In probability theory and statistics, variance is the expectation of the squared deviation of a random variable from its population mean or sample mean. Variance is a measure of dispersion, meaning it is a measure of how far a set of numbers is spread out from their average value. Variance has a central role in statistics, where some ideas that use it include descriptive statistics, statistical inference, hypothesis testing, goodness of fit, and Monte Carlo sampling. Variance is an important tool in the sciences, where statistical analysis of data is common. The variance is the square of the standard deviation, the second central moment of a distribution, and the covariance of the random variable with itself, and it is often represented by , , , , or .

In statistics, correlation or dependence is any statistical relationship, whether causal or not, between two random variables or bivariate data. Although in the broadest sense, "correlation" may indicate any type of association, in statistics it normally refers to the degree to which a pair of variables are linearly related. Familiar examples of dependent phenomena include the correlation between the height of parents and their offspring, and the correlation between the price of a good and the quantity the consumers are willing to purchase, as it is depicted in the so-called demand curve.

In statistics, the Pearson correlation coefficient ― also known as Pearson's r, the Pearson product-moment correlation coefficient (PPMCC), the bivariate correlation, or colloquially simply as the correlation coefficient ― is a measure of linear correlation between two sets of data. It is the ratio between the covariance of two variables and the product of their standard deviations; thus, it is essentially a normalized measurement of the covariance, such that the result always has a value between −1 and 1. As with covariance itself, the measure can only reflect a linear correlation of variables, and ignores many other types of relationships or correlations. As a simple example, one would expect the age and height of a sample of teenagers from a high school to have a Pearson correlation coefficient significantly greater than 0, but less than 1.

In statistics, Spearman's rank correlation coefficient or Spearman's ρ, named after Charles Spearman and often denoted by the Greek letter (rho) or as , is a nonparametric measure of rank correlation. It assesses how well the relationship between two variables can be described using a monotonic function.
In statistics and psychometrics, reliability is the overall consistency of a measure. A measure is said to have a high reliability if it produces similar results under consistent conditions:
"It is the characteristic of a set of test scores that relates to the amount of random error from the measurement process that might be embedded in the scores. Scores that are highly reliable are precise, reproducible, and consistent from one testing occasion to another. That is, if the testing process were repeated with a group of test takers, essentially the same results would be obtained. Various kinds of reliability coefficients, with values ranging between 0.00 and 1.00, are usually used to indicate the amount of error in the scores."
In the social sciences, scaling is the process of measuring or ordering entities with respect to quantitative attributes or traits. For example, a scaling technique might involve estimating individuals' levels of extraversion, or the perceived quality of products. Certain methods of scaling permit estimation of magnitudes on a continuum, while other methods provide only for relative ordering of the entities.

In statistics, canonical-correlation analysis (CCA), also called canonical variates analysis, is a way of inferring information from cross-covariance matrices. If we have two vectors X = (X1, ..., Xn) and Y = (Y1, ..., Ym) of random variables, and there are correlations among the variables, then canonical-correlation analysis will find linear combinations of X and Y which have maximum correlation with each other. T. R. Knapp notes that "virtually all of the commonly encountered parametric tests of significance can be treated as special cases of canonical-correlation analysis, which is the general procedure for investigating the relationships between two sets of variables." The method was first introduced by Harold Hotelling in 1936, although in the context of angles between flats the mathematical concept was published by Jordan in 1875.
Cronbach's alpha, also known as tau-equivalent reliability or coefficient alpha, is a reliability coefficient that provides a method of measuring internal consistency of tests.
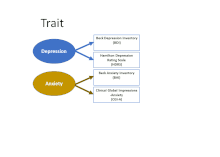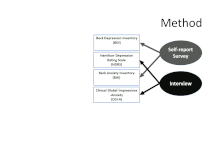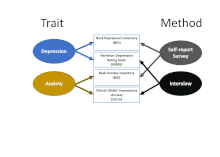
Construct validity is the accumulation of evidence to support the interpretation of what a measure reflects. Modern validity theory defines construct validity as the overarching concern of validity research, subsuming all other types of validity evidence such as content validity and criterion validity.
Linear discriminant analysis (LDA), normal discriminant analysis (NDA), or discriminant function analysis is a generalization of Fisher's linear discriminant, a method used in statistics and other fields, to find a linear combination of features that characterizes or separates two or more classes of objects or events. The resulting combination may be used as a linear classifier, or, more commonly, for dimensionality reduction before later classification.
Personality Assessment Inventory (PAI), developed by Leslie Morey, is a self-report 344-item personality test that assesses a respondent's personality and psychopathology. Each item is a statement about the respondent that the respondent rates with a 4-point scale. It is used in various contexts, including psychotherapy, crisis/evaluation, forensic, personnel selection, pain/medical, and child custody assessment. The test construction strategy for the PAI was primarily deductive and rational. It shows good convergent validity with other personality tests, such as the Minnesota Multiphasic Personality Inventory and the Revised NEO Personality Inventory.
Convergent validity, for human cognition, especially within sociology, psychology, and other behavioral sciences, refers to the degree to which two measures that theoretically should be related, are in fact related. Convergent validity, along with discriminant validity, is a subtype of construct validity. Convergent validity can be established if two similar constructs correspond with one another, while discriminant validity applies to two dissimilar constructs that are easily differentiated.
In psychology, discriminant validity tests whether concepts or measurements that are not supposed to be related are actually unrelated.
In probability theory and statistics, partial correlation measures the degree of association between two random variables, with the effect of a set of controlling random variables removed. If we are interested in finding to what extent there is a numerical relationship between two variables of interest, using their correlation coefficient will give misleading results if there is another, confounding, variable that is numerically related to both variables of interest. This misleading information can be avoided by controlling for the confounding variable, which is done by computing the partial correlation coefficient. This is precisely the motivation for including other right-side variables in a multiple regression; but while multiple regression gives unbiased results for the effect size, it does not give a numerical value of a measure of the strength of the relationship between the two variables of interest.
In statistics, confirmatory factor analysis (CFA) is a special form of factor analysis, most commonly used in social research. It is used to test whether measures of a construct are consistent with a researcher's understanding of the nature of that construct. As such, the objective of confirmatory factor analysis is to test whether the data fit a hypothesized measurement model. This hypothesized model is based on theory and/or previous analytic research. CFA was first developed by Jöreskog (1969) and has built upon and replaced older methods of analyzing construct validity such as the MTMM Matrix as described in Campbell & Fiske (1959).
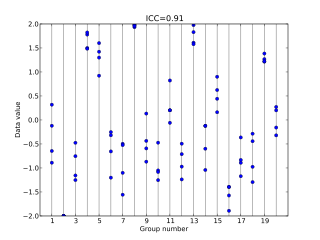
In statistics, the intraclass correlation, or the intraclass correlation coefficient (ICC), is a descriptive statistic that can be used when quantitative measurements are made on units that are organized into groups. It describes how strongly units in the same group resemble each other. While it is viewed as a type of correlation, unlike most other correlation measures it operates on data structured as groups, rather than data structured as paired observations.
Multivariate analysis of covariance (MANCOVA) is an extension of analysis of covariance (ANCOVA) methods to cover cases where there is more than one dependent variable and where the control of concomitant continuous independent variables – covariates – is required. The most prominent benefit of the MANCOVA design over the simple MANOVA is the 'factoring out' of noise or error that has been introduced by the covariant. A commonly used multivariate version of the ANOVA F-statistic is Wilks' Lambda (Λ), which represents the ratio between the error variance and the effect variance.
The person–situation debate in personality psychology refers to the controversy concerning whether the person or the situation is more influential in determining a person's behavior. Personality trait psychologists believe that a person's personality is relatively consistent across situations. Situationists, opponents of the trait approach, argue that people are not consistent enough from situation to situation to be characterized by broad personality traits. The debate is also an important discussion when studying social psychology, as both topics address the various ways a person could react to a given situation.

In statistics, average variance extracted (AVE) is a measure of the amount of variance that is captured by a construct in relation to the amount of variance due to measurement error.

In statistics, a sequence of random variables is homoscedastic if all its random variables have the same finite variance. This is also known as homogeneity of variance. The complementary notion is called heteroscedasticity. The spellings homoskedasticity and heteroskedasticity are also frequently used.