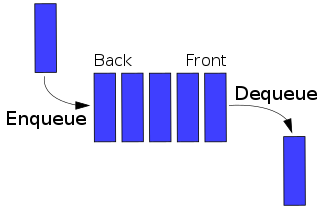
In computing and in systems theory, first in, first out, acronymized as FIFO, is a method for organizing the manipulation of a data structure where the oldest (first) entry, or "head" of the queue, is processed first.
In computer science, reference counting is a programming technique of storing the number of references, pointers, or handles to a resource, such as an object, a block of memory, disk space, and others.
In computer science, threaded code is a programming technique where the code has a form that essentially consists entirely of calls to subroutines. It is often used in compilers, which may generate code in that form or be implemented in that form themselves. The code may be processed by an interpreter or it may simply be a sequence of machine code call instructions.
x86 assembly language is the name for the family of assembly languages which provide some level of backward compatibility with CPUs back to the Intel 8008 microprocessor, which was launched in April 1972. It is used to produce object code for the x86 class of processors.
In computer programming, a weak reference is a reference that does not protect the referenced object from collection by a garbage collector, unlike a strong reference. An object referenced only by weak references – meaning "every chain of references that reaches the object includes at least one weak reference as a link" – is considered weakly reachable, and can be treated as unreachable and so may be collected at any time. Some garbage-collected languages feature or support various levels of weak references, such as C#, Java, Lisp, OCaml, Perl, Python and PHP since the version 7.4.
In software engineering, a spinlock is a lock that causes a thread trying to acquire it to simply wait in a loop ("spin") while repeatedly checking whether the lock is available. Since the thread remains active but is not performing a useful task, the use of such a lock is a kind of busy waiting. Once acquired, spinlocks will usually be held until they are explicitly released, although in some implementations they may be automatically released if the thread being waited on blocks or "goes to sleep".
In computer science, read-copy-update (RCU) is a synchronization mechanism that avoids the use of lock primitives while multiple threads concurrently read and update elements that are linked through pointers and that belong to shared data structures.
In computer science, a smart pointer is an abstract data type that simulates a pointer while providing added features, such as automatic memory management or bounds checking. Such features are intended to reduce bugs caused by the misuse of pointers, while retaining efficiency. Smart pointers typically keep track of the memory they point to, and may also be used to manage other resources, such as network connections and file handles. Smart pointers were first popularized in the programming language C++ during the first half of the 1990s as rebuttal to criticisms of C++'s lack of automatic garbage collection.
C dynamic memory allocation refers to performing manual memory management for dynamic memory allocation in the C programming language via a group of functions in the C standard library, namely malloc, realloc, calloc, aligned_alloc and free.
In computer science, the test-and-set instruction is an instruction used to write (set) 1 to a memory location and return its old value as a single atomic operation. The caller can then "test" the result to see if the state was changed by the call. If multiple processes may access the same memory location, and if a process is currently performing a test-and-set, no other process may begin another test-and-set until the first process's test-and-set is finished. A central processing unit (CPU) may use a test-and-set instruction offered by another electronic component, such as dual-port RAM; a CPU itself may also offer a test-and-set instruction.
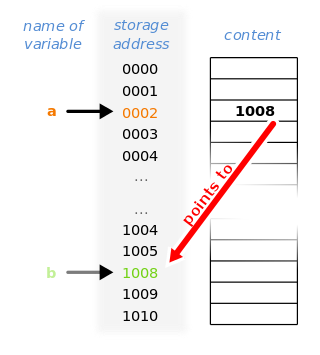
In computer science, a pointer is an object in many programming languages that stores a memory address. This can be that of another value located in computer memory, or in some cases, that of memory-mapped computer hardware. A pointer references a location in memory, and obtaining the value stored at that location is known as dereferencing the pointer. As an analogy, a page number in a book's index could be considered a pointer to the corresponding page; dereferencing such a pointer would be done by flipping to the page with the given page number and reading the text found on that page. The actual format and content of a pointer variable is dependent on the underlying computer architecture.
In computer science, compare-and-swap (CAS) is an atomic instruction used in multithreading to achieve synchronization. It compares the contents of a memory location with a given value and, only if they are the same, modifies the contents of that memory location to a new given value. This is done as a single atomic operation. The atomicity guarantees that the new value is calculated based on up-to-date information; if the value had been updated by another thread in the meantime, the write would fail. The result of the operation must indicate whether it performed the substitution; this can be done either with a simple boolean response, or by returning the value read from the memory location.

In concurrent programming, an operation is linearizable if it consists of an ordered list of invocation and response events, that may be extended by adding response events such that:
- The extended list can be re-expressed as a sequential history.
- That sequential history is a subset of the original unextended list.
In a multithreaded computing environment, hazard pointers are one approach to solving the problems posed by dynamic memory management of the nodes in a lock-free data structure. These problems generally arise only in environments that don't have automatic garbage collection.
In computer science, load-linked/store-conditional (LL/SC), sometimes known as load-reserved/store-conditional (LR/SC), are a pair of instructions used in multithreading to achieve synchronization. Load-link returns the current value of a memory location, while a subsequent store-conditional to the same memory location will store a new value only if no updates have occurred to that location since the load-link. Together, this implements a lock-free, atomic, read-modify-write operation.
In computer science, read–modify–write is a class of atomic operations that both read a memory location and write a new value into it simultaneously, either with a completely new value or some function of the previous value. These operations prevent race conditions in multi-threaded applications. Typically they are used to implement mutexes or semaphores. These atomic operations are also heavily used in non-blocking synchronization.
A concurrent hash-trie or Ctrie is a concurrent thread-safe lock-free implementation of a hash array mapped trie. It is used to implement the concurrent map abstraction. It has particularly scalable concurrent insert and remove operations and is memory-efficient. It is the first known concurrent data-structure that supports O(1), atomic, lock-free snapshots.
In computer science, persistent memory is any method or apparatus for efficiently storing data structures such that they can continue to be accessed using memory instructions or memory APIs even after the end of the process that created or last modified them.
A non-blocking linked list is an example of non-blocking data structures designed to implement a linked list in shared memory using synchronization primitives:
The Java programming language's Java Collections Framework version 1.5 and later defines and implements the original regular single-threaded Maps, and also new thread-safe Maps implementing the java.util.concurrent.ConcurrentMap interface among other concurrent interfaces. In Java 1.6, the java.util.NavigableMap interface was added, extending java.util.SortedMap, and the java.util.concurrent.ConcurrentNavigableMap interface was added as a subinterface combination.

