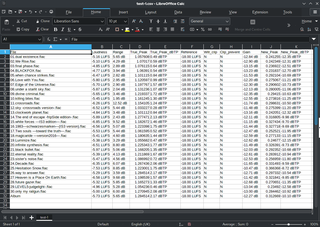
A spreadsheet is a computer application for computation, organization, analysis and storage of data in tabular form. Spreadsheets were developed as computerized analogs of paper accounting worksheets. The program operates on data entered in cells of a table. Each cell may contain either numeric or text data, or the results of formulas that automatically calculate and display a value based on the contents of other cells. The term spreadsheet may also refer to one such electronic document.

In communications and computing, a machine-readable medium is a medium capable of storing data in a format easily readable by a digital computer or a sensor. It contrasts with human-readable medium and data.

In computing, extract, transform, load (ETL) is a three-phase process where data is extracted from an input source, transformed, and loaded into an output data container. The data can be collated from one or more sources and it can also be output to one or more destinations. ETL processing is typically executed using software applications but it can also be done manually by system operators. ETL software typically automates the entire process and can be run manually or on recurring schedules either as single jobs or aggregated into a batch of jobs.

The tab keyTab ↹ on a keyboard is used to advance the cursor to the next tab stop.
A GIS file format is a standard for encoding geographical information into a computer file, as a specialized type of file format for use in geographic information systems (GIS) and other geospatial applications. Since the 1970s, dozens of formats have been created based on various data models for various purposes. They have been created by government mapping agencies, GIS software vendors, standards bodies such as the Open Geospatial Consortium, informal user communities, and even individual developers.

Comma-separated values (CSV) is a text file format that uses commas to separate values, and newlines to separate records. A CSV file stores tabular data in plain text, where each line of the file typically represents one data record. Each record consists of the same number of fields, and these are separated by commas in the CSV file. If the field delimiter itself may appear within a field, fields can be surrounded with quotation marks.

passwd is a command on Unix, Plan 9, Inferno, and most Unix-like operating systems used to change a user's password. The password entered by the user is run through a key derivation function to create a hashed version of the new password, which is saved. Only the hashed version is stored; the entered password is not saved for security reasons.
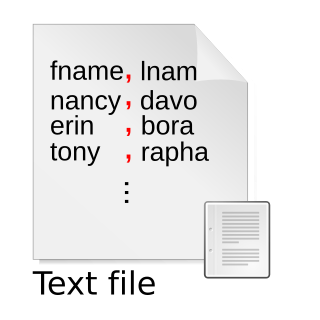
A delimiter is a sequence of one or more characters for specifying the boundary between separate, independent regions in plain text, mathematical expressions or other data streams. An example of a delimiter is the comma character, which acts as a field delimiter in a sequence of comma-separated values. Another example of a delimiter is the time gap used to separate letters and words in the transmission of Morse code.
paste is a Unix command line utility which is used to join files horizontally by outputting lines consisting of the sequentially corresponding lines of each file specified, separated by tabs, to the standard output.
Formats that use delimiter-separated values store two-dimensional arrays of data by separating the values in each row with specific delimiter characters. Most database and spreadsheet programs are able to read or save data in a delimited format. Due to their wide support, DSV files can be used in data exchange among many applications.
A table is a collection of related data held in a table format within a database. It consists of columns and rows.

Tab-separated values (TSV) is a simple, text-based file format for storing tabular data. Records are separated by newlines, and values within a record are separated by tab characters. The TSV format is thus a delimiter-separated values format, similar to comma-separated values.
Data drilling refers to any of various operations and transformations on tabular, relational, and multidimensional data. The term has widespread use in various contexts, but is primarily associated with specialized software designed specifically for data analysis.
Symbolic Link (SYLK) is a Microsoft file format typically used to exchange data between applications, specifically spreadsheets. SYLK files conventionally have a .slk suffix. Composed of only displayable ANSI characters, it can be easily created and processed by other applications, such as databases.
TPL Tables is a cross tabulation system used to generate statistical tables for analysis or publication.
Data feed is a mechanism for users to receive updated data from data sources. It is commonly used by real-time applications in point-to-point settings as well as on the World Wide Web. The latter is also called web feed. News feed is a popular form of web feed. RSS feed makes dissemination of blogs easy. Product feeds play increasingly important role in e-commerce and internet marketing, as well as news distribution, financial markets, and cybersecurity. Data feeds usually require structured data that include different labelled fields, such as "title" or "product".
Shazam is a comprehensive econometrics and statistics package for estimating, testing, simulating and forecasting many types of econometrics and statistical models. SHAZAM was originally created in 1977 by Kenneth White.

OpenRefine is an open-source desktop application for data cleanup and transformation to other formats, an activity commonly known as data wrangling. It is similar to spreadsheet applications, and can handle spreadsheet file formats such as CSV, but it behaves more like a database.
Stylus Studio is an integrated development environment (IDE) for the Extensible Markup Language (XML). It consists of a variety of tools and visual designers to edit and transform XML documents and legacy data such as electronic data interchange (EDI), comma-separated values (CSV) and relational data.
Fielded Text is a proposed standard which provides structure and schema definition to text files which contain tables of values. The standard allows the format and structure of the data within the text file to be specified by a Meta file. This Meta file can then be used to access the data in the file in manner similar to which data is accessed in a database.
