
Artificial neural networks (ANNs), usually simply called neural networks (NNs) or neural nets, are computing systems inspired by the biological neural networks that constitute animal brains.

Unsupervised learning is a type of algorithm that learns patterns from untagged data. The hope is that through mimicry, which is an important mode of learning in people, the machine is forced to build a compact internal representation of its world and then generate imaginative content from it. In contrast to supervised learning where data is tagged by an expert, e.g. as a "ball" or "fish", unsupervised methods exhibit self-organization that captures patterns as probability densities or a combination of neural feature preferences. The other levels in the supervision spectrum are reinforcement learning where the machine is given only a numerical performance score as guidance, and semi-supervised learning where a smaller portion of the data is tagged.
Connectionism refers to both an approach in the field of cognitive science that hopes to explain mental phenomena using artificial neural networks (ANN) and to a wide range of techniques and algorithms using ANNs in the context of artificial intelligence to build more intelligent machines. Connectionism presents a cognitive theory based on simultaneously occurring, distributed signal activity via connections that can be represented numerically, where learning occurs by modifying connection strengths based on experience.
A Hopfield network is a form of recurrent artificial neural network and a type of spin glass system popularised by John Hopfield in 1982 as described earlier by Little in 1974 based on Ernst Ising's work with Wilhelm Lenz on the Ising model. Hopfield networks serve as content-addressable ("associative") memory systems with binary threshold nodes, or with continuous variables. Hopfield networks also provide a model for understanding human memory.
The Helmholtz machine is a type of artificial neural network that can account for the hidden structure of a set of data by being trained to create a generative model of the original set of data. The hope is that by learning economical representations of the data, the underlying structure of the generative model should reasonably approximate the hidden structure of the data set. A Helmholtz machine contains two networks, a bottom-up recognition network that takes the data as input and produces a distribution over hidden variables, and a top-down "generative" network that generates values of the hidden variables and the data itself. At the time, Helmholtz machines were one of a handful of learning architectures that used feedback as well as feedforward to ensure quality of learned models.
A recurrent neural network (RNN) is a class of artificial neural networks where connections between nodes can create a cycle, allowing output from some nodes to affect subsequent input to the same nodes. This allows it to exhibit temporal dynamic behavior. Derived from feedforward neural networks, RNNs can use their internal state (memory) to process variable length sequences of inputs. This makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition. Recurrent neural networks are theoretically Turing complete and can run arbitrary programs to process arbitrary sequences of inputs.

A feedforward neural network (FNN) is an artificial neural network wherein connections between the nodes do not form a cycle. As such, it is different from its descendant: recurrent neural networks.

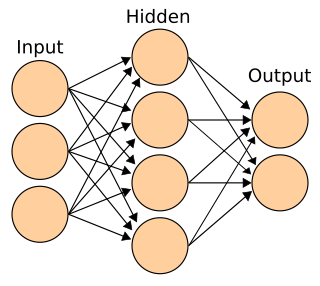
A neural network is a network or circuit of biological neurons, or, in a modern sense, an artificial neural network, composed of artificial neurons or nodes. Thus, a neural network is either a biological neural network, made up of biological neurons, or an artificial neural network, used for solving artificial intelligence (AI) problems. The connections of the biological neuron are modeled in artificial neural networks as weights between nodes. A positive weight reflects an excitatory connection, while negative values mean inhibitory connections. All inputs are modified by a weight and summed. This activity is referred to as a linear combination. Finally, an activation function controls the amplitude of the output. For example, an acceptable range of output is usually between 0 and 1, or it could be −1 and 1.
Neural network software is used to simulate, research, develop, and apply artificial neural networks, software concepts adapted from biological neural networks, and in some cases, a wider array of adaptive systems such as artificial intelligence and machine learning.
JOONE is a component based neural network framework built in Java.

NeuroSolutions is a neural network development environment developed by NeuroDimension. It combines a modular, icon-based (component-based) network design interface with an implementation of advanced learning procedures, such as conjugate gradients, Levenberg-Marquardt and backpropagation through time. The software is used to design, train and deploy neural network models to perform a wide variety of tasks such as data mining, classification, function approximation, multivariate regression and time-series prediction.

ADALINE is an early single-layer artificial neural network and the name of the physical device that implemented this network. The network uses memistors. It was developed by Professor Bernard Widrow and his doctorate student Ted Hoff at Stanford University in 1960. It is based on the McCulloch–Pitts neuron. It consists of a weight, a bias and a summation function.

An echo state network (ESN) is a type of reservoir computer that uses a recurrent neural network with a sparsely connected hidden layer. The connectivity and weights of hidden neurons are fixed and randomly assigned. The weights of output neurons can be learned so that the network can produce or reproduce specific temporal patterns. The main interest of this network is that although its behaviour is non-linear, the only weights that are modified during training are for the synapses that connect the hidden neurons to output neurons. Thus, the error function is quadratic with respect to the parameter vector and can be differentiated easily to a linear system.
There are many types of artificial neural networks (ANN).

Deep learning is part of a broader family of machine learning methods based on artificial neural networks with representation learning. Learning can be supervised, semi-supervised or unsupervised.
An artificial neural network's learning rule or learning process is a method, mathematical logic or algorithm which improves the network's performance and/or training time. Usually, this rule is applied repeatedly over the network. It is done by updating the weights and bias levels of a network when a network is simulated in a specific data environment. A learning rule may accept existing conditions of the network and will compare the expected result and actual result of the network to give new and improved values for weights and bias. Depending on the complexity of actual model being simulated, the learning rule of the network can be as simple as an XOR gate or mean squared error, or as complex as the result of a system of differential equations.
Eclipse Deeplearning4j is a programming library written in Java for the Java virtual machine (JVM). It is a framework with wide support for deep learning algorithms. Deeplearning4j includes implementations of the restricted Boltzmann machine, deep belief net, deep autoencoder, stacked denoising autoencoder and recursive neural tensor network, word2vec, doc2vec, and GloVe. These algorithms all include distributed parallel versions that integrate with Apache Hadoop and Spark.
The following outline is provided as an overview of and topical guide to machine learning. Machine learning is a subfield of soft computing within computer science that evolved from the study of pattern recognition and computational learning theory in artificial intelligence. In 1959, Arthur Samuel defined machine learning as a "field of study that gives computers the ability to learn without being explicitly programmed". Machine learning explores the study and construction of algorithms that can learn from and make predictions on data. Such algorithms operate by building a model from an example training set of input observations in order to make data-driven predictions or decisions expressed as outputs, rather than following strictly static program instructions.
In machine learning, hyperparameter optimization or tuning is the problem of choosing a set of optimal hyperparameters for a learning algorithm. A hyperparameter is a parameter whose value is used to control the learning process. By contrast, the values of other parameters are learned.
The history of artificial neural networks (ANN) began with Warren McCulloch and Walter Pitts (1943) who created a computational model for neural networks based on algorithms called threshold logic. This model paved the way for research to split into two approaches. One approach focused on biological processes while the other focused on the application of neural networks to artificial intelligence. This work led to work on nerve networks and their link to finite automata.
