In logic, mathematics, computer science, and linguistics, a formal language consists of words whose letters are taken from an alphabet and are well-formed according to a specific set of rules.
Machine translation, sometimes referred to by the abbreviation MT, is a sub-field of computational linguistics that investigates the use of software to translate text or speech from one language to another.

Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.
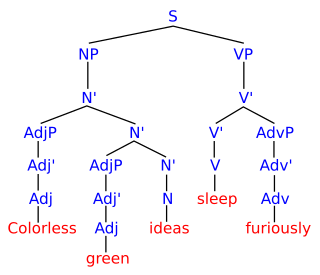
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part.

In statistics, an expectation–maximization (EM) algorithm is an iterative method to find (local) maximum likelihood or maximum a posteriori (MAP) estimates of parameters in statistical models, where the model depends on unobserved latent variables. The EM iteration alternates between performing an expectation (E) step, which creates a function for the expectation of the log-likelihood evaluated using the current estimate for the parameters, and a maximization (M) step, which computes parameters maximizing the expected log-likelihood found on the E step. These parameter-estimates are then used to determine the distribution of the latent variables in the next E step.
Automatic summarization is the process of shortening a set of data computationally, to create a subset that represents the most important or relevant information within the original content.

Machine translation can use a method based on dictionary entries, which means that the words will be translated as a dictionary does – word by word, usually without much correlation of meaning between them. Dictionary lookups may be done with or without morphological analysis or lemmatisation. While this approach to machine translation is probably the least sophisticated, dictionary-based machine translation is ideally suitable for the translation of long lists of phrases on the subsentential level, e.g. inventories or simple catalogs of products and services.

In the fields of computational linguistics and probability, an n-gram is a contiguous sequence of n items from a given sample of text or speech. The items can be phonemes, syllables, letters, words or base pairs according to the application. The n-grams typically are collected from a text or speech corpus. When the items are words, n-grams may also be called shingles.
Speech segmentation is the process of identifying the boundaries between words, syllables, or phonemes in spoken natural languages. The term applies both to the mental processes used by humans, and to artificial processes of natural language processing.
Statistical machine translation (SMT) is a machine translation paradigm where translations are generated on the basis of statistical models whose parameters are derived from the analysis of bilingual text corpora. The statistical approach contrasts with the rule-based approaches to machine translation as well as with example-based machine translation.
Moses is a free software, statistical machine translation engine that can be used to train statistical models of text translation from a source language to a target language. Moses then allows new source-language text to be decoded using these models to produce automatic translations in the target language. Training requires a parallel corpus of passages in the two languages, typically manually translated sentence pairs. Moses is released under the LGPL licence and available both as source code and binaries for Windows and Linux. Its development is primarily supported by the EuroMatrix project, with funding by the European Commission.

Transfer-based machine translation is a type of machine translation (MT). It is currently one of the most widely used methods of machine translation. In contrast to the simpler direct model of MT, transfer MT breaks translation into three steps: analysis of the source language text to determine its grammatical structure, transfer of the resulting structure to a structure suitable for generating text in the target language, and finally generation of this text. Transfer-based MT systems are thus capable of using knowledge of the source and target languages.
Machine translation (MT) algorithms may be classified by their operating principle. MT may be based on a set of linguistic rules, or on large bodies (corpora) of already existing parallel texts. Rule-based methodologies may consist in a direct word-by-word translation, or operate via a more abstract representation of meaning: a representation either specific to the language pair, or a language-independent interlingua. Corpora-based methodologies rely on machine learning and may follow specific examples taken from the parallel texts, or may calculate statistical probabilities to select a preferred option out of all possible translations.

Word2vec is a technique for natural language processing published in 2013. The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. As the name implies, word2vec represents each distinct word with a particular list of numbers called a vector. The vectors are chosen carefully such that a simple mathematical function indicates the level of semantic similarity between the words represented by those vectors.
Neural machine translation (NMT) is an approach to machine translation that uses an artificial neural network to predict the likelihood of a sequence of words, typically modeling entire sentences in a single integrated model.
IBM alignment models are a sequence of increasingly complex models used in statistical machine translation to train a translation model and an alignment model, starting with lexical translation probabilities and moving to reordering and word duplication. They underpinned the majority of statistical machine translation systems for almost twenty years starting in the early 1990s, until neural machine translation began to dominate. These models offer principled probabilistic formulation and (mostly) tractable inference.
UBY is a large-scale lexical-semantic resource for natural language processing (NLP) developed at the Ubiquitous Knowledge Processing Lab (UKP) in the department of Computer Science of the Technische Universität Darmstadt . UBY is based on the ISO standard Lexical Markup Framework (LMF) and combines information from several expert-constructed and collaboratively constructed resources for English and German.
The following outline is provided as an overview of and topical guide to machine learning. Machine learning is a subfield of soft computing within computer science that evolved from the study of pattern recognition and computational learning theory in artificial intelligence. In 1959, Arthur Samuel defined machine learning as a "field of study that gives computers the ability to learn without being explicitly programmed". Machine learning explores the study and construction of algorithms that can learn from and make predictions on data. Such algorithms operate by building a model from an example training set of input observations in order to make data-driven predictions or decisions expressed as outputs, rather than following strictly static program instructions.
A confusion network is a natural language processing method that combines outputs from multiple automatic speech recognition or machine translation systems. Confusion networks are simple linear directed acyclic graphs with the property that each a path from the start node to the end node goes through all the other nodes. The set of words represented by edges between two nodes is called a confusion set. In machine translation, the defining characteristic of confusion networks is that they allow multiple ambiguous inputs, deferring committal translation decisions until later stages of processing. This approach is used in the open source machine translation software Moses and the proprietary translation API in IBM Bluemix Watson.
Paraphrase or paraphrasing in computational linguistics is the natural language processing task of detecting and generating paraphrases. Applications of paraphrasing are varied including information retrieval, question answering, text summarization, and plagiarism detection. Paraphrasing is also useful in the evaluation of machine translation, as well as semantic parsing and generation of new samples to expand existing corpora.


