Related Research Articles
In computer science, an array data structure, or simply an array, is a data structure consisting of a collection of elements, each identified by at least one array index or key. An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula. The simplest type of data structure is a linear array, also called one-dimensional array.
C is a general-purpose computer programming language. It was created in the 1970s by Dennis Ritchie, and remains very widely used and influential. By design, C's features cleanly reflect the capabilities of the targeted CPUs. It has found lasting use in operating systems, device drivers, protocol stacks, though decreasingly for application software, and is common in computer architectures that range from the largest supercomputers to the smallest microcontrollers and embedded systems.

In computer science, a data structure is a data organization, management, and storage format that enables efficient access and modification. More precisely, a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data, i.e., it is an algebraic structure about data.
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains: data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that access time is linear. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.

In computer programming, a string is traditionally a sequence of characters, either as a literal constant or as some kind of variable. The latter may allow its elements to be mutated and the length changed, or it may be fixed. A string is generally considered as a data type and is often implemented as an array data structure of bytes that stores a sequence of elements, typically characters, using some character encoding. String may also denote more general arrays or other sequence data types and structures.
C dynamic memory allocation refers to performing manual memory management for dynamic memory allocation in the C programming language via a group of functions in the C standard library, namely malloc, realloc, calloc and free.

The syntax of the C programming language is the set of rules governing writing of software in the C language. It is designed to allow for programs that are extremely terse, have a close relationship with the resulting object code, and yet provide relatively high-level data abstraction. C was the first widely successful high-level language for portable operating-system development.
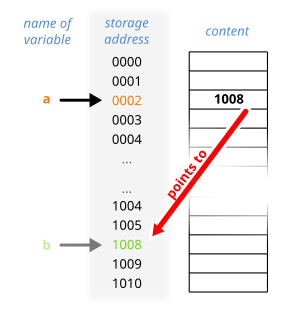
In computer science, a pointer is an object in many programming languages that stores a memory address. This can be that of another value located in computer memory, or in some cases, that of memory-mapped computer hardware. A pointer references a location in memory, and obtaining the value stored at that location is known as dereferencing the pointer. As an analogy, a page number in a book's index could be considered a pointer to the corresponding page; dereferencing such a pointer would be done by flipping to the page with the given page number and reading the text found on that page. The actual format and content of a pointer variable is dependent on the underlying computer architecture.
In computer science, a union is a value that may have any of several representations or formats within the same position in memory; that consists of a variable that may hold such a data structure. Some programming languages support special data types, called union types, to describe such values and variables. In other words, a union type definition will specify which of a number of permitted primitive types may be stored in its instances, e.g., "float or long integer". In contrast with a record, which could be defined to contain a float and an integer; in a union, there is only one value at any given time.
Addressing modes are an aspect of the instruction set architecture in most central processing unit (CPU) designs. The various addressing modes that are defined in a given instruction set architecture define how the machine language instructions in that architecture identify the operand(s) of each instruction. An addressing mode specifies how to calculate the effective memory address of an operand by using information held in registers and/or constants contained within a machine instruction or elsewhere.
A bit array is an array data structure that compactly stores bits. It can be used to implement a simple set data structure. A bit array is effective at exploiting bit-level parallelism in hardware to perform operations quickly. A typical bit array stores kw bits, where w is the number of bits in the unit of storage, such as a byte or word, and k is some nonnegative integer. If w does not divide the number of bits to be stored, some space is wasted due to internal fragmentation.

In computer science, a dynamic array, growable array, resizable array, dynamic table, mutable array, or array list is a random access, variable-size list data structure that allows elements to be added or removed. It is supplied with standard libraries in many modern mainstream programming languages. Dynamic arrays overcome a limit of static arrays, which have a fixed capacity that needs to be specified at allocation.
In computer programming, an Iliffe vector, also known as a display, is a data structure used to implement multi-dimensional arrays. An Iliffe vector for an n-dimensional array consists of a vector of pointers to an (n − 1)-dimensional array. They are often used to avoid the need for expensive multiplication operations when performing address calculation on an array element. They can also be used to implement jagged arrays, such as triangular arrays, triangular matrices and other kinds of irregularly shaped arrays. The data structure is named after John K. Iliffe.
In the C programming language, data types constitute the semantics and characteristics of storage of data elements. They are expressed in the language syntax in form of declarations for memory locations or variables. Data types also determine the types of operations or methods of processing of data elements.
A class in C++ is a user-defined type or data structure declared with keyword class that has data and functions as its members whose access is governed by the three access specifiers private, protected or public. By default access to members of a C++ class is private. The private members are not accessible outside the class; they can be accessed only through methods of the class. The public members form an interface to the class and are accessible outside the class.
sizeof is a unary operator in the programming languages C and C++. It generates the storage size of an expression or a data type, measured in the number of char-sized units. Consequently, the construct sizeof (char) is guaranteed to be 1. The actual number of bits of type char is specified by the preprocessor macro CHAR_BIT, defined in the standard include file limits.h. On most modern computing platforms this is eight bits. The result of sizeof has an unsigned integer type that is usually denoted by size_t.
In program analysis, shape analysis is a static code analysis technique that discovers and verifies properties of linked, dynamically allocated data structures in computer programs. It is typically used at compile time to find software bugs or to verify high-level correctness properties of programs. In Java programs, it can be used to ensure that a sort method correctly sorts a list. For C programs, it might look for places where a block of memory is not properly freed.
In computer programming, a variable is an abstract storage location paired with an associated symbolic name, which contains some known or unknown quantity of information referred to as a value; or in simpler terms, a variable is a container for a particular set of bits or type of data. A variable can eventually be associated with or identified by a memory address. The variable name is the usual way to reference the stored value, in addition to referring to the variable itself, depending on the context. This separation of name and content allows the name to be used independently of the exact information it represents. The identifier in computer source code can be bound to a value during run time, and the value of the variable may thus change during the course of program execution.
In computer science, a linked data structure is a data structure which consists of a set of data records (nodes) linked together and organized by references. The link between data can also be called a connector.
In computing, sequence containers refer to a group of container class templates in the standard library of the C++ programming language that implement storage of data elements. Being templates, they can be used to store arbitrary elements, such as integers or custom classes. One common property of all sequential containers is that the elements can be accessed sequentially. Like all other standard library components, they reside in namespace std.
References
- ↑ Pratt, T.; Zelkowitz, M. (1996). Programming Languages: Design and Implementation (3rd ed.). Upper Saddle River, NJ: Prentice-Hall. p. 114. ISBN 978-0-13-678012-0.
- ↑ Claybrook, Billy G. (October 13–15, 1976). The design of a template structure for a generalized data structure definition facility. ICSE '76: 2nd international conference on Software engineering. San Francisco, California, USA: IEEE Computer Society Press. pp. 408–413.
| | This computer-programming-related article is a stub. You can help Wikipedia by expanding it. |