created by BIREME – Latin American and Caribbean Center on Health Sciences Information – in 1986 for indexing scientific journal articles, books, proceedings of congresses, technical reports and other types of materials, as well as for searching and recovering scientific information in LILACS, MEDLINE and other databases. In the VHL, Virtual Health Library, DeCS is the tool that permits the navigation between records and sources of information through controlled concepts and organized in Portuguese, Spanish and English.

Yves A. Lussier is a physician-scientist conducting research in Precision medicine, Translational bioinformatics and Personal Genomics. As a co-founder of Purkinje, he pioneered the commercial use of controlled medical vocabulary organized as directed semantic networks in electronic medical records, as well as Pen computing for clinicians.

NeuroLex is a lexicon of neuroscience concepts supported by the Neuroscience Information Framework project, which is funded by the NIH Blueprint for Neuroscience Research. It is the lexical part of the NIF knowledge base, and NeuroLex is intended to make literature review easier and ensure consistent terminology and usage across researchers for the topics of experimental, clinical, and transnational neuroscience, and for genetic and genomic resources. It is structured as a semantic wiki, using Semantic MediaWiki.
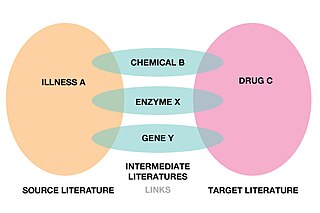
Literature-based discovery (LBD), also called literature-related discovery (LRD) is a form of knowledge extraction and automated hypothesis generation that uses papers and other academic publications to find new relationships between existing knowledge. Literature-based discovery aims to discover new knowledge by connecting information which have been explicitly stated in literature to deduce connections which have not been explicitly stated.
The Clinical Care Classification (CCC) System is a standardized, coded nursing terminology that identifies the discrete elements of nursing practice. The CCC provides a unique framework and coding structure. Used for documenting the plan of care; following the nursing process in all health care settings.
Apache cTAKES: clinical Text Analysis and Knowledge Extraction System is an open-source Natural Language Processing (NLP) system that extracts clinical information from electronic health record unstructured text. It processes clinical notes, identifying types of clinical named entities — drugs, diseases/disorders, signs/symptoms, anatomical sites and procedures. Each named entity has attributes for the text span, the ontology mapping code, context, and negated/not negated.
RxNorm is short for medical prescription normalized Medical prescription
Carol Friedman is a scientist and biomedical informatician. She is among the pioneers the use of expert systems in medical language processing and the explicit medical concept representation underpinning the use of entity–attribute–value modeling underpinning electronic medical records.
Translational bioinformatics (TBI) is a field that emerged in the 2010s to study health informatics, focused on the convergence of molecular bioinformatics, biostatistics, statistical genetics and clinical informatics. Its focus is on applying informatics methodology to the increasing amount of biomedical and genomic data to formulate knowledge and medical tools, which can be utilized by scientists, clinicians, and patients. Furthermore, it involves applying biomedical research to improve human health through the use of computer-based information system. TBI employs data mining and analyzing biomedical informatics in order to generate clinical knowledge for application. Clinical knowledge includes finding similarities in patient populations, interpreting biological information to suggest therapy treatments and predict health outcomes.

Betsy L. Humphreys is an American medical librarian and health informatician known for leading the cross-institutional efforts to establish biomedical terminology standards such as SNOMED CT and the Unified Medical Language System. She was the deputy director of the National Library of Medicine from 2005 until her retirement in 2017, serving as acting director from 2015 to 2016.
References
- ↑ Unified Medical Language System, 1996
- ↑ Ellison D, Humphreys BL, Mitchell J (July 2010). "Presentation of the 2009 Morris F Collen Award to Betsy L Humphreys, with remarks from the recipient". Journal of the American Medical Informatics Association. 17 (4): 481–5. doi:10.1136/jamia.2010.005728. PMC 2995660 . PMID 20595319.
- 1 2 National Library of Medicine (2009). "Chapter 5 - Semantic Networks". UMLS Reference Manual. Bethesda, MD: U.S. National Library of Medicine, National Institutes of Health.
- ↑ Browne AC, McCray AT, Srinivasan S (June 2000). The Specialist Lexicon (PDF). Bethesda, MD: Lister Hill National Center for Biomedical Communications, National Library of Medicine. p. 1.
- ↑ Morrey CP, Geller J, Halper M, Perl Y (June 2009). "The Neighborhood Auditing Tool: a hybrid interface for auditing the UMLS". Journal of Biomedical Informatics. 42 (3): 468–89. doi:10.1016/j.jbi.2009.01.006. PMC 2891659 . PMID 19475725.
- ↑ Geller J, Morrey CP, Xu J, Halper M, Elhanan G, Perl Y, Hripcsak G (November 2009). "Comparing inconsistent relationship configurations indicating UMLS errors". AMIA ... Annual Symposium Proceedings. AMIA Symposium. 2009: 193–7. PMC 2815406 . PMID 20351848.
- ↑ Zhu X, Fan JW, Baorto DM, Weng C, Cimino JJ (June 2009). "A review of auditing methods applied to the content of controlled biomedical terminologies". Journal of Biomedical Informatics. 42 (3): 413–25. doi:10.1016/j.jbi.2009.03.003. PMC 3505841 . PMID 19285571.
- ↑ "Unified Medical Language System® (UMLS®) News: Revised License Agreement, New UMLS Terminology Services and Browser, Discontinued UMLSKS, and API Changes". NLM Technical Bulletin (375): e9. Jul–Aug 2010.