In computing, a cache is a hardware or software component that stores data so that future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation or a copy of data stored elsewhere. A cache hit occurs when the requested data can be found in a cache, while a cache miss occurs when it cannot. Cache hits are served by reading data from the cache, which is faster than recomputing a result or reading from a slower data store; thus, the more requests that can be served from the cache, the faster the system performs.
In computer science, locality of reference, also known as the principle of locality, is the tendency of a processor to access the same set of memory locations repetitively over a short period of time. There are two basic types of reference locality – temporal and spatial locality. Temporal locality refers to the reuse of specific data and/or resources within a relatively small time duration. Spatial locality refers to the use of data elements within relatively close storage locations. Sequential locality, a special case of spatial locality, occurs when data elements are arranged and accessed linearly, such as traversing the elements in a one-dimensional array.

Duron is a line of budget x86-compatible microprocessors manufactured by AMD and released on June 19, 2000. Duron was intended to be a lower-cost offering to complement AMD's then mainstream performance Athlon processor line, and it also competed with rival chipmaker Intel's Pentium III and Celeron processor offerings. The Duron brand name was retired in 2004, succeeded by the AMD's Sempron line of processors as their budget offering.

The Athlon 64 is a ninth-generation, AMD64-architecture microprocessor produced by Advanced Micro Devices (AMD), released on September 23, 2003. It is the third processor to bear the name Athlon, and the immediate successor to the Athlon XP. The Athlon 64 was the second processor to implement the AMD64 architecture and the first 64-bit processor targeted at the average consumer. Variants of the Athlon 64 have been produced for Socket 754, Socket 939, Socket 940, and Socket AM2. It was AMD's primary consumer CPU, and primarily competed with Intel's Pentium 4, especially the Prescott and Cedar Mill core revisions.
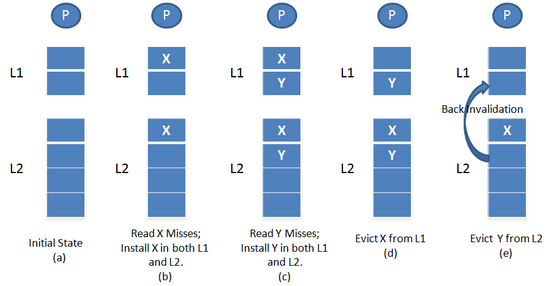
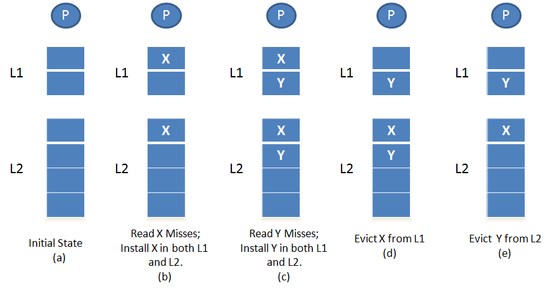
The MESI protocol is an Invalidate-based cache coherence protocol, and is one of the most common protocols that support write-back caches. It is also known as the Illinois protocol due to its development at the University of Illinois at Urbana-Champaign. Write back caches can save considerable bandwidth generally wasted on a write through cache. There is always a dirty state present in write back caches that indicates that the data in the cache is different from that in main memory. The Illinois Protocol requires a cache to cache transfer on a miss if the block resides in another cache. This protocol reduces the number of main memory transactions with respect to the MSI protocol. This marks a significant improvement in performance.
A CPU cache is a hardware cache used by the central processing unit (CPU) of a computer to reduce the average cost to access data from the main memory. A cache is a smaller, faster memory, located closer to a processor core, which stores copies of the data from frequently used main memory locations. Most CPUs have a hierarchy of multiple cache levels, with different instruction-specific and data-specific caches at level 1. The cache memory is typically implemented with static random-access memory (SRAM), in modern CPUs by far the largest part of them by chip area, but SRAM is not always used for all levels, or even any level, sometimes some latter or all levels are implemented with eDRAM.
In computing, the MSI protocol - a basic cache-coherence protocol - operates in multiprocessor systems. As with other cache coherency protocols, the letters of the protocol name identify the possible states in which a cache line can be.
The MOSI protocol is an extension of the basic MSI cache coherency protocol. It adds the Owned state, which indicates that the current processor owns this block, and will service requests from other processors for the block.
In computing, a cache-oblivious algorithm is an algorithm designed to take advantage of a processor cache without having the size of the cache as an explicit parameter. An optimal cache-oblivious algorithm is a cache-oblivious algorithm that uses the cache optimally. Thus, a cache-oblivious algorithm is designed to perform well, without modification, on multiple machines with different cache sizes, or for a memory hierarchy with different levels of cache having different sizes. Cache-oblivious algorithms are contrasted with explicit loop tiling, which explicitly breaks a problem into blocks that are optimally sized for a given cache.
Cache pollution describes situations where an executing computer program loads data into CPU cache unnecessarily, thus causing other useful data to be evicted from the cache into lower levels of the memory hierarchy, degrading performance. For example, in a multi-core processor, one core may replace the blocks fetched by other cores into shared cache, or prefetched blocks may replace demand-fetched blocks from the cache.
Adaptive Replacement Cache (ARC) is a page replacement algorithm with better performance than LRU. This is accomplished by keeping track of both frequently used and recently used pages plus a recent eviction history for both. The algorithm was developed at the IBM Almaden Research Center. In 2006, IBM was granted a patent for the adaptive replacement cache policy.
The Firefly cache coherence protocol is the schema used in the DEC Firefly multiprocessor workstation, developed by DEC Systems Research Center. This protocol is a 3 State Write Update Cache Coherence Protocol. Unlike the Dragon protocol, the Firefly protocol updates the Main Memory as well as the Local caches on Write Update Bus Transition. Thus the Shared Clean and Shared Modified States present in case of Dragon Protocol, are not distinguished between in case of Firefly Protocol.
The Dragon Protocol is an update based cache coherence protocol used in multi-processor systems. Write propagation is performed by directly updating all the cached values across multiple processors. Update based protocols such as the Dragon protocol perform efficiently when a write to a cache block is followed by several reads made by other processors, since the updated cache block is readily available across caches associated with all the processors.
The SPARC64 V (Zeus) is a SPARC V9 microprocessor designed by Fujitsu. The SPARC64 V was the basis for a series of successive processors designed for servers, and later, supercomputers.
A thread block is a programming abstraction that represents a group of threads that can be executed serially or in parallel. For better process and data mapping, threads are grouped into thread blocks. The number of threads in a thread block was formerly limited by the architecture to a total of 512 threads per block, but as of March 2010, with compute capability 2.x and higher, blocks may contain up to 1024 threads. The threads in the same thread block run on the same stream processor. Threads in the same block can communicate with each other via shared memory, barrier synchronization or other synchronization primitives such as atomic operations.

In computer architecture, a trace cache or execution trace cache is a specialized instruction cache which stores the dynamic stream of instructions known as trace. It helps in increasing the instruction fetch bandwidth and decreasing power consumption by storing traces of instructions that have already been fetched and decoded. A trace processor is an architecture designed around the trace cache and processes the instructions at trace level granularity. The formal mathematical theory of traces is described by trace monoids.
Cache placement policies are policies that determine where a particular memory block can be placed when it goes into a CPU cache. A block of memory cannot necessarily be placed at an arbitrary location in the cache; it may be restricted to a particular cache line or a set of cache lines by the cache's placement policy.

Cache hierarchy, or multi-level cache, is a memory architecture that uses a hierarchy of memory stores based on varying access speeds to cache data. Highly requested data is cached in high-speed access memory stores, allowing swifter access by central processing unit (CPU) cores.
A CPU cache is a piece of hardware that reduces access time to data in memory by keeping some part of the frequently used data of the main memory in a 'cache' of smaller and faster memory.
A victim cache is a small, usually fully associative cache placed in the refill path of a CPU cache that stores all the blocks evicted from that level of cache, originally proposed in 1990. In modern architectures, this function is typically performed by Level 3 or Level 4 caches.