
Computer data storage is a technology consisting of computer components and recording media that are used to retain digital data. It is a core function and fundamental component of computers.
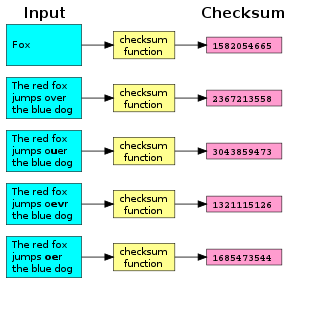
A checksum is a small-sized block of data derived from another block of digital data for the purpose of detecting errors that may have been introduced during its transmission or storage. By themselves, checksums are often used to verify data integrity but are not relied upon to verify data authenticity.

In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
A cyclic redundancy check (CRC) is an error-detecting code commonly used in digital networks and storage devices to detect accidental changes to digital data. Blocks of data entering these systems get a short check value attached, based on the remainder of a polynomial division of their contents. On retrieval, the calculation is repeated and, in the event the check values do not match, corrective action can be taken against data corruption. CRCs can be used for error correction.
In computer science and telecommunication, Hamming codes are a family of linear error-correcting codes. Hamming codes can detect one-bit and two-bit errors, or correct one-bit errors without detection of uncorrected errors. By contrast, the simple parity code cannot correct errors, and can detect only an odd number of bits in error. Hamming codes are perfect codes, that is, they achieve the highest possible rate for codes with their block length and minimum distance of three. Richard W. Hamming invented Hamming codes in 1950 as a way of automatically correcting errors introduced by punched card readers. In his original paper, Hamming elaborated his general idea, but specifically focused on the Hamming(7,4) code which adds three parity bits to four bits of data.
In telecommunication, a longitudinal redundancy check (LRC), or horizontal redundancy check, is a form of redundancy check that is applied independently to each of a parallel group of bit streams. The data must be divided into transmission blocks, to which the additional check data is added.
RAID is a data storage virtualization technology that combines multiple physical disk drive components into one or more logical units for the purposes of data redundancy, performance improvement, or both. This is in contrast to the previous concept of highly reliable mainframe disk drives referred to as "single large expensive disk" (SLED).
The data link layer, or layer 2, is the second layer of the seven-layer OSI model of computer networking. This layer is the protocol layer that transfers data between nodes on a network segment across the physical layer. The data link layer provides the functional and procedural means to transfer data between network entities and may also provide the means to detect and possibly correct errors that can occur in the physical layer.

Coding theory is the study of the properties of codes and their respective fitness for specific applications. Codes are used for data compression, cryptography, error detection and correction, data transmission and data storage. Codes are studied by various scientific disciplines—such as information theory, electrical engineering, mathematics, linguistics, and computer science—for the purpose of designing efficient and reliable data transmission methods. This typically involves the removal of redundancy and the correction or detection of errors in the transmitted data.

Data corruption refers to errors in computer data that occur during writing, reading, storage, transmission, or processing, which introduce unintended changes to the original data. Computer, transmission, and storage systems use a number of measures to provide end-to-end data integrity, or lack of errors.
In coding theory, an erasure code is a forward error correction (FEC) code under the assumption of bit erasures, which transforms a message of k symbols into a longer message with n symbols such that the original message can be recovered from a subset of the n symbols. The fraction r = k/n is called the code rate. The fraction k’/k, where k’ denotes the number of symbols required for recovery, is called reception efficiency. The recovery algorithm expects that it is known which of the n symbols are lost — unlike forward error correction codes.
XOR gate is a digital logic gate that gives a true output when the number of true inputs is odd. An XOR gate implements an exclusive or from mathematical logic; that is, a true output results if one, and only one, of the inputs to the gate is true. If both inputs are false (0/LOW) or both are true, a false output results. XOR represents the inequality function, i.e., the output is true if the inputs are not alike otherwise the output is false. A way to remember XOR is "must have one or the other but not both".
Binary Synchronous Communication is an IBM character-oriented, half-duplex link protocol, announced in 1967 after the introduction of System/360. It replaced the synchronous transmit-receive (STR) protocol used with second generation computers. The intent was that common link management rules could be used with three different character encodings for messages.
In computer main memory, auxiliary storage and computer buses, data redundancy is the existence of data that is additional to the actual data and permits correction of errors in stored or transmitted data. The additional data can simply be a complete copy of the actual data, or only select pieces of data that allow detection of errors and reconstruction of lost or damaged data up to a certain level.
In computer storage, the standard RAID levels comprise a basic set of RAID configurations that employ the techniques of striping, mirroring, or parity to create large reliable data stores from multiple general-purpose computer hard disk drives (HDDs). The most common types are RAID 0 (striping), RAID 1 (mirroring) and its variants, RAID 5, and RAID 6. Multiple RAID levels can also be combined or nested, for instance RAID 10 or RAID 01. RAID levels and their associated data formats are standardized by the Storage Networking Industry Association (SNIA) in the Common RAID Disk Drive Format (DDF) standard. The numerical values only serve as identifiers and do not signify performance, reliability, generation, or any other metric.
Although all RAID implementations differ from the specification to some extent, some companies and open-source projects have developed non-standard RAID implementations that differ substantially from the standard. Additionally, there are non-RAID drive architectures, providing configurations of multiple hard drives not referred to by RAID acronyms.
The cyclic redundancy check (CRC) is based on division in the ring of polynomials over the finite field GF(2), that is, the set of polynomials where each coefficient is either zero or one, and arithmetic operations wrap around.

Computation of a cyclic redundancy check is derived from the mathematics of polynomial division, modulo two. In practice, it resembles long division of the binary message string, with a fixed number of zeroes appended, by the "generator polynomial" string except that exclusive or operations replace subtractions. Division of this type is efficiently realised in hardware by a modified shift register, and in software by a series of equivalent algorithms, starting with simple code close to the mathematics and becoming faster through byte-wise parallelism and space–time tradeoffs.
A parity drive is a hard drive used in a RAID array to provide fault tolerance. For example, RAID 3 uses a parity drive to create a system that is both fault tolerant and, because of data striping, fast. Basically, a single data bit is added to the end of a data block to ensure the number of bits in the message is either odd or even.
ZFS is a file system with volume management capabilities. It began as part of the Sun Microsystems Solaris operating system in 2001. Large parts of Solaris – including ZFS – were published under an open source license as OpenSolaris for around 5 years from 2005 before being placed under a closed source license when Oracle Corporation acquired Sun in 2009–2010. During 2005 to 2010, the open source version of ZFS was ported to Linux, Mac OS X and FreeBSD. In 2010, the illumos project forked a recent version of OpenSolaris, including ZFS, to continue its development as an open source project. In 2013, OpenZFS was founded to coordinate the development of open source ZFS. OpenZFS maintains and manages the core ZFS code, while organizations using ZFS maintain the specific code and validation processes required for ZFS to integrate within their systems. OpenZFS is widely used in Unix-like systems.