
An object database or object-oriented database is a database management system in which information is represented in the form of objects as used in object-oriented programming. Object databases are different from relational databases which are table-oriented. Object–relational databases are a hybrid of both approaches.
SQL is a domain-specific language used in programming and designed for managing data held in a relational database management system (RDBMS), or for stream processing in a relational data stream management system (RDSMS). It is particularly useful in handling structured data, i.e. data incorporating relations among entities and variables.

Db2 is a family of data management products, including database servers, developed by IBM. They initially supported the relational model, but were extended to support object–relational features and non-relational structures like JSON and XML. The brand name was originally styled as DB/2, then DB2 until 2017 and finally changed to its present form.
Query languages, data query languages or database query languages (DQLs) are computer languages used to make queries in databases and information systems. A well known example is the Structured Query Language (SQL).
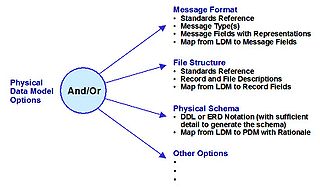
A physical data model is a representation of a data design as implemented, or intended to be implemented, in a database management system. In the lifecycle of a project it typically derives from a logical data model, though it may be reverse-engineered from a given database implementation. A complete physical data model will include all the database artifacts required to create relationships between tables or to achieve performance goals, such as indexes, constraint definitions, linking tables, partitioned tables or clusters. Analysts can usually use a physical data model to calculate storage estimates; it may include specific storage allocation details for a given database system.
A temporal database stores data relating to time instances. It offers temporal data types and stores information relating to past, present and future time. Temporal databases could be uni-temporal, bi-temporal or tri-temporal.
A database trigger is procedural code that is automatically executed in response to certain events on a particular table or view in a database. The trigger is mostly used for maintaining the integrity of the information on the database. For example, when a new record is added to the employees table, new records should also be created in the tables of the taxes, vacations and salaries. Triggers can also be used to log historical data, for example to keep track of employees' previous salaries.
The following tables compare general and technical information for a number of relational database management systems. Please see the individual products' articles for further information. Unless otherwise specified in footnotes, comparisons are based on the stable versions without any add-ons, extensions or external programs.
In relational databases, the information schema is an ANSI-standard set of read-only views that provide information about all of the tables, views, columns, and procedures in a database. It can be used as a source of the information that some databases make available through non-standard commands, such as:
=> SELECT count(table_name) FROM information_schema.tables; count ------- 99 => SELECT column_name, data_type, column_default, is_nullable FROM information_schema.columns WHERE table_name='alpha'; column_name | data_type | column_default | is_nullable -------------+-----------+----------------+------------- foo | integer | | YES bar | character | | YES => SELECT * FROM information_schema.information_schema_catalog_name; catalog_name -------------- johnd
SQL/XML or XML-Related Specifications is part 14 of the Structured Query Language (SQL) specification. In addition to the traditional predefined SQL data types like NUMERIC, CHAR, TIMESTAMP, ... it introduces the predefined data type XML together with constructors, several routines, functions, and XML-to-SQL data type mappings to support manipulation and storage of XML in a SQL database.
XQuery Update Facility is an extension to the XML Query language, XQuery. It provides expressions that can be used to make changes to instances of the XQuery 1.0 and XPath 2.0 Data Model.
SQL:1999 was the fourth revision of the SQL database query language. It introduced many new features, many of which required clarifications in the subsequent SQL:2003. In the meanwhile SQL:1999 is deprecated.
XPath is an expression language designed to support the query or transformation of XML documents. It was defined by the World Wide Web Consortium (W3C) and can be used to compute values from the content of an XML document. Support for XPath exists in applications that support XML, such as web browsers, and many programming languages.
pureXML is the native XML storage feature in the IBM Db2 data server. pureXML provides query languages, storage technologies, indexing technologies, and other features to support XML data. The word pure in pureXML was chosen to indicate that Db2 natively stores and natively processes XML data in its inherent hierarchical structure, as opposed to treating XML data as plain text or converting it into a relational format.
XQuery is a query and functional programming language that queries and transforms collections of structured and unstructured data, usually in the form of XML, text and with vendor-specific extensions for other data formats. The language is developed by the XML Query working group of the W3C. The work is closely coordinated with the development of XSLT by the XSL Working Group; the two groups share responsibility for XPath, which is a subset of XQuery.

DatabaseSpy is a multi-database query, design, and database comparison tool from Altova, the creator of XMLSpy. DatabaseSpy connects to many major relational databases, facilitating SQL querying, database structure design, database content editing, and database comparison and conversion.
Sedna is an open-source database management system that provides native storage for XML data. The distinctive design decisions employed in Sedna are (i) schema-based clustering storage strategy for XML data and (ii) memory management based on layered address space.

XQuery API for Java (XQJ) refers to the common Java API for the W3C XQuery 1.0 specification.
SQL:2011 or ISO/IEC 9075:2011 is the seventh revision of the ISO (1987) and ANSI (1986) standard for the SQL database query language. It was formally adopted in December 2011. The standard consists of 9 parts which are described in detail in SQL. The next version is SQL:2016.
JSONiq is a query and functional programming language that is designed to declaratively query and transform collections of hierarchical and heterogeneous data in format of JSON, XML, as well as unstructured, textual data.