Meta elements are tags used in HTML and XHTML documents to provide structured metadata about a Web page. They are part of a web page's head section. Multiple Meta elements with different attributes can be used on the same page. Meta elements can be used to specify page description, keywords and any other metadata not provided through the other head elements and attributes.
In computing, a search engine is an information retrieval software system designed to help find information stored on one or more computer systems. Search engines discover, crawl, transform, and store information for retrieval and presentation in response to user queries. The search results are usually presented in a list and are commonly called hits. The most widely used type of search engine is a web search engine, which searches for information on the World Wide Web.

A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing.
Spamdexing is the deliberate manipulation of search engine indexes. It involves a number of methods, such as link building and repeating unrelated phrases, to manipulate the relevance or prominence of resources indexed in a manner inconsistent with the purpose of the indexing system.

robots.txt is the filename used for implementing the Robots Exclusion Protocol, a standard used by websites to indicate to visiting web crawlers and other web robots which portions of the website they are allowed to visit.
Search engine optimization (SEO) is the process of improving the quality and quantity of website traffic to a website or a web page from search engines. SEO targets unpaid traffic rather than direct traffic or paid traffic. Unpaid traffic may originate from different kinds of searches, including image search, video search, academic search, news search, and industry-specific vertical search engines.

Googlebot is the web crawler software used by Google that collects documents from the web to build a searchable index for the Google Search engine. This name is actually used to refer to two different types of web crawlers: a desktop crawler and a mobile crawler.
The deep web, invisible web, or hidden web are parts of the World Wide Web whose contents are not indexed by standard web search-engine programs. This is in contrast to the "surface web", which is accessible to anyone using the Internet. Computer scientist Michael K. Bergman is credited with inventing the term in 2001 as a search-indexing term.
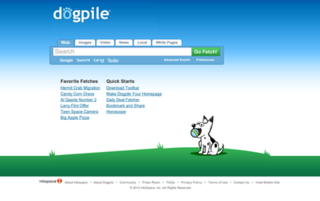
Dogpile is a metasearch engine for information on the World Wide Web that fetches results from Google, Yahoo!, Yandex, Bing, and other popular search engines, including those from audio and video content providers such as Yahoo!.

A metasearch engine is an online information retrieval tool that uses the data of a web search engine to produce its own results. Metasearch engines take input from a user and immediately query search engines for results. Sufficient data is gathered, ranked, and presented to the users.
The noindex value of an HTML robots meta tag requests that automated Internet bots avoid indexing a web page. Reasons why one might want to use this meta tag include advising robots not to index a very large database, web pages that are very transitory, web pages that are under development, web pages that one wishes to keep slightly more private, or the printer and mobile-friendly versions of pages. Since the burden of honoring a website's noindex tag lies with the author of the search robot, sometimes these tags are ignored. Also the interpretation of the noindex tag is sometimes slightly different from one search engine company to the next.
Yahoo! Search is a search engine owned and operated by Yahoo!, using Microsoft Bing to power results.
Sitemaps is a protocol in XML format meant for a webmaster to inform search engines about URLs on a website that are available for web crawling. It allows webmasters to include additional information about each URL: when it was last updated, how often it changes, and how important it is in relation to other URLs of the site. This allows search engines to crawl the site more efficiently and to find URLs that may be isolated from the rest of the site's content. The Sitemaps protocol is a URL inclusion protocol and complements robots.txt, a URL exclusion protocol.
nofollow is a setting on a web page hyperlink that directs search engines not to use the link for page ranking calculations. It is specified in the page as a type of link relation; that is: <a rel="nofollow" ...>. Because search engines often calculate a site's importance according to the number of hyperlinks from other sites, the nofollow setting allows website authors to indicate that the presence of a link is not an endorsement of the target site's importance.
A search engine is a software system that provides hyperlinks to web pages and other relevant information on the Web in response to a user's query. The user inputs a query within a web browser or a mobile app, and the search results are often a list of hyperlinks, accompanied by textual summaries and images. Users also have the option of limiting the search to a specific type of results, such as images, videos, or news.
A search engine results page (SERP) is a webpage that is displayed by a search engine in response to a query by a user. The main component of a SERP is the listing of results that are returned by the search engine in response to a keyword query.

Bing Webmaster Tools is a free service as part of Microsoft's Bing search engine which allows webmasters to add their websites to the Bing index crawler, see their site's performance in Bing and a lot more. The service also offers tools for webmasters to troubleshoot the crawling and indexing of their website, submission of new URLs, Sitemap creation, submission and ping tools, website statistics, consolidation of content submission, and new content and community resources.
Field v. Google, Inc., 412 F.Supp. 2d 1106 is a case where Google Inc. successfully defended a lawsuit for copyright infringement. Field argued that Google infringed his exclusive right to reproduce his copyrighted works when it "cached" his website and made a copy of it available on its search engine. Google raised multiple defenses: fair use, implied license, estoppel, and Digital Millennium Copyright Act safe harbor protection. The court granted Google's motion for summary judgment and denied Field's motion for summary judgment.

The Wayback Machine is a digital archive of the World Wide Web founded by the Internet Archive, an American nonprofit organization based in San Francisco, California. Created in 1996 and launched to the public in 2001, it allows the user to go "back in time" to see how websites looked in the past. Its founders, Brewster Kahle and Bruce Gilliat, developed the Wayback Machine to provide "universal access to all knowledge" by preserving archived copies of defunct web pages.
MetaCrawler is a search engine. It is a registered trademark of InfoSpace and was created by Erik Selberg.
