Related Research Articles

In computing, a cache is a hardware or software component that stores data so that future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation or a copy of data stored elsewhere. When you request data, if it is found in the cache, it's called a "cache hit," and the data is retrieved faster. If the requested data is not found in the cache, it's called a "cache miss." Cache hits are served by reading data from the cache, which is faster than recomputing a result or reading from a slower data store; thus, the more requests that can be served from the cache, the faster the system performs.
In computer science, locality of reference, also known as the principle of locality, is the tendency of a processor to access the same set of memory locations repetitively over a short period of time. There are two basic types of reference locality – temporal and spatial locality. Temporal locality refers to the reuse of specific data and/or resources within a relatively small time duration. Spatial locality refers to the use of data elements within relatively close storage locations. Sequential locality, a special case of spatial locality, occurs when data elements are arranged and accessed linearly, such as traversing the elements in a one-dimensional array.
In computer science, algorithmic efficiency is a property of an algorithm which relates to the amount of computational resources used by the algorithm. An algorithm must be analyzed to determine its resource usage, and the efficiency of an algorithm can be measured based on the usage of different resources. Algorithmic efficiency can be thought of as analogous to engineering productivity for a repeating or continuous process.
In computer operating systems, memory paging is a memory management scheme by which a computer stores and retrieves data from secondary storage for use in main memory. In this scheme, the operating system retrieves data from secondary storage in same-size blocks called pages. Paging is an important part of virtual memory implementations in modern operating systems, using secondary storage to let programs exceed the size of available physical memory.
In a computer operating system that uses paging for virtual memory management, page replacement algorithms decide which memory pages to page out, sometimes called swap out, or write to disk, when a page of memory needs to be allocated. Page replacement happens when a requested page is not in memory and a free page cannot be used to satisfy the allocation, either because there are none, or because the number of free pages is lower than some threshold.
A CPU cache is a hardware cache used by the central processing unit (CPU) of a computer to reduce the average cost to access data from the main memory. A cache is a smaller, faster memory, located closer to a processor core, which stores copies of the data from frequently used main memory locations. Most CPUs have a hierarchy of multiple cache levels, with different instruction-specific and data-specific caches at level 1. The cache memory is typically implemented with static random-access memory (SRAM), in modern CPUs by far the largest part of them by chip area, but SRAM is not always used for all levels, or even any level, sometimes some latter or all levels are implemented with eDRAM.
In computing, cache algorithms are optimizing instructions, or algorithms, that a computer program or a hardware-maintained structure can utilize in order to manage a cache of information stored on the computer. Caching improves performance by keeping recent or often-used data items in memory locations that are faster or computationally cheaper to access than normal memory stores. When the cache is full, the algorithm must choose which items to discard to make room for the new ones.
In computing, a cache-oblivious algorithm is an algorithm designed to take advantage of a processor cache without having the size of the cache as an explicit parameter. An optimal cache-oblivious algorithm is a cache-oblivious algorithm that uses the cache optimally. Thus, a cache-oblivious algorithm is designed to perform well, without modification, on multiple machines with different cache sizes, or for a memory hierarchy with different levels of cache having different sizes. Cache-oblivious algorithms are contrasted with explicit loop tiling, which explicitly breaks a problem into blocks that are optimally sized for a given cache.
Hierarchical storage management (HSM), also known as Tiered storage, is a data storage and Data management technique that automatically moves data between high-cost and low-cost storage media. HSM systems exist because high-speed storage devices, such as solid state drive arrays, are more expensive than slower devices, such as hard disk drives, optical discs and magnetic tape drives. While it would be ideal to have all data available on high-speed devices all the time, this is prohibitively expensive for many organizations. Instead, HSM systems store the bulk of the enterprise's data on slower devices, and then copy data to faster disk drives when needed. The HSM system monitors the way data is used and makes best guesses as to which data can safely be moved to slower devices and which data should stay on the fast devices.
Working set is a concept in computer science which defines the amount of memory that a process requires in a given time interval.
Cache pollution describes situations where an executing computer program loads data into CPU cache unnecessarily, thus causing other useful data to be evicted from the cache into lower levels of the memory hierarchy, degrading performance. For example, in a multi-core processor, one core may replace the blocks fetched by other cores into shared cache, or prefetched blocks may replace demand-fetched blocks from the cache.
Adaptive Replacement Cache (ARC) is a page replacement algorithm with better performance than LRU. This is accomplished by keeping track of both frequently used and recently used pages plus a recent eviction history for both. The algorithm was developed at the IBM Almaden Research Center. In 2006, IBM was granted a patent for the adaptive replacement cache policy.
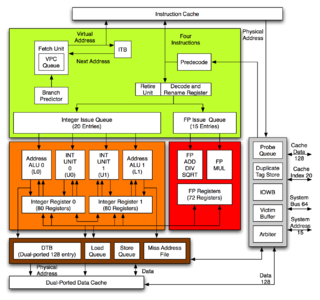
The Alpha 21264 is a Digital Equipment Corporation RISC microprocessor launched on 19 October 1998. The 21264 implemented the Alpha instruction set architecture (ISA).
Electronic systems’ power consumption has been a real challenge for Hardware and Software designers as well as users especially in portable devices like cell phones and laptop computers. Power consumption also has been an issue for many industries that use computer systems heavily such as Internet service providers using servers or companies with many employees using computers and other computational devices. Many different approaches have been discovered by researchers to estimate power consumption efficiently. This survey paper focuses on the different methods where power consumption can be estimated or measured in real-time.
LIRS is a page replacement algorithm with an improved performance over LRU and many other newer replacement algorithms. This is achieved by using "reuse distance" as the locality metric for dynamically ranking accessed pages to make a replacement decision.
Row hammer is a security exploit that takes advantage of an unintended and undesirable side effect in dynamic random-access memory (DRAM) in which memory cells interact electrically between themselves by leaking their charges, possibly changing the contents of nearby memory rows that were not addressed in the original memory access. This circumvention of the isolation between DRAM memory cells results from the high cell density in modern DRAM, and can be triggered by specially crafted memory access patterns that rapidly activate the same memory rows numerous times.
Power consumption is becoming increasingly important for both embedded, mobile computing and high-performance systems. Off-chip data bus consumes a significant part of system power. It is observed that the off-chip data bus consumes between 9.8% and 23.2% of the total power consumed by the system depending on the system. So, reducing the power consumption of the off-chip data bus would reduce the overall power consumption.
Cache prefetching is a technique used by computer processors to boost execution performance by fetching instructions or data from their original storage in slower memory to a faster local memory before it is actually needed. Most modern computer processors have fast and local cache memory in which prefetched data is held until it is required. The source for the prefetch operation is usually main memory. Because of their design, accessing cache memories is typically much faster than accessing main memory, so prefetching data and then accessing it from caches is usually many orders of magnitude faster than accessing it directly from main memory. Prefetching can be done with non-blocking cache control instructions.
A CPU cache is a piece of hardware that reduces access time to data in memory by keeping some part of the frequently used data of the main memory in a 'cache' of smaller and faster memory.
In computing, cache algorithms are optimizing instructions—or algorithms—that a computer program or a hardware-maintained structure can follow in order to manage a cache of information stored on the computer. When the cache is full, the algorithm must choose which items to discard to make room for the new ones. Due to the inherent caching capability of nodes in Information-centric networking ICN, the ICN can be viewed as a loosely connect network of caches, which has unique requirements of Caching policies. Unlike proxy servers, in Information-centric networking the cache is a network level solution. Therefore, it has rapidly changing cache states and higher request arrival rates; moreover, smaller cache sizes further impose different kind of requirements on the content eviction policies. In particular, eviction policies for Information-centric networking should be fast and lightweight. Various cache replication and eviction schemes for different Information-centric networking architectures and applications are proposed.
References
- ↑ Donghee Lee; Jongmoo Choi; Jong-Hun Kim; Noh, S.H.; Sang Lyul Min; Yookun Cho; Chong Sang Kim. LRFU: a spectrum of policies that subsumes the least recently used and least frequently used policies. IEEE Transactions on Computers
- ↑ Silvano Maffeis. Cache Management Algorithms for Flexible Filesystems. ACM SIGMETRICS Performance Evaluation Review, Vol. 21, No. 3
- ↑ William Stallings. Operating Systems: Internals and Design Principles 7th Edition. 2012
- ↑ B.T. Zivkoz and A.J. Smith. Disk Caching in Large Database and Timeshared Systems. IEEE MASCOTS, 1997