Related Research Articles

A central processing unit (CPU), also called a central processor, main processor or just processor, is the electronic circuitry that executes instructions comprising a computer program. The CPU performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).

The Harvard architecture is a computer architecture with separate storage and signal pathways for instructions and data. It contrasts with the von Neumann architecture, where program instructions and data share the same memory and pathways.

The program counter (PC), commonly called the instruction pointer (IP) in Intel x86 and Itanium microprocessors, and sometimes called the instruction address register (IAR), the instruction counter, or just part of the instruction sequencer, is a processor register that indicates where a computer is in its program sequence.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
A one-instruction set computer (OISC), sometimes called an ultimate reduced instruction set computer (URISC), is an abstract machine that uses only one instruction – obviating the need for a machine language opcode. With a judicious choice for the single instruction and given infinite resources, an OISC is capable of being a universal computer in the same manner as traditional computers that have multiple instructions. OISCs have been recommended as aids in teaching computer architecture and have been used as computational models in structural computing research. The first carbon nanotube computer is a 1-bit one-instruction set computer.

Content-addressable memory (CAM) is a special type of computer memory used in certain very-high-speed searching applications. It is also known as associative memory or associative storage and compares input search data against a table of stored data, and returns the address of matching data.
In parallel computer architectures, a systolic array is a homogeneous network of tightly coupled data processing units (DPUs) called cells or nodes. Each node or DPU independently computes a partial result as a function of the data received from its upstream neighbours, stores the result within itself and passes it downstream. Systolic arrays were first used in Colossus, which was an early computer used to break German Lorenz ciphers during World War II. Due to the classified nature of Colossus, they were independently invented or rediscovered by H. T. Kung and Charles Leiserson who described arrays for many dense linear algebra computations for banded matrices. Early applications include computing greatest common divisors of integers and polynomials. They are sometimes classified as multiple-instruction single-data (MISD) architectures under Flynn's taxonomy, but this classification is questionable because a strong argument can be made to distinguish systolic arrays from any of Flynn's four categories: SISD, SIMD, MISD, MIMD, as discussed later in this article.
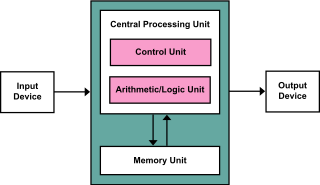
The von Neumann architecture — also known as the von Neumann model or Princeton architecture — is a computer architecture based on a 1945 description by John von Neumann, and by others, in the First Draft of a Report on the EDVAC. The document describes a design architecture for an electronic digital computer with these components:
A processor register is a quickly accessible location available to a computer's processor. Registers usually consist of a small amount of fast storage, although some registers have specific hardware functions, and may be read-only or write-only. In computer architecture, registers are typically addressed by mechanisms other than main memory, but may in some cases be assigned a memory address e.g. DEC PDP-10, ICT 1900.
A translation lookaside buffer (TLB) is a memory cache that stores the recent translations of virtual memory to physical memory. It is used to reduce the time taken to access a user memory location. It can be called an address-translation cache. It is a part of the chip's memory-management unit (MMU). A TLB may reside between the CPU and the CPU cache, between CPU cache and the main memory or between the different levels of the multi-level cache. The majority of desktop, laptop, and server processors include one or more TLBs in the memory-management hardware, and it is nearly always present in any processor that utilizes paged or segmented virtual memory.
The First Draft of a Report on the EDVAC is an incomplete 101-page document written by John von Neumann and distributed on June 30, 1945 by Herman Goldstine, security officer on the classified ENIAC project. It contains the first published description of the logical design of a computer using the stored-program concept, which has controversially come to be known as the von Neumann architecture.
A von Neumann language is any of those programming languages that are high-level abstract isomorphic copies of von Neumann architectures. As of 2009, most current programming languages fit into this description, likely as a consequence of the extensive domination of the von Neumann computer architecture during the past 50 years.

In computing, single instruction stream, single data stream (SISD) is a computer architecture in which a single uni-core processor executes a single instruction stream, to operate on data stored in a single memory. This corresponds to the von Neumann architecture.
Dataflow architecture is a computer architecture that directly contrasts the traditional von Neumann architecture or control flow architecture. Dataflow architectures have no program counter, in concept: the executability and execution of instructions is solely determined based on the availability of input arguments to the instructions, so that the order of instruction execution is unpredictable, i.e., behavior is nondeterministic.
Hardware acceleration is the use of computer hardware designed to perform specific functions more efficiently when compared to software running on a general-purpose central processing unit (CPU). Any transformation of data that can be calculated in software running on a generic CPU can also be calculated in custom-made hardware, or in some mix of both.

Binary Modular Dataflow Machine (BMDFM) is a software package that enables running an application in parallel on shared memory symmetric multiprocessing (SMP) computers using the multiple processors to speed up the execution of single applications. BMDFM automatically identifies and exploits parallelism due to the static and mainly dynamic scheduling of the dataflow instruction sequences derived from the formerly sequential program.

The history of computer science began long before our modern discipline of computer science, usually appearing in forms like mathematics or physics. Developments in previous centuries alluded to the discipline that we now know as computer science. This progression, from mechanical inventions and mathematical theories towards modern computer concepts and machines, led to the development of a major academic field, massive technological advancement across the Western world, and the basis of a massive worldwide trade and culture.
Capp or CAPP may refer to:

A computer is a digital electronic machine that can be programmed to carry out sequences of arithmetic or logical operations (computation) automatically. Modern computers can perform generic sets of operations known as programs. These programs enable computers to perform a wide range of tasks. A computer system is a "complete" computer that includes the hardware, operating system, and peripheral equipment needed and used for "full" operation. This term may also refer to a group of computers that are linked and function together, such as a computer network or computer cluster.
The modified Harvard architecture is a variation of the Harvard computer architecture that, unlike the pure Harvard architecture, allows the contents of the instruction memory to be accessed as data. Most modern computers that are documented as Harvard architecture are, in fact, modified Harvard architecture.
References
- Kent, Allen (1990), Encyclopedia of microcomputers: Volume 4 - Computer-Related Applications: Computational Linguistics to dBase, New York: Dekker, pp. 138–139, ISBN 0-8247-2703-7
- Foster, Caxton C (1976), Content Addressable Parallel Processors , Van Nostrand Reinhold, ISBN 0-442-22433-8
- ↑ "associative processor" . Retrieved 2021-03-14.
| | This computing article is a stub. You can help Wikipedia by expanding it. |