Related Research Articles
In computer science, mutual exclusion is a property of concurrency control, which is instituted for the purpose of preventing race conditions. It is the requirement that one thread of execution never enters a critical section while a concurrent thread of execution is already accessing critical section, which refers to an interval of time during which a thread of execution accesses a shared resource, such as [Shared data objects, shared resources, shared memory].
In computer science, ACID is a set of properties of database transactions intended to guarantee data validity despite errors, power failures, and other mishaps. In the context of databases, a sequence of database operations that satisfies the ACID properties is called a transaction. For example, a transfer of funds from one bank account to another, even involving multiple changes such as debiting one account and crediting another, is a single transaction.
In computing, a computer program or subroutine is called reentrant if multiple invocations can safely run concurrently on a single processor system, where a reentrant procedure can be interrupted in the middle of its execution and then safely be called again ("re-entered") before its previous invocations complete execution. The interruption could be caused by an internal action such as a jump or call, or by an external action such as an interrupt or signal, unlike recursion, where new invocations can only be caused by internal call.
In computer science, a lock or mutex is a synchronization primitive: a mechanism that enforces limits on access to a resource when there are many threads of execution. A lock is designed to enforce a mutual exclusion concurrency control policy, and with a variety of possible methods there exists multiple unique implementations for different applications.
In computer science, read-copy-update (RCU) is a synchronization mechanism that avoids the use of lock primitives while multiple threads concurrently read and update elements that are linked through pointers and that belong to shared data structures.
In computer science, an algorithm is called non-blocking if failure or suspension of any thread cannot cause failure or suspension of another thread; for some operations, these algorithms provide a useful alternative to traditional blocking implementations. A non-blocking algorithm is lock-free if there is guaranteed system-wide progress, and wait-free if there is also guaranteed per-thread progress. "Non-blocking" was used as a synonym for "lock-free" in the literature until the introduction of obstruction-freedom in 2003.
In computer science, compare-and-swap (CAS) is an atomic instruction used in multithreading to achieve synchronization. It compares the contents of a memory location with a given value and, only if they are the same, modifies the contents of that memory location to a new given value. This is done as a single atomic operation. The atomicity guarantees that the new value is calculated based on up-to-date information; if the value had been updated by another thread in the meantime, the write would fail. The result of the operation must indicate whether it performed the substitution; this can be done either with a simple boolean response, or by returning the value read from the memory location.
In computing, a persistent data structure or not ephemeral data structure is a data structure that always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure. The term was introduced in Driscoll, Sarnak, Sleator, and Tarjans' 1986 article.
In computer programming, particularly in the C, C++, C#, and Java programming languages, the volatile keyword indicates that a value may change between different accesses, even if it does not appear to be modified. This keyword prevents an optimizing compiler from optimizing away subsequent reads or writes and thus incorrectly reusing a stale value or omitting writes. Volatile values primarily arise in hardware access, where reading from or writing to memory is used to communicate with peripheral devices, and in threading, where a different thread may have modified a value.

In concurrent programming, an operation is linearizable if it consists of an ordered list of invocation and response events (callbacks), that may be extended by adding response events such that:
- The extended list can be re-expressed as a sequential history.
- That sequential history is a subset of the original unextended list.
In computer science, software transactional memory (STM) is a concurrency control mechanism analogous to database transactions for controlling access to shared memory in concurrent computing. It is an alternative to lock-based synchronization. STM is a strategy implemented in software, rather than as a hardware component. A transaction in this context occurs when a piece of code executes a series of reads and writes to shared memory. These reads and writes logically occur at a single instant in time; intermediate states are not visible to other (successful) transactions. The idea of providing hardware support for transactions originated in a 1986 paper by Tom Knight. The idea was popularized by Maurice Herlihy and J. Eliot B. Moss. In 1995 Nir Shavit and Dan Touitou extended this idea to software-only transactional memory (STM). Since 2005, STM has been the focus of intense research and support for practical implementations is growing.
In a multithreaded computing environment, hazard pointers are one approach to solving the problems posed by dynamic memory management of the nodes in a lock-free data structure. These problems generally arise only in environments that don't have automatic garbage collection.
The Zope Object Database (ZODB) is an object-oriented database for transparently and persistently storing Python objects. It is included as part of the Zope web application server, but can also be used independently of Zope.
The Java programming language and the Java virtual machine (JVM) have been designed to support concurrent programming, and all execution takes place in the context of threads. Objects and resources can be accessed by many separate threads; each thread has its own path of execution but can potentially access any object in the program. The programmer must ensure read and write access to objects is properly coordinated between threads. Thread synchronization ensures that objects are modified by only one thread at a time and that threads are prevented from accessing partially updated objects during modification by another thread. The Java language has built-in constructs to support this coordination.
Memory ordering describes the order of accesses to computer memory by a CPU. The term can refer either to the memory ordering generated by the compiler during compile time, or to the memory ordering generated by a CPU during runtime.
In multithreaded computing, the ABA problem occurs during synchronization, when a location is read twice, has the same value for both reads, and "value is the same" is used to indicate "nothing has changed". However, another thread can execute between the two reads and change the value, do other work, then change the value back, thus fooling the first thread into thinking "nothing has changed" even though the second thread did work that violates that assumption.
A concurrent hash-trie or Ctrie is a concurrent thread-safe lock-free implementation of a hash array mapped trie. It is used to implement the concurrent map abstraction. It has particularly scalable concurrent insert and remove operations and is memory-efficient. It is the first known concurrent data-structure that supports O(1), atomic, lock-free snapshots.
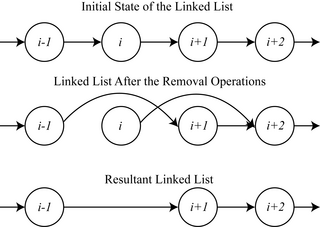
A non-blocking linked list is an example of non-blocking data structures designed to implement a linked list in shared memory using synchronization primitives:
The Java programming language's Java Collections Framework version 1.5 and later defines and implements the original regular single-threaded Maps, and also new thread-safe Maps implementing the java.util.concurrent.ConcurrentMapinterface among other concurrent interfaces. In Java 1.6, the java.util.NavigableMap interface was added, extending java.util.SortedMap, and the java.util.concurrent.ConcurrentNavigableMap interface was added as a subinterface combination.
The NOVA file system is an open-source, log-structured file system for byte-addressable persistent memory for Linux.
References
- ↑ Satish M. Thatte. 1986. Persistent memory: a storage architecture for object-oriented database systems. In Proceedings on the 1986 international workshop on Object-oriented database systems (OODS '86). IEEE Computer Society Press, Los Alamitos, CA, USA, 148-159.
- ↑ P. Mehra and S. Fineberg, "Fast and flexible persistence: the magic potion for fault-tolerance, scalability and performance in online data stores," 18th International Parallel and Distributed Processing Symposium, 2004. Proceedings., Santa Fe, NM, USA, 2004, pp. 206-. doi: 10.1109/IPDPS.2004.1303232
- ↑ Wang, William; Diestelhorst, Stephan (June 17, 2019). "Persistent Atomics for Implementing Durable Lock-Free Data Structures for Non-Volatile Memory (Brief Announcement)". Association for Computing Machinery. pp. 309–311. doi:10.1145/3323165.3323166 – via ACM Digital Library.
- ↑ Wolczko, Mario (April 26, 2019). "Non-Volatile Memory and Java: Part 2". Medium.