Related Research Articles
A document type definition (DTD) is a set of markup declarations that define a document type for an SGML-family markup language.
The HyperText Markup Language or HTML is the standard markup language for documents designed to be displayed in a web browser. It can be assisted by technologies such as Cascading Style Sheets (CSS) and scripting languages such as JavaScript.

Markup refers to data included in an electronic document which is distinct from the document's content in that it is typically not included in representations of the document for end users, for example on paper or a computer screen, or in an audio stream. Markup is often used to control the display of the document or to enrich its content to facilitate automated processing. A markup language is a set of rules governing what markup information may be included in a document and how it is combined with the content of the document in a way to facilitate use by humans and computer programs. The idea and terminology evolved from the "marking up" of paper manuscripts, which is traditionally written with a red pen or blue pencil on authors' manuscripts.
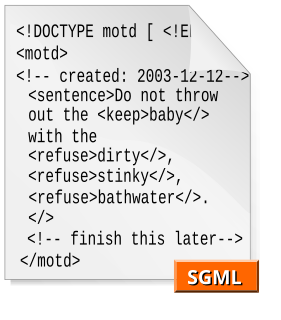
The Standard Generalized Markup Language is a standard for defining generalized markup languages for documents. ISO 8879 Annex A.1 states that generalized markup is "based on two postulates":
Extensible Markup Language (XML) is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.
DocBook is a semantic markup language for technical documentation. It was originally intended for writing technical documents related to computer hardware and software, but it can be used for any other sort of documentation.
SAX is an event-driven online algorithm for parsing XML documents, with an API developed by the XML-DEV mailing list. SAX provides a mechanism for reading data from an XML document that is an alternative to that provided by the Document Object Model (DOM). Where the DOM operates on the document as a whole—building the full abstract syntax tree of an XML document for convenience of the user—SAX parsers operate on each piece of the XML document sequentially, issuing parsing events while making a single pass through the input stream.
An HTML element is a type of HTML document component, one of several types of HTML nodes. HTML document is composed of a tree of simple HTML nodes, such as text nodes, and HTML elements, which add semantics and formatting to parts of document. Each element can have HTML attributes specified. Elements can also have content, including other elements and text.
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part.
In web development, "tag soup" is a pejorative for syntactically or structurally incorrect HTML written for a web page. Because web browsers have historically treated HTML syntax or structural errors leniently, there has been little pressure for web developers to follow published standards, and therefore there is a need for all browser implementations to provide mechanisms to cope with the appearance of "tag soup", accepting and correcting for invalid syntax and structure where possible.
The Text Encoding Initiative (TEI) is a text-centric community of practice in the academic field of digital humanities, operating continuously since the 1980s. The community currently runs a mailing list, meetings and conference series, and maintains the TEI technical standard, a journal, a wiki, a GitHub repository and a toolchain.
A lightweight markup language (LML), also termed a simple or humane markup language, is a markup language with simple, unobtrusive syntax. It is designed to be easy to write using any generic text editor and easy to read in its raw form. Lightweight markup languages are used in applications where it may be necessary to read the raw document as well as the final rendered output.
An XML schema is a description of a type of XML document, typically expressed in terms of constraints on the structure and content of documents of that type, above and beyond the basic syntactical constraints imposed by XML itself. These constraints are generally expressed using some combination of grammatical rules governing the order of elements, Boolean predicates that the content must satisfy, data types governing the content of elements and attributes, and more specialized rules such as uniqueness and referential integrity constraints.
In computer science, canonicalization is a process for converting data that has more than one possible representation into a "standard", "normal", or canonical form. This can be done to compare different representations for equivalence, to count the number of distinct data structures, to improve the efficiency of various algorithms by eliminating repeated calculations, or to make it possible to impose a meaningful sorting order.
In the Standard Generalized Markup Language (SGML), an entity is a primitive data type, which associates a string with either a unique alias or an SGML reserved word. Entities are foundational to the organizational structure and definition of SGML documents. The SGML specification defines numerous entity types, which are distinguished by keyword qualifiers and context. An entity string value may variously consist of plain text, SGML tags, and/or references to previously defined entities. Certain entity types may also invoke external documents. Entities are called by reference.
The term CDATA, meaning character data, is used for distinct, but related, purposes in the markup languages SGML and XML. The term indicates that a certain portion of the document is general character data, rather than non-character data or character data with a more specific, limited structure.
A Canonical S-expression is a binary encoding form of a subset of general S-expression. It was designed for use in SPKI to retain the power of S-expressions and ensure canonical form for applications such as digital signatures while achieving the compactness of a binary form and maximizing the speed of parsing.
Extensible HyperText Markup Language (XHTML) is part of the family of XML markup languages. It mirrors or extends versions of the widely used HyperText Markup Language (HTML), the language in which Web pages are formulated.
In computing, a polyglot markup is a document or script written in a valid form of multiple markup languages, which performs the same output, independent of the markup's parser, layout engine, or interpreter. In general, the polyglot markup is a common subset of two or more languages, that can be used as a robust or simplified profile.
A document type declaration, or DOCTYPE, is an instruction that associates a particular XML or SGML document with a document type definition (DTD). In the serialized form of the document, it manifests as a short string of markup that conforms to a particular syntax.
References
- ↑ "Welcome to the OmniMark 11.0 documentation". OmniMark Developer Resources. Retrieved 26 July 2022.
- ↑ Stilo International (2004). Beginner's Guide to OmniMark (PDF). p. 3. Retrieved 24 September 2018.
- ↑ Travis, Brian L. (1997). OmniMark at work: Getting Started. Englewood, CO: SGML University Press. p. vii.
- ↑ "Office Locations". Stilo. Retrieved 24 September 2018.
- ↑ "OmniMark 5 is Free". Cover Pages. Retrieved 24 September 2018.