
In the mathematical field of numerical analysis, interpolation is a type of estimation, a method of constructing (finding) new data points based on the range of a discrete set of known data points.

In the mathematical subfield of numerical analysis, a B-spline or basis spline is a spline function that has minimal support with respect to a given degree, smoothness, and domain partition. Any spline function of given degree can be expressed as a linear combination of B-splines of that degree. Cardinal B-splines have knots that are equidistant from each other. B-splines can be used for curve-fitting and numerical differentiation of experimental data.
In mathematics, a polynomial is an expression consisting of indeterminates and coefficients, that involves only the operations of addition, subtraction, multiplication, and non-negative integer exponentiation of variables. An example of a polynomial of a single indeterminate x is x2 − 4x + 7. An example in three variables is x3 + 2xyz2 − yz + 1.

In mathematics, differential calculus is a subfield of calculus that studies the rates at which quantities change. It is one of the two traditional divisions of calculus, the other being integral calculus—the study of the area beneath a curve.

In calculus, Taylor's theorem gives an approximation of a k-times differentiable function around a given point by a polynomial of degree k, called the kth-order Taylor polynomial. For a smooth function, the Taylor polynomial is the truncation at the order k of the Taylor series of the function. The first-order Taylor polynomial is the linear approximation of the function, and the second-order Taylor polynomial is often referred to as the quadratic approximation. There are several versions of Taylor's theorem, some giving explicit estimates of the approximation error of the function by its Taylor polynomial.
In mathematics and computing, a root-finding algorithm is an algorithm for finding zeros, also called "roots", of continuous functions. A zero of a function f, from the real numbers to real numbers or from the complex numbers to the complex numbers, is a number x such that f(x) = 0. As, generally, the zeros of a function cannot be computed exactly nor expressed in closed form, root-finding algorithms provide approximations to zeros, expressed either as floating-point numbers or as small isolating intervals, or disks for complex roots.

In mathematics, linear interpolation is a method of curve fitting using linear polynomials to construct new data points within the range of a discrete set of known data points.

In analysis, numerical integration comprises a broad family of algorithms for calculating the numerical value of a definite integral, and by extension, the term is also sometimes used to describe the numerical solution of differential equations. This article focuses on calculation of definite integrals.

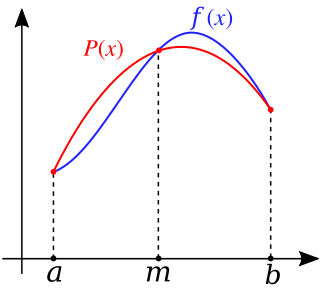
In the mathematical field of numerical analysis, Runge's phenomenon is a problem of oscillation at the edges of an interval that occurs when using polynomial interpolation with polynomials of high degree over a set of equispaced interpolation points. It was discovered by Carl David Tolmé Runge (1901) when exploring the behavior of errors when using polynomial interpolation to approximate certain functions. The discovery was important because it shows that going to higher degrees does not always improve accuracy. The phenomenon is similar to the Gibbs phenomenon in Fourier series approximations.
In numerical analysis, polynomial interpolation is the interpolation of a given data set by the polynomial of lowest possible degree that passes through the points of the dataset.
In numerical integration, Simpson's rules are several approximations for definite integrals, named after Thomas Simpson (1710–1761).
An approximation is anything that is intentionally similar but not exactly equal to something else.
In mathematics and statistics, a piecewise linear, PL or segmented function is a real-valued function of a real variable, whose graph is composed of straight-line segments.
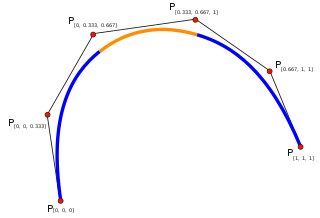
In mathematics, a spline is a special function defined piecewise by polynomials. In interpolating problems, spline interpolation is often preferred to polynomial interpolation because it yields similar results, even when using low degree polynomials, while avoiding Runge's phenomenon for higher degrees.

In mathematics, extrapolation is a type of estimation, beyond the original observation range, of the value of a variable on the basis of its relationship with another variable. It is similar to interpolation, which produces estimates between known observations, but extrapolation is subject to greater uncertainty and a higher risk of producing meaningless results. Extrapolation may also mean extension of a method, assuming similar methods will be applicable. Extrapolation may also apply to human experience to project, extend, or expand known experience into an area not known or previously experienced so as to arrive at a knowledge of the unknown. The extrapolation method can be applied in the interior reconstruction problem.

Curve fitting is the process of constructing a curve, or mathematical function, that has the best fit to a series of data points, possibly subject to constraints. Curve fitting can involve either interpolation, where an exact fit to the data is required, or smoothing, in which a "smooth" function is constructed that approximately fits the data. A related topic is regression analysis, which focuses more on questions of statistical inference such as how much uncertainty is present in a curve that is fit to data observed with random errors. Fitted curves can be used as an aid for data visualization, to infer values of a function where no data are available, and to summarize the relationships among two or more variables. Extrapolation refers to the use of a fitted curve beyond the range of the observed data, and is subject to a degree of uncertainty since it may reflect the method used to construct the curve as much as it reflects the observed data.
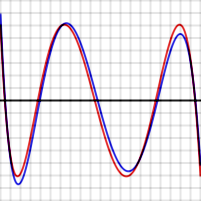
In mathematics, approximation theory is concerned with how functions can best be approximated with simpler functions, and with quantitatively characterizing the errors introduced thereby. Note that what is meant by best and simpler will depend on the application.

A Savitzky–Golay filter is a digital filter that can be applied to a set of digital data points for the purpose of smoothing the data, that is, to increase the precision of the data without distorting the signal tendency. This is achieved, in a process known as convolution, by fitting successive sub-sets of adjacent data points with a low-degree polynomial by the method of linear least squares. When the data points are equally spaced, an analytical solution to the least-squares equations can be found, in the form of a single set of "convolution coefficients" that can be applied to all data sub-sets, to give estimates of the smoothed signal, at the central point of each sub-set. The method, based on established mathematical procedures, was popularized by Abraham Savitzky and Marcel J. E. Golay, who published tables of convolution coefficients for various polynomials and sub-set sizes in 1964. Some errors in the tables have been corrected. The method has been extended for the treatment of 2- and 3-dimensional data.
Clenshaw–Curtis quadrature and Fejér quadrature are methods for numerical integration, or "quadrature", that are based on an expansion of the integrand in terms of Chebyshev polynomials. Equivalently, they employ a change of variables and use a discrete cosine transform (DCT) approximation for the cosine series. Besides having fast-converging accuracy comparable to Gaussian quadrature rules, Clenshaw–Curtis quadrature naturally leads to nested quadrature rules, which is important for both adaptive quadrature and multidimensional quadrature (cubature).
In numerical analysis, Gauss–Legendre quadrature is a form of Gaussian quadrature for approximating the definite integral of a function. For integrating over the interval [−1, 1], the rule takes the form:








