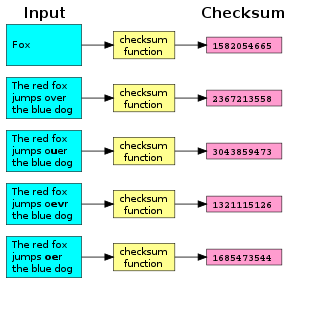
A checksum is a small-sized block of data derived from another block of digital data for the purpose of detecting errors that may have been introduced during its transmission or storage. By themselves, checksums are often used to verify data integrity but are not relied upon to verify data authenticity.

A hash function is any function that can be used to map data of arbitrary size to fixed-size values, though there are some hash functions that support variable length output. The values returned by a hash function are called hash values, hash codes, hash digests, digests, or simply hashes. The values are usually used to index a fixed-size table called a hash table. Use of a hash function to index a hash table is called hashing or scatter storage addressing.

In cryptography, an HMAC is a specific type of message authentication code (MAC) involving a cryptographic hash function and a secret cryptographic key. As with any MAC, it may be used to simultaneously verify both the data integrity and authenticity of a message. An HMAC is a type of keyed hash function that can also be used in a key derivation scheme or a key stretching scheme.
The MD5 message-digest algorithm is a widely used hash function producing a 128-bit hash value. MD5 was designed by Ronald Rivest in 1991 to replace an earlier hash function MD4, and was specified in 1992 as RFC 1321.
A cyclic redundancy check (CRC) is an error-detecting code commonly used in digital networks and storage devices to detect accidental changes to digital data. Blocks of data entering these systems get a short check value attached, based on the remainder of a polynomial division of their contents. On retrieval, the calculation is repeated and, in the event the check values do not match, corrective action can be taken against data corruption. CRCs can be used for error correction.
In computer science, a one-way function is a function that is easy to compute on every input, but hard to invert given the image of a random input. Here, "easy" and "hard" are to be understood in the sense of computational complexity theory, specifically the theory of polynomial time problems. Not being one-to-one is not considered sufficient for a function to be called one-way.
A commitment scheme is a cryptographic primitive that allows one to commit to a chosen value while keeping it hidden to others, with the ability to reveal the committed value later. Commitment schemes are designed so that a party cannot change the value or statement after they have committed to it: that is, commitment schemes are binding. Commitment schemes have important applications in a number of cryptographic protocols including secure coin flipping, zero-knowledge proofs, and secure computation.

A cryptographic hash function (CHF) is a hash algorithm that has special properties desirable for a cryptographic application:
In computer science and cryptography, Whirlpool is a cryptographic hash function. It was designed by Vincent Rijmen and Paulo S. L. M. Barreto, who first described it in 2000.
KCDSA is a digital signature algorithm created by a team led by the Korea Internet & Security Agency (KISA). It is an ElGamal variant, similar to the Digital Signature Algorithm and GOST R 34.10-94. The standard algorithm is implemented over , but an elliptic curve variant (EC-KCDSA) is also specified.
Fowler–Noll–Vo is a non-cryptographic hash function created by Glenn Fowler, Landon Curt Noll, and Kiem-Phong Vo.
In cryptography, a verifiable random function (VRF) is a public-key pseudorandom function that provides proofs that its outputs were calculated correctly. The owner of the secret key can compute the function value as well as an associated proof for any input value. Everyone else, using the proof and the associated public key, can check that this value was indeed calculated correctly, yet this information cannot be used to find the secret key.
Disk encryption is a special case of data at rest protection when the storage medium is a sector-addressable device. This article presents cryptographic aspects of the problem. For an overview, see disk encryption. For discussion of different software packages and hardware devices devoted to this problem, see disk encryption software and disk encryption hardware.
In mathematics and computing, universal hashing refers to selecting a hash function at random from a family of hash functions with a certain mathematical property. This guarantees a low number of collisions in expectation, even if the data is chosen by an adversary. Many universal families are known, and their evaluation is often very efficient. Universal hashing has numerous uses in computer science, for example in implementations of hash tables, randomized algorithms, and cryptography.
A rolling hash is a hash function where the input is hashed in a window that moves through the input.

In cryptography, the Merkle–Damgård construction or Merkle–Damgård hash function is a method of building collision-resistant cryptographic hash functions from collision-resistant one-way compression functions. This construction was used in the design of many popular hash algorithms such as MD5, SHA-1 and SHA-2.
In cryptography, Galois/Counter Mode (GCM) is a mode of operation for symmetric-key cryptographic block ciphers which is widely adopted for its performance. GCM throughput rates for state-of-the-art, high-speed communication channels can be achieved with inexpensive hardware resources.

In computer science, a fingerprinting algorithm is a procedure that maps an arbitrarily large data item to a much shorter bit string, its fingerprint, that uniquely identifies the original data for all practical purposes just as human fingerprints uniquely identify people for practical purposes. This fingerprint may be used for data deduplication purposes. This is also referred to as file fingerprinting, data fingerprinting, or structured data fingerprinting.
In cryptography, SWIFFT is a collection of provably secure hash functions. It is based on the concept of the fast Fourier transform (FFT). SWIFFT is not the first hash function based on FFT, but it sets itself apart by providing a mathematical proof of its security. It also uses the LLL basis reduction algorithm. It can be shown that finding collisions in SWIFFT is at least as difficult as finding short vectors in cyclic/ideal lattices in the worst case. By giving a security reduction to the worst-case scenario of a difficult mathematical problem, SWIFFT gives a much stronger security guarantee than most other cryptographic hash functions.
Post-quantum cryptography (PQC), sometimes referred to as quantum-proof, quantum-safe, or quantum-resistant, is the development of cryptographic algorithms that are thought to be secure against a cryptanalytic attack by a quantum computer. The problem with popular algorithms currently used in the market is that their security relies on one of three hard mathematical problems: the integer factorization problem, the discrete logarithm problem or the elliptic-curve discrete logarithm problem. All of these problems could be easily solved on a sufficiently powerful quantum computer running Shor's algorithm or even faster and less demanding alternatives.




