
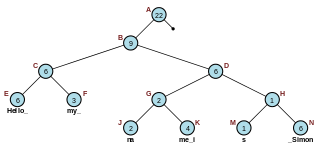
In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure with the key of each internal node being greater than all the keys in the respective node's left subtree and less than the ones in its right subtree. The time complexity of operations on the binary search tree is linear with respect to the height of the tree.
In computer science, a double-ended queue is an abstract data type that generalizes a queue, for which elements can be added to or removed from either the front (head) or back (tail). It is also often called a head-tail linked list, though properly this refers to a specific data structure implementation of a deque.

Emacs Lisp is a dialect of the Lisp programming language used as a scripting language by Emacs. It is used for implementing most of the editing functionality built into Emacs, the remainder being written in C, as is the Lisp interpreter. Emacs Lisp is also termed Elisp, although there are also older, unrelated Lisp dialects with that name.
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that data access time is linear in respect to the number of nodes in the list. Because nodes are serially linked, accessing any node requires that the prior node be accessed beforehand. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.
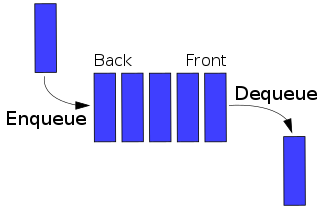
In computer science, a queue is a collection of entities that are maintained in a sequence and can be modified by the addition of entities at one end of the sequence and the removal of entities from the other end of the sequence. By convention, the end of the sequence at which elements are added is called the back, tail, or rear of the queue, and the end at which elements are removed is called the head or front of the queue, analogously to the words used when people line up to wait for goods or services.

In computer programming, a string is traditionally a sequence of characters, either as a literal constant or as some kind of variable. The latter may allow its elements to be mutated and the length changed, or it may be fixed. A string is generally considered as a data type and is often implemented as an array data structure of bytes that stores a sequence of elements, typically characters, using some character encoding. String may also denote more general arrays or other sequence data types and structures.

A text editor is a type of computer program that edits plain text. Such programs are sometimes known as "notepad" software. Text editors are provided with operating systems and software development packages, and can be used to change files such as configuration files, documentation files and programming language source code.
TECO, short for Text Editor & Corrector, is both a character-oriented text editor and a programming language, that was developed in 1962 for use on Digital Equipment Corporation computers, and has since become available on PCs and Unix. Dan Murphy developed TECO while a student at the Massachusetts Institute of Technology (MIT).
Cut, copy, and paste are essential commands of modern human–computer interaction and user interface design. They offer an interprocess communication technique for transferring data through a computer's user interface. The cut command removes the selected data from its original position, and the copy command creates a duplicate; in both cases the selected data is kept in temporary storage called the clipboard. Clipboard data is later inserted wherever a paste command is issued. The data remains available to any application supporting the feature, thus allowing easy data transfer between applications.
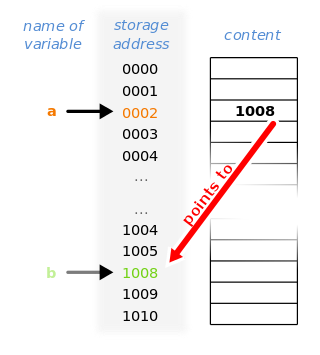
In computer science, a pointer is an object in many programming languages that stores a memory address. This can be that of another value located in computer memory, or in some cases, that of memory-mapped computer hardware. A pointer references a location in memory, and obtaining the value stored at that location is known as dereferencing the pointer. As an analogy, a page number in a book's index could be considered a pointer to the corresponding page; dereferencing such a pointer would be done by flipping to the page with the given page number and reading the text found on that page. The actual format and content of a pointer variable is dependent on the underlying computer architecture.
In computing, a persistent data structure or not ephemeral data structure is a data structure that always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure. The term was introduced in Driscoll, Sarnak, Sleator, and Tarjan's 1986 article.
In computer programming, a rope, or cord, is a data structure composed of smaller strings that is used to efficiently store and manipulate a very long string. For example, a text editing program may use a rope to represent the text being edited, so that operations such as insertion, deletion, and random access can be done efficiently.

In computer science, a dynamic array, growable array, resizable array, dynamic table, mutable array, or array list is a random access, variable-size list data structure that allows elements to be added or removed. It is supplied with standard libraries in many modern mainstream programming languages. Dynamic arrays overcome a limit of static arrays, which have a fixed capacity that needs to be specified at allocation.
In human–computer interaction, a cursor is an indicator used to show the current position on a computer monitor or other display device that will respond to input.
GNU Emacs is a free software text editor. It was created by GNU Project founder Richard Stallman, based on the Emacs editor developed for Unix operating systems. GNU Emacs has been a central component of the GNU project and a flagship project of the free software movement. Its tag line is "the extensible self-documenting text editor."
Emacs, originally named EMACS, is a family of text editors that are characterized by their extensibility. The manual for the most widely used variant, GNU Emacs, describes it as "the extensible, customizable, self-documenting, real-time display editor". Development of the first Emacs began in the mid-1970s, and work on GNU Emacs, directly descended from the original, is ongoing; its latest version is 29.3, released March 2024.
In computing, sequence containers refer to a group of container class templates in the standard library of the C++ programming language that implement storage of data elements. Being templates, they can be used to store arbitrary elements, such as integers or custom classes. One common property of all sequential containers is that the elements can be accessed sequentially. Like all other standard library components, they reside in namespace std.
In computing, a piece table is a data structure typically used to represent a text document while it is edited in a text editor. Initially a reference to the whole of the original file is created, which represents the as yet unchanged file. Subsequent inserts and deletes replace a span by combinations of one, two, or three references to sections of either the original document or to a buffer holding inserted text.
In computer science, a fractal tree index is a tree data structure that keeps data sorted and allows searches and sequential access in the same time as a B-tree but with insertions and deletions that are asymptotically faster than a B-tree. Like a B-tree, a fractal tree index is a generalization of a binary search tree in that a node can have more than two children. Furthermore, unlike a B-tree, a fractal tree index has buffers at each node, which allow insertions, deletions and other changes to be stored in intermediate locations. The goal of the buffers is to schedule disk writes so that each write performs a large amount of useful work, thereby avoiding the worst-case performance of B-trees, in which each disk write may change a small amount of data on disk. Like a B-tree, fractal tree indexes are optimized for systems that read and write large blocks of data. The fractal tree index has been commercialized in databases by Tokutek. Originally, it was implemented as a cache-oblivious lookahead array, but the current implementation is an extension of the Bε tree. The Bε is related to the Buffered Repository Tree. The Buffered Repository Tree has degree 2, whereas the Bε tree has degree Bε. The fractal tree index has also been used in a prototype filesystem. An open source implementation of the fractal tree index is available, which demonstrates the implementation details outlined below.
A non-blocking linked list is an example of non-blocking data structures designed to implement a linked list in shared memory using synchronization primitives: