Related Research Articles
Biostatistics is a branch of statistics that applies statistical methods to a wide range of topics in biology. It encompasses the design of biological experiments, the collection and analysis of data from those experiments and the interpretation of the results.

Statistics is the discipline that concerns the collection, organization, analysis, interpretation, and presentation of data. In applying statistics to a scientific, industrial, or social problem, it is conventional to begin with a statistical population or a statistical model to be studied. Populations can be diverse groups of people or objects such as "all people living in a country" or "every atom composing a crystal". Statistics deals with every aspect of data, including the planning of data collection in terms of the design of surveys and experiments.

Meta-analysis is the statistical combination of the results of multiple studies addressing a similar research question. An important part of this method involves computing an effect size across all of the studies, this involves extracting effect sizes and variance measures from various studies. Meta-analyses are integral in supporting research grant proposals, shaping treatment guidelines, and influencing health policies. They are also pivotal in summarizing existing research to guide future studies, thereby cementing their role as a fundamental methodology in metascience. Meta-analyses are often, but not always, important components of a systematic review procedure. For instance, a meta-analysis may be conducted on several clinical trials of a medical treatment, in an effort to obtain a better understanding of how well the treatment works.
A cohort study is a particular form of longitudinal study that samples a cohort, performing a cross-section at intervals through time. It is a type of panel study where the individuals in the panel share a common characteristic.
In statistics, an effect size is a value measuring the strength of the relationship between two variables in a population, or a sample-based estimate of that quantity. It can refer to the value of a statistic calculated from a sample of data, the value of a parameter for a hypothetical population, or to the equation that operationalizes how statistics or parameters lead to the effect size value. Examples of effect sizes include the correlation between two variables, the regression coefficient in a regression, the mean difference, or the risk of a particular event happening. Effect sizes complement statistical hypothesis testing, and play an important role in power analyses, sample size planning, and in meta-analyses. The cluster of data-analysis methods concerning effect sizes is referred to as estimation statistics.
In published academic research, publication bias occurs when the outcome of an experiment or research study biases the decision to publish or otherwise distribute it. Publishing only results that show a significant finding disturbs the balance of findings in favor of positive results. The study of publication bias is an important topic in metascience.
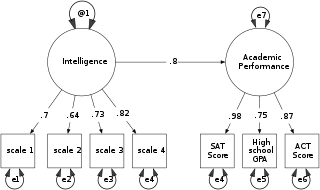
Structural equation modeling (SEM) is a diverse set of methods used by scientists doing both observational and experimental research. SEM is used mostly in the social and behavioral sciences but it is also used in epidemiology, business, and other fields. A definition of SEM is difficult without reference to technical language, but a good starting place is the name itself.
In robust statistics, robust regression seeks to overcome some limitations of traditional regression analysis. A regression analysis models the relationship between one or more independent variables and a dependent variable. Standard types of regression, such as ordinary least squares, have favourable properties if their underlying assumptions are true, but can give misleading results otherwise. Robust regression methods are designed to limit the effect that violations of assumptions by the underlying data-generating process have on regression estimates.
In statistics, unit-weighted regression is a simplified and robust version of multiple regression analysis where only the intercept term is estimated. That is, it fits a model
In statistics, a generalized estimating equation (GEE) is used to estimate the parameters of a generalized linear model with a possible unmeasured correlation between observations from different timepoints. Although some believe that Generalized estimating equations are robust in everything even with the wrong choice of working-correlation matrix, Generalized estimating equations are only robust to loss of consistency with the wrong choice.
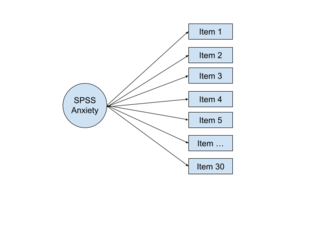
In multivariate statistics, exploratory factor analysis (EFA) is a statistical method used to uncover the underlying structure of a relatively large set of variables. EFA is a technique within factor analysis whose overarching goal is to identify the underlying relationships between measured variables. It is commonly used by researchers when developing a scale and serves to identify a set of latent constructs underlying a battery of measured variables. It should be used when the researcher has no a priori hypothesis about factors or patterns of measured variables. Measured variables are any one of several attributes of people that may be observed and measured. Examples of measured variables could be the physical height, weight, and pulse rate of a human being. Usually, researchers would have a large number of measured variables, which are assumed to be related to a smaller number of "unobserved" factors. Researchers must carefully consider the number of measured variables to include in the analysis. EFA procedures are more accurate when each factor is represented by multiple measured variables in the analysis.
Anil K. Bera is an Indian-American econometrician. He is Professor of Economics at University of Illinois at Urbana–Champaign's Department of Economics. He is most noted for his work with Carlos Jarque on the Jarque–Bera test.
Causal inference is the process of determining the independent, actual effect of a particular phenomenon that is a component of a larger system. The main difference between causal inference and inference of association is that causal inference analyzes the response of an effect variable when a cause of the effect variable is changed. The study of why things occur is called etiology, and can be described using the language of scientific causal notation. Causal inference is said to provide the evidence of causality theorized by causal reasoning.

The replication crisis is an ongoing methodological crisis in which the results of many scientific studies are difficult or impossible to reproduce. Because the reproducibility of empirical results is an essential part of the scientific method, such failures undermine the credibility of theories building on them and potentially call into question substantial parts of scientific knowledge.

Power posing is a controversial self-improvement technique or "life hack" in which people stand in a posture that they mentally associate with being powerful, in the hope of feeling more confident and behaving more assertively. Though the underlying science is disputed, its promoters continue to argue that people can foster positive life changes simply by assuming a "powerful" or "expansive" posture for a few minutes before an interaction in which confidence is needed. One popular image of the technique in practice is that of candidates "lock[ing] themselves in bathroom stalls before job interviews to make victory V's with their arms."
Researcher degrees of freedom is a concept referring to the inherent flexibility involved in the process of designing and conducting a scientific experiment, and in analyzing its results. The term reflects the fact that researchers can choose between multiple ways of collecting and analyzing data, and these decisions can be made either arbitrarily or because they, unlike other possible choices, produce a positive and statistically significant result. The researcher degrees of freedom has positives such as affording the ability to look at nature from different angles, allowing new discoveries and hypotheses to be generated. However, researcher degrees of freedom can lead to data dredging and other questionable research practices where the different interpretations and analyses are taken for granted Their widespread use represents an inherent methodological limitation in scientific research, and contributes to an inflated rate of false-positive findings. They can also lead to overestimated effect sizes.
HARKing is an acronym coined by social psychologist Norbert Kerr that refers to the questionable research practice of "presenting a post hoc hypothesis in the introduction of a research report as if it were an a priori hypothesis". Hence, a key characteristic of HARKing is that post hoc hypothesizing is falsely portrayed as a priori hypothesizing. HARKing may occur when a researcher tests an a priori hypothesis but then omits that hypothesis from their research report after they find out the results of their test; inappropriate forms of post hoc analysis or post hoc theorizing then may lead to a post hoc hypothesis.

In statistics, a sequence of random variables is homoscedastic if all its random variables have the same finite variance; this is also known as homogeneity of variance. The complementary notion is called heteroscedasticity, also known as heterogeneity of variance. The spellings homoskedasticity and heteroskedasticity are also frequently used. Assuming a variable is homoscedastic when in reality it is heteroscedastic results in unbiased but inefficient point estimates and in biased estimates of standard errors, and may result in overestimating the goodness of fit as measured by the Pearson coefficient.
The garden of forking paths is a problem in frequentist hypothesis testing through which researchers can unintentionally produce false positives for a tested hypothesis, through leaving themselves too many degrees of freedom. In contrast to fishing expeditions such as data dredging where only expected or apparently-significant results are published, this allows for a similar effect even when only one experiment is run, through a series of choices about how to implement methods and analyses, which are themselves informed by the data as it is observed and processed.
References
- ↑ Steegen, Sara; Tuerlinckx, Francis; Gelman, Andrew; Vanpaemel, Wolf (September 2016). "Increasing Transparency Through a Multiverse Analysis". Perspectives on Psychological Science. 11 (5): 702–712. doi: 10.1177/1745691616658637 .
- ↑ Breznau, Nate; et al. (28 October 2022). "Observing many researchers using the same data and hypothesis reveals a hidden universe of uncertainty". Proceedings of the National Academy of Sciences. 119 (44). doi: 10.1073/pnas.2203150119 . hdl: 2066/285367 .
- ↑ Wicherts, Jelte M.; Veldkamp, Coosje L. S.; Augusteijn, Hilde E. M.; Bakker, Marjan; van Aert, Robbie C. M.; van Assen, Marcel A. L. M. (2016). "Degrees of Freedom in Planning, Running, Analyzing, and Reporting Psychological Studies: A Checklist to Avoid p-Hacking". Frontiers in Psychology. 7: 1832. doi: 10.3389/fpsyg.2016.01832 . PMC 5122713 . PMID 27933012.
- ↑ Harder, Jenna A. (2020). "The Multiverse of Methods: Extending the Multiverse Analysis to Address Data-Collection Decisions". Perspectives on Psychological Science. 15 (5): 1158–1177. doi:10.1177/1745691620917678. ISSN 1745-6916.
- ↑ Clayson, Peter E. (2024-03-01). "Beyond single paradigms, pipelines, and outcomes: Embracing multiverse analyses in psychophysiology". International Journal of Psychophysiology. 197: 112311. doi:10.1016/j.ijpsycho.2024.112311. ISSN 0167-8760.
- ↑ Jung, Kiju; Shavitt, Sharon; Viswanathan, Madhu; Hilbe, Joseph M. (17 June 2014). "Female hurricanes are deadlier than male hurricanes". Proceedings of the National Academy of Sciences. 111 (24): 8782–8787. doi: 10.1073/pnas.1402786111 . PMC 4066510 . PMID 24889620.
- ↑ Muñoz, John; Young, Cristobal (August 2018). "We Ran 9 Billion Regressions: Eliminating False Positives through Computational Model Robustness". Sociological Methodology. 48 (1): 1–33. doi: 10.1177/0081175018777988 .
- ↑ Rohrer, Julia M.; Egloff, Boris; Schmukle, Stefan C. (December 2017). "Probing Birth-Order Effects on Narrow Traits Using Specification-Curve Analysis". Psychological Science. 28 (12): 1821–1832. doi:10.1177/0956797617723726.