The iterative proportional fitting procedure (IPF or IPFP, also known as biproportional fitting or biproportion in statistics or economics (input-output analysis, etc.), RAS algorithm[1] in economics, raking in survey statistics, and matrix scaling in computer science) is the operation of finding the fitted matrix which is the closest to an initial matrix but with the row and column totals of a target matrix (which provides the constraints of the problem; the interior of is unknown). The fitted matrix being of the form , where and are diagonal matrices such that has the margins (row and column sums) of . Some algorithms can be chosen to perform biproportion. We have also the entropy maximization,[2][3] information loss minimization (or cross-entropy)[4] or RAS which consists of factoring the matrix rows to match the specified row totals, then factoring its columns to match the specified column totals; each step usually disturbs the previous step's match, so these steps are repeated in cycles, re-adjusting the rows and columns in turn, until all specified marginal totals are satisfactorily approximated. However, all algorithms give the same solution.[5] In three- or more-dimensional cases, adjustment steps are applied for the marginals of each dimension in turn, the steps likewise repeated in cycles.
IPF has been "re-invented" many times, the earliest by Kruithof in 1937 [6] in relation to telephone traffic ("Kruithof’s double factor method"), Deming and Stephan in 1940[7] for adjusting census crosstabulations, and G.V. Sheleikhovskii for traffic as reported by Bregman.[8] (Deming and Stephan proposed IPFP as an algorithm leading to a minimizer of the Pearson X-squared statistic, which Stephan later reported it does not).[9] Early proofs of uniqueness and convergence came from Sinkhorn (1964),[10] Bacharach (1965),[11] Bishop (1967),[12] and Fienberg (1970).[13] Bishop's proof that IPFP finds the maximum likelihood estimator for any number of dimensions extended a 1959 proof by Brown for 2x2x2... cases. Fienberg's proof by differential geometry exploits the method's constant crossproduct ratios, for strictly positive tables. Csiszár (1975).[14] found necessary and sufficient conditions for general tables having zero entries. Pukelsheim and Simeone (2009) [15] give further results on convergence and error behavior.
An exhaustive treatment of the algorithm and its mathematical foundations can be found in the book of Bishop et al. (1975).[16] Idel (2016)[17] gives a more recent survey.
Other general algorithms can be modified to yield the same limit as the IPFP, for instance the Newton–Raphson method and the EM algorithm. In most cases, IPFP is preferred due to its computational speed, low storage requirements, numerical stability and algebraic simplicity.
Applications of IPFP have grown to include trip distribution models, Fratar or Furness and other applications in transportation planning (Lamond and Stewart), survey weighting, synthesis of cross-classified demographic data, adjusting input–output models in economics, estimating expected quasi-independent contingency tables, biproportional apportionment systems of political representation, and for a preconditioner in linear algebra.[18]
Biproportion
Biproportion, whatever the algorithm used to solve it, is the following concept: , matrix and matrix are known real nonnegative matrices of dimension ; the interior of is unknown and is searched such that has the same margins than , i.e. and ( being the sum vector), and such that is closed to following a given criterion, the fitted matrix being of the form , where and are diagonal matrices.
s.t., ∀ and , ∀. The Lagrangian is .
Thus , for ∀,
which, after posing and , yields
, ∀, i.e., ,
with , ∀ and , ∀. and form a system that can be solve iteratively:
, ∀ and , ∀.
The solution is independent of the initialization chosen (i.e., we can begin by , ∀ or by , ∀. If the matrix is “indecomposable”, then this process has a unique fixed-point because it is deduced from program a program where the function is a convex and continuously derivable function defined on a compact set. In some cases the solution may not exist: see de Mesnard's example cited by Miller and Blair (Miller R.E. & Blair P.D. (2009) Input-output analysis: Foundations and Extensions, Second edition, Cambridge (UK): Cambridge University Press, p.335-336 (freely available)).
Some properties (see de Mesnard (1994)):
Lack of information: if brings no information, i.e., , ∀ then .
Idempotency: if has the same margins than .
Composition of biproportions: ; .
Zeros: a zero in is projected as a zero in . Thus, a bloc-diagonal matrix is projected as a bloc-diagonal matrix and a triangular matrix is projected as a triangular matrix.
Theorem of separable modifications: if is premutiplied by a diagonal matrix and/or postmultiplied by a diagonal matrix, then the solution is unchanged.
Theorem of "unicity": If is any non-specified algorithm, with , and being unknown, then and can always be changed into the standard form of and . The demonstrations calls some above properties, particularly the Theorem of separable modifications and the composition of biproportions.
Algorithm 1 (classical IPF)
Given a two-way (I×J)-table , we wish to estimate a new table for all i and j such that the marginals satisfy and .
Choose initial values , and for set
Repeat these steps until row and column totals are sufficiently close to u and v.
Notes:
For the RAS form of the algorithm, define the diagonalization operator , which produces a (diagonal) matrix with its input vector on the main diagonal and zero elsewhere. Then, for each row adjustment, let , from which . Similarly each column adjustment's , from which . Reducing the operations to the necessary ones, it can easily be seen that RAS does the same as classical IPF. In practice, one would not implement actual matrix multiplication with the whole R and S matrices; the RAS form is more a notational than computational convenience.
Algorithm 2 (factor estimation)
Assume the same setting as in the classical IPFP. Alternatively, we can estimate the row and column factors separately: Choose initial values , and for set
Repeat these steps until successive changes of a and b are sufficiently negligible (indicating the resulting row- and column-sums are close to u and v).
Finally, the result matrix is
Notes:
The two variants of the algorithm are mathematically equivalent, as can be seen by formal induction. With factor estimation, it is not necessary to actually compute each cycle's .
The factorization is not unique, since it is for all .
Discussion
The vaguely demanded 'similarity' between M and X can be explained as follows: IPFP (and thus RAS) maintains the crossproduct ratios, i.e.
since
This property is sometimes called structure conservation and directly leads to the geometrical interpretation of contingency tables and the proof of convergence in the seminal paper of Fienberg (1970).
Direct factor estimation (algorithm 2) is generally the more efficient way to solve IPF: Whereas a form of the classical IPFP needs
elementary operations in each iteration step (including a row and a column fitting step), factor estimation needs only
operations being at least one order in magnitude faster than classical IPFP.
IPFP can be used to estimate expected quasi-independent (incomplete) contingency tables, with , and for included cells and for excluded cells. For fully independent (complete) contingency tables, estimation with IPFP concludes exactly in one cycle.
Comparison with the NM-method
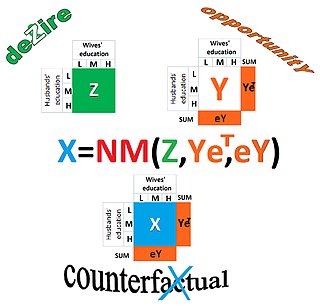
Similar to the IPF, the NM-method is also an operation of finding a matrix which is the “closest” to matrix () while its row totals and column totals are identical to those of a target matrix .
However, there are differences between the NM-method and the IPF. For instance, the NM-method defines closeness of matrices of the same size differently from the IPF.[19] Also, the NM-method was developed to solve for matrix in problems, where matrixis not a sample from the population characterized by the row totals and column totals of matrix , but represents another population.[19] In contrast, matrixis a sample from this population in problems where the IPF is applied as the maximum likelihood estimator.
Macdonald (2023)[20] is at ease with the conclusion by Naszodi (2023)[21] that the IPF is suitable for sampling correction tasks, but not for generation of counterfactuals. Similarly to Naszodi, Macdonald also questions whether the row and column proportional transformations of the IPF preserve the structure of association within a contingency table that allows us to study social mobility.
Existence and uniqueness of MLEs
Necessary and sufficient conditions for the existence and uniqueness of MLEs are complicated in the general case (see[22]), but sufficient conditions for 2-dimensional tables are simple:
the marginals of the observed table do not vanish (that is, ) and
the observed table is inseparable (i.e. the table does not permute to a block-diagonal shape).
If unique MLEs exist, IPFP exhibits linear convergence in the worst case (Fienberg 1970), but exponential convergence has also been observed (Pukelsheim and Simeone 2009). If a direct estimator (i.e. a closed form of ) exists, IPFP converges after 2 iterations. If unique MLEs do not exist, IPFP converges toward the so-called extended MLEs by design (Haberman 1974), but convergence may be arbitrarily slow and often computationally infeasible.
If all observed values are strictly positive, existence and uniqueness of MLEs and therefore convergence is ensured.
Example
Consider the following table, given with the row- and column-sums and targets.
1
2
3
4
TOTAL
TARGET
1
40
30
20
10
100
150
2
35
50
100
75
260
300
3
30
80
70
120
300
400
4
20
30
40
50
140
150
TOTAL
125
190
230
255
800
TARGET
200
300
400
100
1000
For executing the classical IPFP, we first adjust the rows:
1
2
3
4
TOTAL
TARGET
1
60.00
45.00
30.00
15.00
150.00
150
2
40.38
57.69
115.38
86.54
300.00
300
3
40.00
106.67
93.33
160.00
400.00
400
4
21.43
32.14
42.86
53.57
150.00
150
TOTAL
161.81
241.50
281.58
315.11
1000.00
TARGET
200
300
400
100
1000
The first step exactly matched row sums, but not the column sums. Next we adjust the columns:
1
2
3
4
TOTAL
TARGET
1
74.16
55.90
42.62
4.76
177.44
150
2
49.92
71.67
163.91
27.46
312.96
300
3
49.44
132.50
132.59
50.78
365.31
400
4
26.49
39.93
60.88
17.00
144.30
150
TOTAL
200.00
300.00
400.00
100.00
1000.00
TARGET
200
300
400
100
1000
Now the column sums exactly match their targets, but the row sums no longer match theirs. After completing three cycles, each with a row adjustment and a column adjustment, we get a closer approximation:
1
2
3
4
TOTAL
TARGET
1
64.61
46.28
35.42
3.83
150.13
150
2
49.95
68.15
156.49
25.37
299.96
300
3
56.70
144.40
145.06
53.76
399.92
400
4
28.74
41.18
63.03
17.03
149.99
150
TOTAL
200.00
300.00
400.00
100.00
1000.00
TARGET
200
300
400
100
1000
Implementation
The R package mipfp (currently in version 3.2) provides a multi-dimensional implementation of the traditional iterative proportional fitting procedure.[23] The package allows the updating of a N-dimensional array with respect to given target marginal distributions (which, in turn can be multi-dimensional).
Python has an equivalent package, ipfn[24][25] that can be installed via pip. The package supports numpy and pandas input objects.
In mathematical physics and mathematics, the Pauli matrices are a set of three 2 × 2 complex matrices that are Hermitian, involutory and unitary. Usually indicated by the Greek letter sigma, they are occasionally denoted by tau when used in connection with isospin symmetries.
In mathematics, particularly in linear algebra, matrix multiplication is a binary operation that produces a matrix from two matrices. For matrix multiplication, the number of columns in the first matrix must be equal to the number of rows in the second matrix. The resulting matrix, known as the matrix product, has the number of rows of the first and the number of columns of the second matrix. The product of matrices A and B is denoted as AB.
In linear algebra, the Cholesky decomposition or Cholesky factorization is a decomposition of a Hermitian, positive-definite matrix into the product of a lower triangular matrix and its conjugate transpose, which is useful for efficient numerical solutions, e.g., Monte Carlo simulations. It was discovered by André-Louis Cholesky for real matrices, and posthumously published in 1924. When it is applicable, the Cholesky decomposition is roughly twice as efficient as the LU decomposition for solving systems of linear equations.
In linear algebra, the permanent of a square matrix is a function of the matrix similar to the determinant. The permanent, as well as the determinant, is a polynomial in the entries of the matrix. Both are special cases of a more general function of a matrix called the immanant.
In special relativity, a four-vector is an object with four components, which transform in a specific way under Lorentz transformations. Specifically, a four-vector is an element of a four-dimensional vector space considered as a representation space of the standard representation of the Lorentz group, the representation. It differs from a Euclidean vector in how its magnitude is determined. The transformations that preserve this magnitude are the Lorentz transformations, which include spatial rotations and boosts.
In Hamiltonian mechanics, a canonical transformation is a change of canonical coordinates (q, p) → that preserves the form of Hamilton's equations. This is sometimes known as form invariance. Although Hamilton's equations are preserved, it need not preserve the explicit form of the Hamiltonian itself. Canonical transformations are useful in their own right, and also form the basis for the Hamilton–Jacobi equations and Liouville's theorem.
In mathematics, the determinant of an m×m skew-symmetric matrix can always be written as the square of a polynomial in the matrix entries, a polynomial with integer coefficients that only depends on m. When m is odd, the polynomial is zero. When m is even, it is a nonzero polynomial of degree m/2, and is unique up to multiplication by ±1. The convention on skew-symmetric tridiagonal matrices, given below in the examples, then determines one specific polynomial, called the Pfaffian polynomial. The value of this polynomial, when applied to the entries of a skew-symmetric matrix, is called the Pfaffian of that matrix. The term Pfaffian was introduced by Cayley, who indirectly named them after Johann Friedrich Pfaff.
In linear algebra, a rotation matrix is a transformation matrix that is used to perform a rotation in Euclidean space. For example, using the convention below, the matrix
Stochastic gradient descent is an iterative method for optimizing an objective function with suitable smoothness properties. It can be regarded as a stochastic approximation of gradient descent optimization, since it replaces the actual gradient by an estimate thereof. Especially in high-dimensional optimization problems this reduces the very high computational burden, achieving faster iterations in exchange for a lower convergence rate.
In the field of mathematics, norms are defined for elements within a vector space. Specifically, when the vector space comprises matrices, such norms are referred to as matrix norms. Matrix norms differ from vector norms in that they must also interact with matrix multiplication.
In mathematics, a Bézout matrix is a special square matrix associated with two polynomials, introduced by James Joseph Sylvester and Arthur Cayley and named after Étienne Bézout. Bézoutian may also refer to the determinant of this matrix, which is equal to the resultant of the two polynomials. Bézout matrices are sometimes used to test the stability of a given polynomial.
A logical matrix, binary matrix, relation matrix, Boolean matrix, or (0, 1)-matrix is a matrix with entries from the Boolean domain B = {0, 1}. Such a matrix can be used to represent a binary relation between a pair of finite sets. It is an important tool in combinatorial mathematics and theoretical computer science.
In mathematics, the classical groups are defined as the special linear groups over the reals , the complex numbers and the quaternions together with special automorphism groups of symmetric or skew-symmetric bilinear forms and Hermitian or skew-Hermitian sesquilinear forms defined on real, complex and quaternionic finite-dimensional vector spaces. Of these, the complex classical Lie groups are four infinite families of Lie groups that together with the exceptional groups exhaust the classification of simple Lie groups. The compact classical groups are compact real forms of the complex classical groups. The finite analogues of the classical groups are the classical groups of Lie type. The term "classical group" was coined by Hermann Weyl, it being the title of his 1939 monograph The Classical Groups.
In mathematics and mathematical physics, raising and lowering indices are operations on tensors which change their type. Raising and lowering indices are a form of index manipulation in tensor expressions.
In statistical mechanics, the eight-vertex model is a generalisation of the ice-type (six-vertex) models; it was discussed by Sutherland, and Fan & Wu, and solved by Baxter in the zero-field case.
Matrix completion is the task of filling in the missing entries of a partially observed matrix, which is equivalent to performing data imputation in statistics. A wide range of datasets are naturally organized in matrix form. One example is the movie-ratings matrix, as appears in the Netflix problem: Given a ratings matrix in which each entry represents the rating of movie by customer , if customer has watched movie and is otherwise missing, we would like to predict the remaining entries in order to make good recommendations to customers on what to watch next. Another example is the document-term matrix: The frequencies of words used in a collection of documents can be represented as a matrix, where each entry corresponds to the number of times the associated term appears in the indicated document.
In mathematics, Manin matrices, named after Yuri Manin who introduced them around 1987–88, are a class of matrices with elements in a not-necessarily commutative ring, which in a certain sense behave like matrices whose elements commute. In particular there is natural definition of the determinant for them and most linear algebra theorems like Cramer's rule, Cayley–Hamilton theorem, etc. hold true for them. Any matrix with commuting elements is a Manin matrix. These matrices have applications in representation theory in particular to Capelli's identity, Yangian and quantum integrable systems.
Symmetries in quantum mechanics describe features of spacetime and particles which are unchanged under some transformation, in the context of quantum mechanics, relativistic quantum mechanics and quantum field theory, and with applications in the mathematical formulation of the standard model and condensed matter physics. In general, symmetry in physics, invariance, and conservation laws, are fundamentally important constraints for formulating physical theories and models. In practice, they are powerful methods for solving problems and predicting what can happen. While conservation laws do not always give the answer to the problem directly, they form the correct constraints and the first steps to solving a multitude of problems. In application, understanding symmetries can also provide insights on the eigenstates that can be expected. For example, the existence of degenerate states can be inferred by the presence of non commuting symmetry operators or that the non degenerate states are also eigenvectors of symmetry operators.
In statistics, the class of vector generalized linear models (VGLMs) was proposed to enlarge the scope of models catered for by generalized linear models (GLMs). In particular, VGLMs allow for response variables outside the classical exponential family and for more than one parameter. Each parameter can be transformed by a link function. The VGLM framework is also large enough to naturally accommodate multiple responses; these are several independent responses each coming from a particular statistical distribution with possibly different parameter values.
The NM-method or Naszodi–Mendonca method is the operation that can be applied in statistics, econometrics, economics, sociology, and demography to construct counterfactual contingency tables. The method finds the matrix which is "closest" to matrix in the sense of being ranked the same but with the row and column totals of a target matrix. While the row totals and column totals of are known, matrix itself may not be known.
References
↑ Bacharach, M. (1965). "Estimating Nonnegative Matrices from Marginal Data". International Economic Review. 6 (3). Blackwell Publishing: 294–310. doi:10.2307/2525582. JSTOR2525582.
↑ Jaynes E.T. (1957) Information theory and statistical mechanics, Physical Review, 106: 620-30.
↑ Wilson A.G. (1970) Entropy in urban and regional modelling. London: Pion LTD, Monograph in spatial and environmental systems analysis.
↑ Kullback S. & Leibler R.A. (1951) On information and sufficiency, Annals of Mathematics and Statistics, 22 (1951) 79-86.
↑ Sinkhorn, Richard (1964). “A Relationship Between Arbitrary Positive Matrices and Doubly Stochastic Matrices”. In: Annals of Mathematical Statistics 35.2, pp. 876–879.
↑ Bacharach, Michael (1965). “Estimating Nonnegative Matrices from Marginal Data”. In: International Economic Review 6.3, pp. 294–310.
↑ Bishop, Y. M. M. (1967). “Multidimensional contingency tables: cell estimates”. PhD thesis. Harvard University.
↑ Martin Idel (2016) A review of matrix scaling and Sinkhorn’s normal form for matrices and positive maps arXiv preprint https://arxiv.org/pdf/1609.06349.pdf
↑ Bradley, A.M. (2010) Algorithms for the equilibration of matrices and their application to limited-memory quasi-newton methods. Ph.D. thesis, Institute for Computational and Mathematical Engineering, Stanford University, 2010
↑ Naszodi, A. (2023). "The iterative proportional fitting algorithm and the NM-method: solutions for two different sets of problems". arXiv:2303.05515 [econ.GN].
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.