Mark Johannes van der Laan, Ph.D is a Dutch-American biostatistician. He is currently a Professor of Biostatistics and Statistics at the University of California, Berkeley, where he holds the position of the Jiann-Ping Hsu/Karl E. Peace Endowed Chair in Biostatistics. He has made contributions to survival analysis, semiparametric statistics, multiple testing, and causal inference.[4] He also developed the targeted maximum likelihood estimation methodology. He is a founding editor of the Journal of Causal Inference. Developed in response to challenges dealing with the curse of dimensionality and the complexity of real-world data, Targeted Learning is subfield of statistics applicable across a variety of applications, including the analysis of clinical trials, assessment of (causal) effects in observational and real-world evidence studies, and the analysis of high-dimensional and multi-modal data.
Van der Laan was born on July 4, 1967 in the Netherlands, son of Ann and Paul van der Laan, a professor of Statistics. During his youth, he was a competitive chess and tennis player. He also exhibited an early interest in mathematics and statistics, and pursued a joint bachelor’s and master's degree in Mathematics at the University of Utrecht, specializing in Statistics. During his master’s studies, he spent a year at North Carolina State University, Raleigh, studying at the Department of Statistics and playing on the university’s tennis team.
Mark’s master's thesis, guided by Professor Richard D. Gill, focused on the Dabrowska Estimator and the Functional Delta method. Van der Laan furthered his education at the Department of Mathematics at Utrecht University, as a doctoral student under Professor Richard D. Gill, and completed part of his research at the University of California, Berkeley, under Professor Peter J. Bickel. His doctoral thesis, "Efficient Estimation in the Bivariate Censoring Model," was defended in 1993.
A highlight of Van der Laan’s thesis is the development of the first efficient estimator of the bivariate survival function based on bivariate right-censored failure time data. The main idea was to regularize the nonparametric maximum likelihood estimator (NPMLE) through artificial extra censoring. This work was further generalized to develop the first regularized NPMLE of a full-data distribution based on general censored data. Another key contribution was an identity for the NPMLE that allowed for an elegant proof of asymptotic efficiency of the NPMLE under minimal conditions. Specifically, for an NPMLE in any censored data problem with censoring satisfying the coarsening at random assumption, we have the following identity:
where is the canonical gradient (i.e., a score) of the pathwise derivative of at , which is also called the efficient influence curve. The proof of asymptotic efficiency is now immediate based on empirical process theory. That is, we only need to show that falls in a Donsker class such as the class of multivariate cadlag functions with a universal bound on the sectional variation norm, and that we already have consistency in the sense that the norm of converges to zero in probability. In fact, the latter consistency can already be derived from the identity and the Donsker class assumption since the identity can be applied to any pathwise differentiable target feature (e.g., survival function at any point in its domain) giving an rate of convergence of for a class of target features .
Then, we have shown that
and thereby asymptotic linearity and efficiency of the NPMLE for target feature . Applying this uniformly for a class of pathwise differentiable features, then also provides asymptotic efficiency for functional parameters such as a survival function of the underlying failure times.
Career
Van der Laan's academic career began at the University of California, Berkeley in 1994 as an Assistant Professor of Biostatistics. He ascended through the ranks to become a full Professor in 2000, holding joint appointments in the School of Public Health and the Department of Statistics. He served as the Chair of the Group of Biostatistics from 2018 to 2024. Since its inception in 2020, he has been the co-Director of the Center for Targeted Machine Learning and Causal Inference (CTML) at the University of California, Berkeley. Van der Laan is also the co-founder of TL Revolution, an enterprise consulting and software solutions company, grounded in Targeted Learning.
Mark J. van der Laan's research is extensive and interdisciplinary, combining rigorous statistical theory with innovative applications and causal inference. His contributions embody a profound commitment to advancing statistical science in the service of public health and medical research. They have not only enriched the field of biostatistics but have also had a tangible impact on the broader scientific community. Van der Laan’s contributions can be divided into several key areas:
1. Development of Statistical Methodologies:
Van der Laan has pioneered in developing statistical methodologies aimed at analyzing high-dimensional censored longitudinal data derived from observational, real-world data studies and randomized clinical trials. His work is characterized by the development and application of semiparametric statistical theory to solve problems in complex data structures arising in the real world.
2. Causal Inference:
He has made substantial contributions to the field of causal inference, particularly in the context of longitudinal studies. Van der Laan's research in this area has focused on developing methods that account for informative treatment assignment and informative censoring, which are common challenges in clinical and epidemiological research.
3. Adaptive Designs and Surveillance Systems:
Van der Laan has been instrumental in advancing adaptive designs within clinical trials. His research includes the development of targeted adaptive designs with corresponding targeted maximum likelihood estimators that allow for more flexible and efficient trial designs, while preserving the robust unbiased inference of RCTs, thereby enhancing the ability to make timely and accurate decisions during the trial process.
4. Machine Learning Algorithms:
Among his notable contributions is the development of the Highly Adaptive Lasso (HAL) algorithm. HAL represents a new class of machine learning algorithms that has remarkable theoretical statistical properties, such as dimension free rates of convergence, pointwise asymptotic normality and asymptotic efficiency for plug-in estimation of smooth features of the target function. It has shown promise in many applications, including data-driven prediction models, conditional density estimation, conditional treatment effect estimation, intensity estimation, and variable selection in high-dimensional and multi-modal data settings.
5. Targeted Learning:
Perhaps one of Van der Laan's most significant contributions is the development of Targeted Learning, a framework that combines the strengths of machine learning and traditional statistical inference. The cornerstone of this approach is the Targeted Maximum Likelihood Estimation (TMLE), which provides a robust, flexible methodology for estimating causal effects and parameters in complex models. This approach is designed to reduce bias and improve efficiency, making it particularly suitable for observational data and complex longitudinal studies.
6. Collaborative Research and Software Development:
Van der Laan actively engages in collaborative research, working with interdisciplinary scientists across the world to apply Targeted Learning to real-world problems. He has also contributed to the development of several software packages and publicly available educational materials, making his methodologies accessible to a wider research community.
Honors and awards
Throughout his career, Van der Laan has received numerous awards and honors, including the Mortimer Spiegelman Award for outstanding contributions to health statistics; the van Dantzig Prize, the highest award in Statistics and Decision Theory in the Netherlands; and the COPSS Presidents' Award for outstanding contributions to the statistics profession. His work has been recognized globally, with invitations to keynote talks and lectureships worldwide. He received the COPSS Presidents' Award in 2005, the Mortimer Spiegelman Award in 2004, and the van Dantzig Award in 2005.[5][6]
Most Recent Publications:
Year
Authors
Title
Journal/Conference
DOI/URL (if available)
2021
A. Benitez, ML Petersen, MJ van der Laan, N Santos
Comparative methods for the analysis of cluster randomized trials
arXiv preprint arXiv:2110.09633
Link
2021
I Malenica, RV Phillips, R Pirracchio, A Chambaz, MJ van der Laan
Personalized Online Machine Learning
Under revision for Statistics in Medicine
https://arxiv.org/abs/2109.10452
2021
CJ Kennedy, DG Mark, J Huang, MJ van der Laan
Development of an ensemble machine learning prognostic model to predict 60-day risk of major adverse cardiac events in adults with chest pain
To be submitted to MedRxiv
2020
MJ van der Laan
Highly Adaptive Lasso technical report
University of California Berkeley
2018
MJ van der Laan, I Malenica
Robust Estimation of Data-Dependent Causal Effects based on Observing a Single Time-Series
arXiv preprint arXiv:1809.00734
Link
2017
Mark van der Laan
A generally efficient TMLE with the Highly Adaptive Lasso
Mark J. van der Laan, Eric C. Polley, Alan E. Hubbard
Super Learner
Statistical Applications in Genetics and Molecular Biology, volume 6, issue 1.
https://biostats.bepress.com/ucbbiostat/paper222/
2006
Mark J. van der Laan, Daniel Rubin
Targeted Maximum Likelihood Learning
UC Berkeley Division of Biostatistics Working Paper Series
https://biostats.bepress.com/ucbbiostat/paper213/
For all of Mark van der Laan’s work, please visit his Google Scholar.
Teaching and Mentorship
As an educator, Van der Laan has taught a wide range of courses at UC Berkeley, from introductory statistics, survival analysis, adaptive designs, multiple testing, to advanced statistical theory and causal inference. He has mentored over 55 Ph.D. students and 20 postdoctoral fellows, many of whom have gone on to make significant contributions in academia, industry, and public health.
Related Research Articles
In statistics, an estimator is a rule for calculating an estimate of a given quantity based on observed data: thus the rule, the quantity of interest and its result are distinguished. For example, the sample mean is a commonly used estimator of the population mean.
Econometrics is an application of statistical methods to economic data in order to give empirical content to economic relationships. More precisely, it is "the quantitative analysis of actual economic phenomena based on the concurrent development of theory and observation, related by appropriate methods of inference." An introductory economics textbook describes econometrics as allowing economists "to sift through mountains of data to extract simple relationships." Jan Tinbergen is one of the two founding fathers of econometrics. The other, Ragnar Frisch, also coined the term in the sense in which it is used today.
Statistical inference is the process of using data analysis to infer properties of an underlying distribution of probability. Inferential statistical analysis infers properties of a population, for example by testing hypotheses and deriving estimates. It is assumed that the observed data set is sampled from a larger population.
In statistics, the Lehmann–Scheffé theorem is a prominent statement, tying together the ideas of completeness, sufficiency, uniqueness, and best unbiased estimation. The theorem states that any estimator that is unbiased for a given unknown quantity and that depends on the data only through a complete, sufficient statistic is the unique best unbiased estimator of that quantity. The Lehmann–Scheffé theorem is named after Erich Leo Lehmann and Henry Scheffé, given their two early papers.
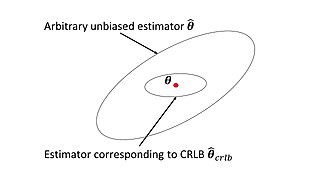
In estimation theory and statistics, the Cramér–Rao bound (CRB) relates to estimation of a deterministic parameter. The result is named in honor of Harald Cramér and C. R. Rao, but has also been derived independently by Maurice Fréchet, Georges Darmois, and by Alexander Aitken and Harold Silverstone. It is also known as Fréchet-Cramér–Rao or Fréchet-Darmois-Cramér-Rao lower bound. It states that the precision of any unbiased estimator is at most the Fisher information; or (equivalently) the reciprocal of the Fisher information is a lower bound on its variance.
In statistics, kernel density estimation (KDE) is the application of kernel smoothing for probability density estimation, i.e., a non-parametric method to estimate the probability density function of a random variable based on kernels as weights. KDE answers a fundamental data smoothing problem where inferences about the population are made based on a finite data sample. In some fields such as signal processing and econometrics it is also termed the Parzen–Rosenblatt window method, after Emanuel Parzen and Murray Rosenblatt, who are usually credited with independently creating it in its current form. One of the famous applications of kernel density estimation is in estimating the class-conditional marginal densities of data when using a naive Bayes classifier, which can improve its prediction accuracy.
Robust statistics are statistics which maintain their properties even if the underlying distributional assumptions are incorrect. Robust statistical methods have been developed for many common problems, such as estimating location, scale, and regression parameters. One motivation is to produce statistical methods that are not unduly affected by outliers. Another motivation is to provide methods with good performance when there are small departures from a parametric distribution. For example, robust methods work well for mixtures of two normal distributions with different standard deviations; under this model, non-robust methods like a t-test work poorly.
In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares and maximum likelihood estimation are special cases of M-estimators. The definition of M-estimators was motivated by robust statistics, which contributed new types of M-estimators. However, M-estimators are not inherently robust, as is clear from the fact that they include maximum likelihood estimators, which are in general not robust. The statistical procedure of evaluating an M-estimator on a data set is called M-estimation.
James M. Robins is an epidemiologist and biostatistician best known for advancing methods for drawing causal inferences from complex observational studies and randomized trials, particularly those in which the treatment varies with time. He is the 2013 recipient of the Nathan Mantel Award for lifetime achievement in statistics and epidemiology, and a recipient of the 2022 Rousseeuw Prize in Statistics, jointly with Miguel Hernán, Eric Tchetgen-Tchetgen, Andrea Rotnitzky and Thomas Richardson.
In statistics, redescending M-estimators are Ψ-type M-estimators which have ψ functions that are non-decreasing near the origin, but decreasing toward 0 far from the origin. Their ψ functions can be chosen to redescend smoothly to zero, so that they usually satisfy ψ(x) = 0 for all x with |x| > r, where r is referred to as the minimum rejection point.
In medical research, a dynamic treatment regime (DTR), adaptive intervention, or adaptive treatment strategy is a set of rules for choosing effective treatments for individual patients. Historically, medical research and the practice of medicine tended to rely on an acute care model for the treatment of all medical problems, including chronic illness. Treatment choices made for a particular patient under a dynamic regime are based on that individual's characteristics and history, with the goal of optimizing his or her long-term clinical outcome. A dynamic treatment regime is analogous to a policy in the field of reinforcement learning, and analogous to a controller in control theory. While most work on dynamic treatment regimes has been done in the context of medicine, the same ideas apply to time-varying policies in other fields, such as education, marketing, and economics.
Minimum-distance estimation (MDE) is a conceptual method for fitting a statistical model to data, usually the empirical distribution. Often-used estimators such as ordinary least squares can be thought of as special cases of minimum-distance estimation.
In statistics, Hodges' estimator, named for Joseph Hodges, is a famous counterexample of an estimator which is "superefficient", i.e. it attains smaller asymptotic variance than regular efficient estimators. The existence of such a counterexample is the reason for the introduction of the notion of regular estimators.
Kernel density estimation is a nonparametric technique for density estimation i.e., estimation of probability density functions, which is one of the fundamental questions in statistics. It can be viewed as a generalisation of histogram density estimation with improved statistical properties. Apart from histograms, other types of density estimators include parametric, spline, wavelet and Fourier series. Kernel density estimators were first introduced in the scientific literature for univariate data in the 1950s and 1960s and subsequently have been widely adopted. It was soon recognised that analogous estimators for multivariate data would be an important addition to multivariate statistics. Based on research carried out in the 1990s and 2000s, multivariate kernel density estimation has reached a level of maturity comparable to its univariate counterparts.
In Bayesian inference, the Bernstein–von Mises theorem provides the basis for using Bayesian credible sets for confidence statements in parametric models. It states that under some conditions, a posterior distribution converges in the limit of infinite data to a multivariate normal distribution centered at the maximum likelihood estimator with covariance matrix given by , where is the true population parameter and is the Fisher information matrix at the true population parameter value:
In statistics, the g-prior is an objective prior for the regression coefficients of a multiple regression. It was introduced by Arnold Zellner. It is a key tool in Bayes and empirical Bayes variable selection.
Dorota Maria Dabrowska is a Polish statistician known for applying nonparametric statistics and semiparametric models to counting processes and survival analysis. Dabrowska's estimator, from her paper "Kaplan–Meier estimate on the plane" is a widely used tool for bivariate survival under random censoring.
Sherri Rose is an American biostatistician. She is an associate professor of health care policy at Stanford University, and once worked at Harvard University. A fellow of the American Statistical Association, she has served as co-editor of Biostatistics since 2019 and Chair of the American Statistical Association’s Biometrics Section. Her research focuses on statistical machine learning for health care policy.
In statistics, a sequence of random variables is homoscedastic if all its random variables have the same finite variance; this is also known as homogeneity of variance. The complementary notion is called heteroscedasticity, also known as heterogeneity of variance. The spellings homoskedasticity and heteroskedasticity are also frequently used. Skedasticity comes from the Ancient Greek word skedánnymi, meaning “to scatter”. Assuming a variable is homoscedastic when in reality it is heteroscedastic results in unbiased but inefficient point estimates and in biased estimates of standard errors, and may result in overestimating the goodness of fit as measured by the Pearson coefficient.
Regular estimators are a class of statistical estimators that satisfy certain regularity conditions which make them amenable to asymptotic analysis. The convergence of a regular estimator's distribution is, in a sense, locally uniform. This is often considered desirable and leads to the convenient property that a small change in the parameter does not dramatically change the distribution of the estimator.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.