In molecular biology, restriction fragment length polymorphism (RFLP) is a technique that exploits variations in homologous DNA sequences, known as polymorphisms, populations, or species or to pinpoint the locations of genes within a sequence. The term may refer to a polymorphism itself, as detected through the differing locations of restriction enzyme sites, or to a related laboratory technique by which such differences can be illustrated. In RFLP analysis, a DNA sample is digested into fragments by one or more restriction enzymes, and the resulting restriction fragments are then separated by gel electrophoresis according to their size.

In genetics and bioinformatics, a single-nucleotide polymorphism is a germline substitution of a single nucleotide at a specific position in the genome that is present in a sufficiently large fraction of considered population.
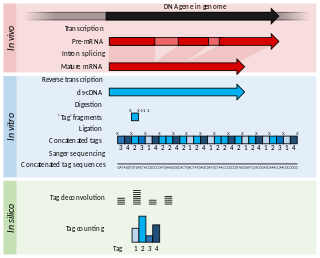
Serial Analysis of Gene Expression (SAGE) is a transcriptomic technique used by molecular biologists to produce a snapshot of the messenger RNA population in a sample of interest in the form of small tags that correspond to fragments of those transcripts. Several variants have been developed since, most notably a more robust version, LongSAGE, RL-SAGE and the most recent SuperSAGE. Many of these have improved the technique with the capture of longer tags, enabling more confident identification of a source gene.
A genetic marker is a gene or DNA sequence with a known location on a chromosome that can be used to identify individuals or species. It can be described as a variation that can be observed. A genetic marker may be a short DNA sequence, such as a sequence surrounding a single base-pair change, or a long one, like minisatellites.
Gene mapping or genome mapping describes the methods used to identify the location of a gene on a chromosome and the distances between genes. Gene mapping can also describe the distances between different sites within a gene.

In population genetics, an ancestry-informative marker (AIM) is a single-nucleotide polymorphism that exhibits substantially different frequencies between different populations. A set of many AIMs can be used to estimate the proportion of ancestry of an individual derived from each population.
Genotyping is the process of determining differences in the genetic make-up (genotype) of an individual by examining the individual's DNA sequence using biological assays and comparing it to another individual's sequence or a reference sequence. It reveals the alleles an individual has inherited from their parents. Traditionally genotyping is the use of DNA sequences to define biological populations by use of molecular tools. It does not usually involve defining the genes of an individual.
In molecular biology, SNP array is a type of DNA microarray which is used to detect polymorphisms within a population. A single nucleotide polymorphism (SNP), a variation at a single site in DNA, is the most frequent type of variation in the genome. Around 335 million SNPs have been identified in the human genome, 15 million of which are present at frequencies of 1% or higher across different populations worldwide.
SNP genotyping is the measurement of genetic variations of single nucleotide polymorphisms (SNPs) between members of a species. It is a form of genotyping, which is the measurement of more general genetic variation. SNPs are one of the most common types of genetic variation. An SNP is a single base pair mutation at a specific locus, usually consisting of two alleles. SNPs are found to be involved in the etiology of many human diseases and are becoming of particular interest in pharmacogenetics. Because SNPs are conserved during evolution, they have been proposed as markers for use in quantitative trait loci (QTL) analysis and in association studies in place of microsatellites. The use of SNPs is being extended in the HapMap project, which aims to provide the minimal set of SNPs needed to genotype the human genome. SNPs can also provide a genetic fingerprint for use in identity testing. The increase of interest in SNPs has been reflected by the furious development of a diverse range of SNP genotyping methods.

Bisulfitesequencing (also known as bisulphite sequencing) is the use of bisulfite treatment of DNA before routine sequencing to determine the pattern of methylation. DNA methylation was the first discovered epigenetic mark, and remains the most studied. In animals it predominantly involves the addition of a methyl group to the carbon-5 position of cytosine residues of the dinucleotide CpG, and is implicated in repression of transcriptional activity.
The following outline is provided as an overview of and topical guide to genetics:
Population genomics is the large-scale comparison of DNA sequences of populations. Population genomics is a neologism that is associated with population genetics. Population genomics studies genome-wide effects to improve our understanding of microevolution so that we may learn the phylogenetic history and demography of a population.
Epigenomics is the study of the complete set of epigenetic modifications on the genetic material of a cell, known as the epigenome. The field is analogous to genomics and proteomics, which are the study of the genome and proteome of a cell. Epigenetic modifications are reversible modifications on a cell's DNA or histones that affect gene expression without altering the DNA sequence. Epigenomic maintenance is a continuous process and plays an important role in stability of eukaryotic genomes by taking part in crucial biological mechanisms like DNA repair. Plant flavones are said to be inhibiting epigenomic marks that cause cancers. Two of the most characterized epigenetic modifications are DNA methylation and histone modification. Epigenetic modifications play an important role in gene expression and regulation, and are involved in numerous cellular processes such as in differentiation/development and tumorigenesis. The study of epigenetics on a global level has been made possible only recently through the adaptation of genomic high-throughput assays.
Methylated DNA immunoprecipitation is a large-scale purification technique in molecular biology that is used to enrich for methylated DNA sequences. It consists of isolating methylated DNA fragments via an antibody raised against 5-methylcytosine (5mC). This technique was first described by Weber M. et al. in 2005 and has helped pave the way for viable methylome-level assessment efforts, as the purified fraction of methylated DNA can be input to high-throughput DNA detection methods such as high-resolution DNA microarrays (MeDIP-chip) or next-generation sequencing (MeDIP-seq). Nonetheless, understanding of the methylome remains rudimentary; its study is complicated by the fact that, like other epigenetic properties, patterns vary from cell-type to cell-type.
Diversity Arrays Technology (DArT) is a high-throughput genetic marker technique that can detect allelic variations to provides comprehensive genome coverage without any DNA sequence information for genotyping and other genetic analysis. The general steps involve reducing the complexity of the genomic DNA with specific restriction enzymes, choosing diverse fragments to serve as representations for the parent genomes, amplify via polymerase chain reaction (PCR), insert fragments into a vector to be placed as probes within a microarray, then fluorescent targets from a reference sequence will be allowed to hybridize with probes and put through an imaging system. The objective is to identify and quantify various forms of DNA polymorphism within genomic DNA of sampled species.
Molecular Inversion Probe (MIP) belongs to the class of Capture by Circularization molecular techniques for performing genomic partitioning, a process through which one captures and enriches specific regions of the genome. Probes used in this technique are single stranded DNA molecules and, similar to other genomic partitioning techniques, contain sequences that are complementary to the target in the genome; these probes hybridize to and capture the genomic target. MIP stands unique from other genomic partitioning strategies in that MIP probes share the common design of two genomic target complementary segments separated by a linker region. With this design, when the probe hybridizes to the target, it undergoes an inversion in configuration and circularizes. Specifically, the two target complementary regions at the 5’ and 3’ ends of the probe become adjacent to one another while the internal linker region forms a free hanging loop. The technology has been used extensively in the HapMap project for large-scale SNP genotyping as well as for studying gene copy alterations and characteristics of specific genomic loci to identify biomarkers for different diseases such as cancer. Key strengths of the MIP technology include its high specificity to the target and its scalability for high-throughput, multiplexed analyses where tens of thousands of genomic loci are assayed simultaneously.

Exome sequencing, also known as whole exome sequencing (WES), is a genomic technique for sequencing all of the protein-coding regions of genes in a genome. It consists of two steps: the first step is to select only the subset of DNA that encodes proteins. These regions are known as exons—humans have about 180,000 exons, constituting about 1% of the human genome, or approximately 30 million base pairs. The second step is to sequence the exonic DNA using any high-throughput DNA sequencing technology.
Disease gene identification is a process by which scientists identify the mutant genotypes responsible for an inherited genetic disorder. Mutations in these genes can include single nucleotide substitutions, single nucleotide additions/deletions, deletion of the entire gene, and other genetic abnormalities.
In the field of genetic sequencing, genotyping by sequencing, also called GBS, is a method to discover single nucleotide polymorphisms (SNP) in order to perform genotyping studies, such as genome-wide association studies (GWAS). GBS uses restriction enzymes to reduce genome complexity and genotype multiple DNA samples. After digestion, PCR is performed to increase fragments pool and then GBS libraries are sequenced using next generation sequencing technologies, usually resulting in about 100bp single-end reads. It is relatively inexpensive and has been used in plant breeding. Although GBS presents an approach similar to restriction-site-associated DNA sequencing (RAD-seq) method, they differ in some substantial ways.
Transcriptomics technologies are the techniques used to study an organism's transcriptome, the sum of all of its RNA transcripts. The information content of an organism is recorded in the DNA of its genome and expressed through transcription. Here, mRNA serves as a transient intermediary molecule in the information network, whilst non-coding RNAs perform additional diverse functions. A transcriptome captures a snapshot in time of the total transcripts present in a cell. Transcriptomics technologies provide a broad account of which cellular processes are active and which are dormant. A major challenge in molecular biology is to understand how a single genome gives rise to a variety of cells. Another is how gene expression is regulated.
