Related Research Articles
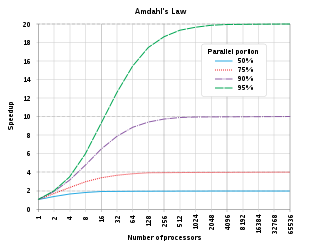
In computer architecture, Amdahl's law is a formula which gives the theoretical speedup in latency of the execution of a task at fixed workload that can be expected of a system whose resources are improved. It states that "the overall performance improvement gained by optimizing a single part of a system is limited by the fraction of time that the improved part is actually used". It is named after computer scientist Gene Amdahl, and was presented at the American Federation of Information Processing Societies (AFIPS) Spring Joint Computer Conference in 1967.
A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another. Distributed computing is a field of computer science that studies distributed systems.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
In computer science, a parallel algorithm, as opposed to a traditional serial algorithm, is an algorithm which can do multiple operations in a given time. It has been a tradition of computer science to describe serial algorithms in abstract machine models, often the one known as random-access machine. Similarly, many computer science researchers have used a so-called parallel random-access machine (PRAM) as a parallel abstract machine (shared-memory).
In computer science, an algorithm is called non-blocking if failure or suspension of any thread cannot cause failure or suspension of another thread; for some operations, these algorithms provide a useful alternative to traditional blocking implementations. A non-blocking algorithm is lock-free if there is guaranteed system-wide progress, and wait-free if there is also guaranteed per-thread progress. "Non-blocking" was used as a synonym for "lock-free" in the literature until the introduction of obstruction-freedom in 2003.

In computer science, concurrency is the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the outcome. This allows for parallel execution of the concurrent units, which can significantly improve overall speed of the execution in multi-processor and multi-core systems. In more technical terms, concurrency refers to the decomposability of a program, algorithm, or problem into order-independent or partially-ordered components or units of computation.
In computer science, a parallel random-access machine is a shared-memory abstract machine. As its name indicates, the PRAM is intended as the parallel-computing analogy to the random-access machine (RAM). In the same way that the RAM is used by sequential-algorithm designers to model algorithmic performance, the PRAM is used by parallel-algorithm designers to model parallel algorithmic performance. Similar to the way in which the RAM model neglects practical issues, such as access time to cache memory versus main memory, the PRAM model neglects such issues as synchronization and communication, but provides any (problem-size-dependent) number of processors. Algorithm cost, for instance, is estimated using two parameters O(time) and O(time × processor_number).
In computing, a parallel programming model is an abstraction of parallel computer architecture, with which it is convenient to express algorithms and their composition in programs. The value of a programming model can be judged on its generality: how well a range of different problems can be expressed for a variety of different architectures, and its performance: how efficiently the compiled programs can execute. The implementation of a parallel programming model can take the form of a library invoked from a sequential language, as an extension to an existing language, or as an entirely new language.
Concurrent computing is a form of computing in which several computations are executed concurrently—during overlapping time periods—instead of sequentially—with one completing before the next starts.

In computer architecture, Gustafson's law gives the speedup in the execution time of a task that theoretically gains from parallel computing, using a hypothetical run of the task on a single-core machine as the baseline. To put it another way, it is the theoretical "slowdown" of an already parallelized task if running on a serial machine. It is named after computer scientist John L. Gustafson and his colleague Edwin H. Barsis, and was presented in the article Reevaluating Amdahl's Law in 1988.
In parallel algorithms, the list ranking problem involves determining the position, or rank, of each item in a linked list. That is, the first item in the list should be assigned the number 1, the second item in the list should be assigned the number 2, etc. Although it is straightforward to solve this problem efficiently on a sequential computer, by traversing the list in order, it is more complicated to solve in parallel. As Anderson & Miller (1990) wrote, the problem was viewed as important in the parallel algorithms community both for its many applications and because solving it led to many important ideas that could be applied in parallel algorithms more generally.
In graph theory and computer science, the lowest common ancestor (LCA) of two nodes v and w in a tree or directed acyclic graph (DAG) T is the lowest node that has both v and w as descendants, where we define each node to be a descendant of itself.
Thread Level Speculation (TLS), also known as Speculative Multithreading, or Speculative Parallelization, is a technique to speculatively execute a section of computer code that is anticipated to be executed later in parallel with the normal execution on a separate independent thread. Such a speculative thread may need to make assumptions about the values of input variables. If these prove to be invalid, then the portions of the speculative thread that rely on these input variables will need to be discarded and squashed. If the assumptions are correct the program can complete in a shorter time provided the thread was able to be scheduled efficiently.
XMTC is a shared-memory parallel programming language. It is an extension of the C programming language which strives to enable easy PRAM-like programming based on the explicit multi-threading paradigm. It is developed as part of the XMT PRAM-On-Chip vision by a research team at the University of Maryland, College Park, led by Dr. Uzi Vishkin.

Kurt Mehlhorn is a German theoretical computer scientist. He has been a vice president of the Max Planck Society and is director of the Max Planck Institute for Computer Science.
Uzi Vishkin is a computer scientist at the University of Maryland, College Park, where he is Professor of Electrical and Computer Engineering at the University of Maryland Institute for Advanced Computer Studies (UMIACS). Uzi Vishkin is known for his work in the field of parallel computing. In 1996, he was inducted as a Fellow of the Association for Computing Machinery, with the following citation: "One of the pioneers of parallel algorithms research, Dr. Vishkin's seminal contributions played a leading role in forming and shaping what thinking in parallel has come to mean in the fundamental theory of Computer Science."
In computing, algorithmic skeletons, or parallelism patterns, are a high-level parallel programming model for parallel and distributed computing.
In parallel computing, work stealing is a scheduling strategy for multithreaded computer programs. It solves the problem of executing a dynamically multithreaded computation, one that can "spawn" new threads of execution, on a statically multithreaded computer, with a fixed number of processors. It does so efficiently in terms of execution time, memory usage, and inter-processor communication.
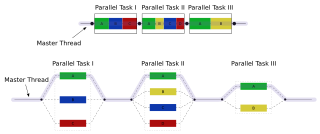
In parallel computing, the fork–join model is a way of setting up and executing parallel programs, such that execution branches off in parallel at designated points in the program, to "join" (merge) at a subsequent point and resume sequential execution. Parallel sections may fork recursively until a certain task granularity is reached. Fork–join can be considered a parallel design pattern. It was formulated as early as 1963.
In computer science, the analysis of parallel algorithms is the process of finding the computational complexity of algorithms executed in parallel – the amount of time, storage, or other resources needed to execute them. In many respects, analysis of parallel algorithms is similar to the analysis of sequential algorithms, but is generally more involved because one must reason about the behavior of multiple cooperating threads of execution. One of the primary goals of parallel analysis is to understand how a parallel algorithm's use of resources changes as the number of processors is changed.
References
- Brent, Richard P. (1974), "The parallel evaluation of general arithmetic expressions", Journal of the ACM, 21 (2): 201–208, CiteSeerX 10.1.1.100.9361 , doi:10.1145/321812.321815, S2CID 16416106 .
- Shiloach, Yossi; Vishkin, Uzi (1982), "An O(n2 log n) parallel max-flow algorithm", Journal of Algorithms, 3 (2): 128–146, doi:10.1016/0196-6774(82)90013-X .
- JaJa, Joseph (1992), An Introduction to Parallel Algorithms, Addison-Wesley, ISBN 978-0-201-54856-3
- Keller, Jorg; Kessler, Cristoph W.; Traeff, Jesper L. (2001), Practical PRAM Programming, Wiley-Interscience, ISBN 978-0-471-35351-5
- Naishlos, Dorit; Nuzman, Joseph; Tseng, Chau-Wen; Vishkin, Uzi (2003), "Towards a First Vertical Prototyping of an Extremely Fine-Grained Parallel Programming Approach" (PDF), Theory of Computing Systems, 36 (5): 551–552, doi:10.1007/s00224-003-1086-6, S2CID 1929495 .
- Torbert, Shane; Vishkin, Uzi; Tzur, Ron; Ellison, David (2010), "Is teaching parallel algorithmic thinking to high school students possible?", Proceedings of the 41st ACM technical symposium on Computer science education - SIGCSE '10, p. 290, doi: 10.1145/1734263.1734363 , ISBN 9781450300063 .
- Vishkin, Uzi; Dascal, Shlomit; Berkovich, Efraim; Nuzman, Joseph (1998), "Explicit Multi-Threading (XMT) bridging models for instruction parallelism", Proc. 1998 ACM Symposium on Parallel Algorithms and Architectures (SPAA), pp. 140–151.
- Vishkin, Uzi (2009), Thinking in Parallel: Some Basic Data-Parallel Algorithms and Techniques, 104 pages (PDF), Class notes of courses on parallel algorithms taught since 1992 at the University of Maryland, College Park, Tel Aviv University and the Technion
- Wen, Xingzhi; Vishkin, Uzi (2008), "FPGA-based prototype of a PRAM-on-chip processor", Proc. 2008 ACM Conference on Computing Frontiers (Ischia, Italy) (PDF), pp. 55–66, doi:10.1145/1366230.1366240, ISBN 9781605580777, S2CID 11557669 .
- Vishkin, Uzi (2011), "Using simple abstraction to reinvent computing for parallelism", Communications of the ACM, 54: 75–85, doi: 10.1145/1866739.1866757 .
- Caragea, George; Vishkin, Uzi (2011), "Brief announcement: better speedups for parallel max-flow", Proc. 23rd ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), pp. 131–134, doi:10.1145/1989493.1989511, ISBN 9781450307437, S2CID 5511743 .
- Edwards, James A.; Vishkin, Uzi (2012a), "Better speedups using simpler parallel programming for graph connectivity and biconnectivity", Proceedings of the 2012 International Workshop on Programming Models and Applications for Multicores and Manycores, pp. 103–114, doi:10.1145/2141702.2141714, ISBN 9781450312110, S2CID 15095569 .
- Edwards, James A.; Vishkin, Uzi (2012b), "Brief announcement: speedups for parallel graph triconnectivity", Proc. 24th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), pp. 190–192, doi:10.1145/2312005.2312042, ISBN 9781450312134, S2CID 16908459 .
- Vishkin, Uzi (2014), "Is Multi-Core Hardware for General-Purpose Parallel Processing Broken? Viewpoint article", Communications of the ACM, 57 (4): 35–39, doi:10.1145/2580945, S2CID 30098719 .
- Ghanim, Fady; Vishkin, Uzi; Barua, Rajeev (February 2018), "Easy PRAM-Based High-Performance Parallel Programming with ICE", IEEE Transactions on Parallel and Distributed Systems, 29 (2): 377–390, doi: 10.1109/TPDS.2017.2754376 , hdl:1903/18521 .