Active Server Pages (ASP) is Microsoft's first server-side scripting language and engine for dynamic web pages.

HTTP is an application layer protocol in the Internet protocol suite model for distributed, collaborative, hypermedia information systems. HTTP is the foundation of data communication for the World Wide Web, where hypertext documents include hyperlinks to other resources that the user can easily access, for example by a mouse click or by tapping the screen in a web browser.
A web browser is an application for accessing websites. When a user requests a web page from a particular website, the browser retrieves its files from a web server and then displays the page on the user's screen. Browsers are used on a range of devices, including desktops, laptops, tablets, and smartphones. In 2020, an estimated 4.9 billion people have used a browser. The most-used browser is Google Chrome, with a 64% global market share on all devices, followed by Safari with 19%.

A web server is computer software and underlying hardware that accepts requests via HTTP or its secure variant HTTPS. A user agent, commonly a web browser or web crawler, initiates communication by making a request for a web page or other resource using HTTP, and the server responds with the content of that resource or an error message. A web server can also accept and store resources sent from the user agent if configured to do so.

In computer networking, a proxy server is a server application that acts as an intermediary between a client requesting a resource and the server providing that resource. It improves privacy, security, and performance in the process.

robots.txt is the filename used for implementing the Robots Exclusion Protocol, a standard used by websites to indicate to visiting web crawlers and other web robots which portions of the website they are allowed to visit.

Internet Information Services is an extensible web server created by Microsoft for use with the Windows NT family. IIS supports HTTP, HTTP/2, HTTP/3, HTTPS, FTP, FTPS, SMTP and NNTP. It has been an integral part of the Windows NT family since Windows NT 4.0, though it may be absent from some editions, and is not active by default. A dedicated suite of software called SEO Toolkit is included in the latest version of the manager. This suite has several tools for SEO optimization with features for metatag / web coding optimization, sitemaps / robots.txt configuration, website analysis, crawler setting, SSL server-side configuration and more.
Inline linking is the use of a linked object, often an image, on one site by a web page belonging to a second site. One site is said to have an inline link to the other site where the object is located.
A favicon, also known as a shortcut icon, website icon, tab icon, URL icon, or bookmark icon, is a file containing one or more small icons associated with a particular website or web page. A web designer can create such an icon and upload it to a website by several means, and graphical web browsers will then make use of it. Browsers that provide favicon support typically display a page's favicon in the browser's address bar and next to the page's name in a list of bookmarks. Browsers that support a tabbed document interface typically show a page's favicon next to the page's title on the tab, and site-specific browsers use the favicon as a desktop icon.
An .htaccess file is a directory-level configuration file supported by several web servers, used for configuration of website-access issues, such as URL redirection, URL shortening, access control, and more. The 'dot' before the file name makes it a hidden file in Unix-based environments.
URL redirection, also called URL forwarding, is a World Wide Web technique for making a web page available under more than one URL address. When a web browser attempts to open a URL that has been redirected, a page with a different URL is opened. Similarly, domain redirection or domain forwarding is when all pages in a URL domain are redirected to a different domain, as when wikipedia.com and wikipedia.net are automatically redirected to wikipedia.org.
The Webalizer is web log analysis software, which generates web pages of analysis, from access and usage logs. It is one of the most commonly used web server administration tools. It was initiated by Bradford L. Barrett in 1997. Statistics commonly reported by Webalizer include hits, visits, referrers, the visitors' countries, and the amount of data downloaded. These statistics can be viewed graphically and presented by different time frames, such as by day, hour, or month.
In computing, the same-origin policy (SOP) is a concept in the web application security model. Under the policy, a web browser permits scripts contained in a first web page to access data in a second web page, but only if both web pages have the same origin. An origin is defined as a combination of URI scheme, host name, and port number. This policy prevents a malicious script on one page from obtaining access to sensitive data on another web page through that page's (DOM).
An image hosting service allows individuals to upload images to an Internet website. The image host will then store the image onto its server, and show the individual different types of code to allow others to view that image. Some examples are Flickr, Imgur, and Photobucket.

Google Analytics is a web analytics service offered by Google that tracks and reports website traffic and also mobile app traffic & events, currently as a platform inside the Google Marketing Platform brand. Google launched the service in November 2005 after acquiring Urchin.

An error message is the information displayed when an unforeseen problem occurs, usually on a computer or other device. Modern operating systems with graphical user interfaces, often display error messages using dialog boxes. Error messages are used when user intervention is required, to indicate that a desired operation has failed, or to relay important warnings. Error messages are seen widely throughout computing, and are part of every operating system or computer hardware device. The proper design of error messages is an important topic in usability and other fields of human–computer interaction.
HTTP compression is a capability that can be built into web servers and web clients to improve transfer speed and bandwidth utilization.
HTTP 403 is an HTTP status code meaning access to the requested resource is forbidden. The server understood the request, but will not fulfill it, if it was correct.
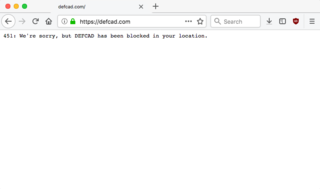
In computer networking, HTTP 451 Unavailable For Legal Reasons is a proposed standard error status code of the HTTP protocol to be displayed when the user requests a resource which cannot be served for legal reasons, such as a web page censored by a government. The number 451 is a reference to Ray Bradbury's 1953 dystopian novel Fahrenheit 451, in which books are outlawed. 451 provides more information than HTTP 403, which is often used for the same purpose. This status code is currently a proposed standard in RFC 7725 but is not yet formally a part of HTTP, as of RFC 9110.