Local store exploitation
Transferring data between the local stores of different SPUs can have a large performance cost. The local stores of individual SPUs can be exploited using a variety of strategies.
Applications with high locality, such as dense matrix computations, represent an ideal workload class for the local stores in Cell BE. [5]
Streaming computations can be efficiently accommodated using software pipelining of memory block transfers using a multi-buffering strategy. [1]
The software cache offers a solution for random accesses. [6]
More sophisticated applications can use multiple strategies for different data types. [7]
Related Research Articles

A central processing unit (CPU), also called a central processor, main processor or just processor, is the electronic circuitry that executes instructions comprising a computer program. The CPU performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
MIPS is a reduced instruction set computer (RISC) instruction set architecture (ISA) developed by MIPS Computer Systems, now MIPS Technologies, based in the United States.

x86 is a family of instruction set architectures initially developed by Intel based on the Intel 8086 microprocessor and its 8088 variant. The 8086 was introduced in 1978 as a fully 16-bit extension of Intel's 8-bit 8080 microprocessor, with memory segmentation as a solution for addressing more memory than can be covered by a plain 16-bit address. The term "x86" came into being because the names of several successors to Intel's 8086 processor end in "86", including the 80186, 80286, 80386 and 80486 processors.
In computer science, an instruction set architecture (ISA), also called computer architecture, is an abstract model of a computer. A device that executes instructions described by that ISA, such as a central processing unit (CPU), is called an implementation.
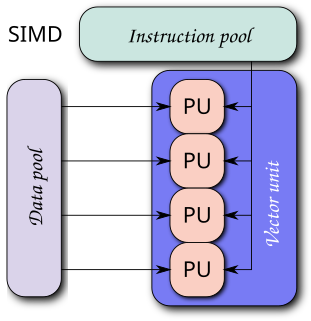
Single instruction, multiple data (SIMD) is a type of parallel processing in Flynn's taxonomy. SIMD can be internal and it can be directly accessible through an instruction set architecture (ISA): it should not be confused with an ISA. SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously.
AltiVec is a single-precision floating point and integer SIMD instruction set designed and owned by Apple, IBM, and Freescale Semiconductor — the AIM alliance. It is implemented on versions of the PowerPC processor architecture, including Motorola's G4, IBM's G5 and POWER6 processors, and P.A. Semi's PWRficient PA6T. AltiVec is a trademark owned solely by Freescale, so the system is also referred to as Velocity Engine by Apple and VMX by IBM and P.A. Semi.

MMX is a single instruction, multiple data (SIMD) instruction set architecture designed by Intel, introduced on January 8, 1997 with its Pentium P5 (microarchitecture) based line of microprocessors, named "Pentium with MMX Technology". It developed out of a similar unit introduced on the Intel i860, and earlier the Intel i750 video pixel processor. MMX is a processor supplementary capability that is supported on IA-32 processors by Intel and other vendors as of 1997.

A coprocessor is a computer processor used to supplement the functions of the primary processor. Operations performed by the coprocessor may be floating point arithmetic, graphics, signal processing, string processing, cryptography or I/O interfacing with peripheral devices. By offloading processor-intensive tasks from the main processor, coprocessors can accelerate system performance. Coprocessors allow a line of computers to be customized, so that customers who do not need the extra performance do not need to pay for it.
In computer science, computer engineering and programming language implementations, a stack machine is a computer processor or a virtual machine in which the primary interaction is moving short-lived temporary values to and from a push down stack. In the case of a hardware processor, a hardware stack is used. The use of a stack significantly reduces the required number of processor registers. Stack machines extend push-down automaton with additional load/store operations or multiple stacks and hence are Turing-complete.
Cell is a multi-core microprocessor microarchitecture that combines a general-purpose PowerPC core of modest performance with streamlined coprocessing elements which greatly accelerate multimedia and vector processing applications, as well as many other forms of dedicated computation.

The Intel 8087, announced in 1980, was the first x87 floating-point coprocessor for the 8086 line of microprocessors.
In computer engineering, out-of-order execution is a paradigm used in most high-performance central processing units to make use of instruction cycles that would otherwise be wasted. In this paradigm, a processor executes instructions in an order governed by the availability of input data and execution units, rather than by their original order in a program. In doing so, the processor can avoid being idle while waiting for the preceding instruction to complete and can, in the meantime, process the next instructions that are able to run immediately and independently.
In computer software, in compiler theory, an intrinsic function is a function (subroutine) available for use in a given programming language whose implementation is handled specially by the compiler. Typically, it may substitute a sequence of automatically generated instructions for the original function call, similar to an inline function. Unlike an inline function, the compiler has an intimate knowledge of an intrinsic function and can thus better integrate and optimize it for a given situation.
x87 is a floating-point-related subset of the x86 architecture instruction set. It originated as an extension of the 8086 instruction set in the form of optional floating-point coprocessors that worked in tandem with corresponding x86 CPUs. These microchips had names ending in "87". This was also known as the NPX. Like other extensions to the basic instruction set, x87 instructions are not strictly needed to construct working programs, but provide hardware and microcode implementations of common numerical tasks, allowing these tasks to be performed much faster than corresponding machine code routines can. The x87 instruction set includes instructions for basic floating-point operations such as addition, subtraction and comparison, but also for more complex numerical operations, such as the computation of the tangent function and its inverse, for example.
Stream processing is a computer programming paradigm, equivalent to dataflow programming, event stream processing, and reactive programming, that allows some applications to more easily exploit a limited form of parallel processing. Such applications can use multiple computational units, such as the floating point unit on a graphics processing unit or field-programmable gate arrays (FPGAs), without explicitly managing allocation, synchronization, or communication among those units.
The first commercial Cell microprocessor, the Cell BE, was designed for the Sony PlayStation 3. IBM designed the PowerXCell 8i for use in the Roadrunner supercomputer.
Stream Processors, Inc was a Silicon Valley-based fabless semiconductor company specializing in the design and manufacture of high-performance digital signal processors for applications including video surveillance, multi-function printers and video conferencing. The company ceased operations in 2009.
Advanced Vector Extensions are extensions to the x86 instruction set architecture for microprocessors from Intel and AMD proposed by Intel in March 2008 and first supported by Intel with the Sandy Bridge processor shipping in Q1 2011 and later on by AMD with the Bulldozer processor shipping in Q3 2011. AVX provides new features, new instructions and a new coding scheme.
The Power Processing Element (PPE) comprises a Power Processing Unit (PPU) and a 512 KB L2 cache. In most instances the PPU is used in a PPE. The PPU is a 64-bit dual-threaded in-order PowerPC 2.02 microprocessor core designed by IBM for use primarily in the game consoles PlayStation 3 and Xbox 360, but has also found applications in high performance computing in supercomputers such as the record setting IBM Roadrunner.
Heterogeneous computing refers to systems that use more than one kind of processor or cores. These systems gain performance or energy efficiency not just by adding the same type of processors, but by adding dissimilar coprocessors, usually incorporating specialized processing capabilities to handle particular tasks.
References
- The Cell Project at IBM Research
- Optimizing Compiler for a CELL Processor
- Using advanced compiler technology to exploit the performance of the Cell Broadband Engine architecture
- Compiler Technology for Scalable Architectures
- 1 2 "An Open Source Environment for Cell Broadband Engine System Software" (PDF). June 2007.
- ↑ IBM Research Project - Compiler Technology for Scalable Architectures
- ↑ IBM Systems Journal - Using advanced compiler technology to exploit the performance of the Cell Broadband Engine architecture, 2017-10-23, archived from the original on 2006-04-11
- ↑ IBM's Octopiler, or, why the PS3 is running late, ArsTechnica, 2006-02-26
- ↑ "Synergistic Processing in Cell's Multicore Architecture" (PDF). March 2006.
- ↑ "Using advanced compiler technology to exploit the performance of the Cell Broadband Engine architecture" (PDF). January 2006.
- ↑ "Cell GC: Using the Cell Synergistic Processor as a Garbage Collection Coprocessor" (PDF). March 2008.