In computer science, the computational complexity or simply complexity of an algorithm is the amount of resources required to run it. Particular focus is given to computation time and memory storage requirements. The complexity of a problem is the complexity of the best algorithms that allow solving the problem.
In software engineering, code coverage is a percentage measure of the degree to which the source code of a program is executed when a particular test suite is run. A program with high test coverage has more of its source code executed during testing, which suggests it has a lower chance of containing undetected software bugs compared to a program with low test coverage. Many different metrics can be used to calculate test coverage. Some of the most basic are the percentage of program subroutines and the percentage of program statements called during execution of the test suite.
Software testing is the act of examining the artifacts and the behavior of the software under test by validation and verification. Software testing can also provide an objective, independent view of the software to allow the business to appreciate and understand the risks of software implementation. Test techniques include, but are not necessarily limited to:
In computer science, algorithmic efficiency is a property of an algorithm which relates to the amount of computational resources used by the algorithm. An algorithm must be analyzed to determine its resource usage, and the efficiency of an algorithm can be measured based on the usage of different resources. Algorithmic efficiency can be thought of as analogous to engineering productivity for a repeating or continuous process.
In computer programming, unit testing is a software testing method by which individual units of source code—sets of one or more computer program modules together with associated control data, usage procedures, and operating procedures—are tested to determine whether they are fit for use. It is a standard step in development and implementation approaches such as Agile.
In theoretical computer science, an algorithm is correct with respect to a specification if it behaves as specified. Best explored is functional correctness, which refers to the input-output behavior of the algorithm.
Test-driven development (TDD) is a software development process relying on software requirements being converted to test cases before software is fully developed, and tracking all software development by repeatedly testing the software against all test cases. This is as opposed to software being developed first and test cases created later.

In mathematics, when a mathematical phenomenon runs counter to some intuition, then the phenomenon is sometimes called pathological. On the other hand, if a phenomenon does not run counter to intuition, it is sometimes called well-behaved. These terms are sometimes useful in mathematical research and teaching, but there is no strict mathematical definition of pathological or well-behaved.
A randomized algorithm is an algorithm that employs a degree of randomness as part of its logic or procedure. The algorithm typically uses uniformly random bits as an auxiliary input to guide its behavior, in the hope of achieving good performance in the "average case" over all possible choices of random determined by the random bits; thus either the running time, or the output are random variables.
White-box testing is a method of software testing that tests internal structures or workings of an application, as opposed to its functionality. In white-box testing, an internal perspective of the system is used to design test cases. The tester chooses inputs to exercise paths through the code and determine the expected outputs. This is analogous to testing nodes in a circuit, e.g. in-circuit testing (ICT). White-box testing can be applied at the unit, integration and system levels of the software testing process. Although traditional testers tended to think of white-box testing as being done at the unit level, it is used for integration and system testing more frequently today. It can test paths within a unit, paths between units during integration, and between subsystems during a system–level test. Though this method of test design can uncover many errors or problems, it has the potential to miss unimplemented parts of the specification or missing requirements. Where white-box testing is design-driven, that is, driven exclusively by agreed specifications of how each component of software is required to behave, white-box test techniques can accomplish assessment for unimplemented or missing requirements.
In mathematics, approximation theory is concerned with how functions can best be approximated with simpler functions, and with quantitatively characterizing the errors introduced thereby. What is meant by best and simpler will depend on the application.
In computer programming, gene expression programming (GEP) is an evolutionary algorithm that creates computer programs or models. These computer programs are complex tree structures that learn and adapt by changing their sizes, shapes, and composition, much like a living organism. And like living organisms, the computer programs of GEP are also encoded in simple linear chromosomes of fixed length. Thus, GEP is a genotype–phenotype system, benefiting from a simple genome to keep and transmit the genetic information and a complex phenotype to explore the environment and adapt to it.
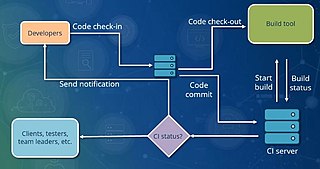
In software engineering, continuous integration (CI) is the practice of merging all developers' working copies to a shared mainline several times a day. Nowadays it is typically implemented in such a way that it triggers an automated build with testing. Grady Booch first proposed the term CI in his 1991 method, although he did not advocate integrating several times a day. Extreme programming (XP) adopted the concept of CI and did advocate integrating more than once per day – perhaps as many as tens of times per day.
In computer science, fault injection is a testing technique for understanding how computing systems behave when stressed in unusual ways. This can be achieved using physical- or software-based means, or using a hybrid approach. Widely studied physical fault injections include the application of high voltages, extreme temperatures and electromagnetic pulses on electronic components, such as computer memory and central processing units. By exposing components to conditions beyond their intended operating limits, computing systems can be coerced into mis-executing instructions and corrupting critical data.
In computing, computer performance is the amount of useful work accomplished by a computer system. Outside of specific contexts, computer performance is estimated in terms of accuracy, efficiency and speed of executing computer program instructions. When it comes to high computer performance, one or more of the following factors might be involved:
Richard Jay Lipton is an American computer scientist who is Associate Dean of Research, Professor, and the Frederick G. Storey Chair in Computing in the College of Computing at the Georgia Institute of Technology. He has worked in computer science theory, cryptography, and DNA computing.

In utility and industrial electric power transmission and distribution systems, a numerical relay is a computer-based system with software-based protection algorithms for the detection of electrical faults. Such relays are also termed as microprocessor type protective relays. They are functional replacements for electro-mechanical protective relays and may include many protection functions in one unit, as well as providing metering, communication, and self-test functions.
In computer science, a property testing algorithm for a decision problem is an algorithm whose query complexity to its input is much smaller than the instance size of the problem. Typically property testing algorithms are used to distinguish if some combinatorial structure S satisfies some property P, or is "far" from having this property, using only a small number of "local" queries to the object.
In software engineering, a microservice architecture is a variant of the service-oriented architecture structural style. It is an architectural pattern that arranges an application as a collection of loosely coupled, fine-grained services, communicating through lightweight protocols. One of its goals is that teams can develop and deploy their services independently of others. This is achieved by the reduction of several dependencies in the code base, allowing developers to evolve their services with limited restrictions from users, and for additional complexity to be hidden from users. As a consequence, organizations are able to develop software with fast growth and size, as well as use off-the-shelf services more easily. Communication requirements are reduced. These benefits come at a cost to maintaining the decoupling. Interfaces need to be designed carefully and treated as a public API. One technique that is used is having multiple interfaces on the same service, or multiple versions of the same service, so as to not disrupt existing users of the code.
This glossary of computer science is a list of definitions of terms and concepts used in computer science, its sub-disciplines, and related fields, including terms relevant to software, data science, and computer programming.