Related Research Articles
In computer science, mutual exclusion is a property of concurrency control, which is instituted for the purpose of preventing race conditions. It is the requirement that one thread of execution never enters a critical section while a concurrent thread of execution is already accessing said critical section, which refers to an interval of time during which a thread of execution accesses a shared resource or shared memory.
In computer science, read-copy-update (RCU) is a synchronization mechanism that avoids the use of lock primitives while multiple threads concurrently read and update elements that are linked through pointers and that belong to shared data structures.
In computer science, an algorithm is called non-blocking if failure or suspension of any thread cannot cause failure or suspension of another thread; for some operations, these algorithms provide a useful alternative to traditional blocking implementations. A non-blocking algorithm is lock-free if there is guaranteed system-wide progress, and wait-free if there is also guaranteed per-thread progress. "Non-blocking" was used as a synonym for "lock-free" in the literature until the introduction of obstruction-freedom in 2003.
In computer science, compare-and-swap (CAS) is an atomic instruction used in multithreading to achieve synchronization. It compares the contents of a memory location with a given value and, only if they are the same, modifies the contents of that memory location to a new given value. This is done as a single atomic operation. The atomicity guarantees that the new value is calculated based on up-to-date information; if the value had been updated by another thread in the meantime, the write would fail. The result of the operation must indicate whether it performed the substitution; this can be done either with a simple boolean response, or by returning the value read from the memory location.
In computer science, a parallel random-access machine is a shared-memory abstract machine. As its name indicates, the PRAM is intended as the parallel-computing analogy to the random-access machine (RAM). In the same way that the RAM is used by sequential-algorithm designers to model algorithmic performance, the PRAM is used by parallel-algorithm designers to model parallel algorithmic performance. Similar to the way in which the RAM model neglects practical issues, such as access time to cache memory versus main memory, the PRAM model neglects such issues as synchronization and communication, but provides any (problem-size-dependent) number of processors. Algorithm cost, for instance, is estimated using two parameters O(time) and O(time × processor_number).

In concurrent programming, an operation is linearizable if it consists of an ordered list of invocation and response events (event), that may be extended by adding response events such that:
- The extended list can be re-expressed as a sequential history.
- That sequential history is a subset of the original unextended list.
In computer science, software transactional memory (STM) is a concurrency control mechanism analogous to database transactions for controlling access to shared memory in concurrent computing. It is an alternative to lock-based synchronization. STM is a strategy implemented in software, rather than as a hardware component. A transaction in this context occurs when a piece of code executes a series of reads and writes to shared memory. These reads and writes logically occur at a single instant in time; intermediate states are not visible to other (successful) transactions. The idea of providing hardware support for transactions originated in a 1986 paper by Tom Knight. The idea was popularized by Maurice Herlihy and J. Eliot B. Moss. In 1995 Nir Shavit and Dan Touitou extended this idea to software-only transactional memory (STM). Since 2005, STM has been the focus of intense research and support for practical implementations is growing.
Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping time periods—instead of sequentially—with one completing before the next starts.
In computer science, load-linked/store-conditional (LL/SC), sometimes known as load-reserved/store-conditional (LR/SC), are a pair of instructions used in multithreading to achieve synchronization. Load-link returns the current value of a memory location, while a subsequent store-conditional to the same memory location will store a new value only if no updates have occurred to that location since the load-link. Together, this implements a lock-free atomic read-modify-write operation.
In computer science and engineering, transactional memory attempts to simplify concurrent programming by allowing a group of load and store instructions to execute in an atomic way. It is a concurrency control mechanism analogous to database transactions for controlling access to shared memory in concurrent computing. Transactional memory systems provide high-level abstraction as an alternative to low-level thread synchronization. This abstraction allows for coordination between concurrent reads and writes of shared data in parallel systems.
Concurrent Haskell extends Haskell 98 with explicit concurrency. Its two main underlying concepts are:
Rock was a multithreading, multicore, SPARC microprocessor under development at Sun Microsystems. Canceled in 2010, it was a separate project from the SPARC T-Series (CoolThreads/Niagara) family of processors.
In computer science, synchronization refers to one of two distinct but related concepts: synchronization of processes, and synchronization of data. Process synchronization refers to the idea that multiple processes are to join up or handshake at a certain point, in order to reach an agreement or commit to a certain sequence of action. Data synchronization refers to the idea of keeping multiple copies of a dataset in coherence with one another, or to maintain data integrity. Process synchronization primitives are commonly used to implement data synchronization.
In computer science, a concurrent data structure is a particular way of storing and organizing data for access by multiple computing threads on a computer.
A distributed operating system is system software over a collection of independent software, networked, communicating, and physically separate computational nodes. They handle jobs which are serviced by multiple CPUs. Each individual node holds a specific software subset of the global aggregate operating system. Each subset is a composite of two distinct service provisioners. The first is a ubiquitous minimal kernel, or microkernel, that directly controls that node's hardware. Second is a higher-level collection of system management components that coordinate the node's individual and collaborative activities. These components abstract microkernel functions and support user applications.
A concurrent hash-trie or Ctrie is a concurrent thread-safe lock-free implementation of a hash array mapped trie. It is used to implement the concurrent map abstraction. It has particularly scalable concurrent insert and remove operations and is memory-efficient. It is the first known concurrent data-structure that supports O(1), atomic, lock-free snapshots.
In computer science, persistent memory is any method or apparatus for efficiently storing data structures such that they can continue to be accessed using memory instructions or memory APIs even after the end of the process that created or last modified them.
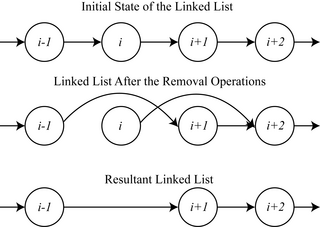
A non-blocking linked list is an example of non-blocking data structures designed to implement a linked list in shared memory using synchronization primitives:
Rachid Guerraoui is a Moroccan-Swiss computer scientist and a professor at the School of Computer and Communication Sciences at École Polytechnique Fédérale de Lausanne (EPFL), known for his contributions in the fields of concurrent and distributed computing. He is an ACM Fellow and the Chair in Informatics and Computational Science for the year 2018–2019 at Collège de France for distributed computing.

A concurrent hash table is an implementation of hash tables allowing concurrent access by multiple threads using a hash function.
References
- ↑ M. Greenwald. "Non-Blocking Synchronization and System Design". Stanford University Technical Report STAN-CS-TR-99-1624 . (p. 10 in particular)
- ↑ Ole Agesen, David L. Detlefs, Christine H. Flood, Alexander T. Garthwaite, Paul A. Martin, Mark Moir, Nir N. Shavit, and Guy L. Steele Jr. "DCAS-Based Concurrent Deques." Theory of Computing Systems 35, no. 3 (2002): 349-386.
- 1 2 Keir Fraser (2004), "Practical lock-freedom" UCAM-CL-TR-579.pdf
- ↑ Simon Doherty et al., "DCAS is not a silver bullet for nonblocking algorithm design". 16th annual ACM symposium on Parallelism in algorithms and architectures, 2004, pp. 216–224 .
- ↑ CAS2
- ↑ Greenwald, Michael, and David Cheriton. "The synergy between non-blocking synchronization and operating system structure." OSDI '96 Proceedings of the second USENIX symposium on Operating systems design and implementation (1996): 123-136. (particularly section 7.1 "Experimental Implementation")
- ↑ Harris, Timothy L.; Fraser, Keir; Pratt, Ian A. (2002). A Practical Multi-Word Compare-And-Swap Operation. Proc. Int'l Symp. Distributed Computing. CiteSeerX 10.1.1.13.7938 .
- ↑ Trevor Brown, Faith Ellen, and Eric Ruppert. "Pragmatic primitives for non-blocking data structures." In Proceedings of the 2013 ACM symposium on Principles of distributed computing, pp. 13-22. ACM, 2013.
- ↑ Trevor Brown, Faith Ellen, and Eric Ruppert. "A general technique for non-blocking trees." In Proceedings of the 19th ACM SIGPLAN symposium on Principles and practice of parallel programming, pp. 329-342. ACM, 2014.
- ↑ Dave Dice, Yossi Lev, Mark Moir, Dan Nussbaum, and Marek Olszewski. (2009) "Early experience with a commercial hardware transactional memory implementation." Sun Microsystems technical report (60 pp.) SMLI TR-2009-180. A short version appeared at ASPLOS’09 doi : 10.1145/1508244.1508263. The full-length report discusses how to implement DCAS using HTM in section 5.