
Free software, libre software, or libreware is computer software distributed under terms that allow users to run the software for any purpose as well as to study, change, and distribute it and any adapted versions. Free software is a matter of liberty, not price; all users are legally free to do what they want with their copies of a free software regardless of how much is paid to obtain the program. Computer programs are deemed "free" if they give end-users ultimate control over the software and, subsequently, over their devices.
A fourth-generation programming language (4GL) is a high-level computer programming language that belongs to a class of languages envisioned as an advancement upon third-generation programming languages (3GL). Each of the programming language generations aims to provide a higher level of abstraction of the internal computer hardware details, making the language more programmer-friendly, powerful, and versatile. While the definition of 4GL has changed over time, it can be typified by operating more with large collections of information at once rather than focusing on just bits and bytes. Languages claimed to be 4GL may include support for database management, report generation, mathematical optimization, GUI development, or web development. Some researchers state that 4GLs are a subset of domain-specific languages.
An integrated development environment (IDE) is a software application that provides comprehensive facilities for software development. An IDE normally consists of at least a source-code editor, build automation tools, and a debugger. Some IDEs, such as IntelliJ IDEA, Eclipse and Lazarus contain the necessary compiler, interpreter or both; others, such as SharpDevelop and NetBeans, do not.
In software engineering and development, a software metric is a standard of measure of a degree to which a software system or process possesses some property. Even if a metric is not a measurement, often the two terms are used as synonyms. Since quantitative measurements are essential in all sciences, there is a continuous effort by computer science practitioners and theoreticians to bring similar approaches to software development. The goal is obtaining objective, reproducible and quantifiable measurements, which may have numerous valuable applications in schedule and budget planning, cost estimation, quality assurance, testing, software debugging, software performance optimization, and optimal personnel task assignments.

Delphi is a general-purpose programming language and a software product that uses the Delphi dialect of the Object Pascal programming language and provides an integrated development environment (IDE) for rapid application development of desktop, mobile, web, and console software, currently developed and maintained by Embarcadero Technologies.
In the context of software engineering, software quality refers to two related but distinct notions:
In computer programming, Intentional Programming is a programming paradigm developed by Charles Simonyi that encodes in software source code the precise intention which programmers have in mind when conceiving their work. By using the appropriate level of abstraction at which the programmer is thinking, creating and maintaining computer programs become easier. By separating the concerns for intentions and how they are being operated upon, the software becomes more modular and allows for more reusable software code.

LAMP is an acronym denoting one of the most common software stacks for the web's most popular applications. Its generic software stack model has largely interchangeable components.
SEER for Software (SEER-SEM) is a project management application used to estimate resources required for software development.
The function point is a "unit of measurement" to express the amount of business functionality an information system provides to a user. Function points are used to compute a functional size measurement (FSM) of software. The cost of a single unit is calculated from past projects.
Coding best practices or programming best practices are a set of informal, sometimes personal, rules that many software developers, in computer programming follow to improve software quality. Many computer programs require being robust and reliable for long periods of time, so any rules need to facilitate both initial development and subsequent maintenance of source code by people other than the original authors.
Coding conventions are a set of guidelines for a specific programming language that recommend programming style, practices, and methods for each aspect of a program written in that language. These conventions usually cover file organization, indentation, comments, declarations, statements, white space, naming conventions, programming practices, programming principles, programming rules of thumb, architectural best practices, etc. These are guidelines for software structural quality. Software programmers are highly recommended to follow these guidelines to help improve the readability of their source code and make software maintenance easier. Coding conventions are only applicable to the human maintainers and peer reviewers of a software project. Conventions may be formalized in a documented set of rules that an entire team or company follows, or may be as informal as the habitual coding practices of an individual. Coding conventions are not enforced by compilers.
Software sizing or software size estimation is an activity in software engineering that is used to determine or estimate the size of a software application or component in order to be able to implement other software project management activities. Size is an inherent characteristic of a piece of software just like weight is an inherent characteristic of a tangible material.
Programming productivity describes the degree of the ability of individual programmers or development teams to build and evolve software systems. Productivity traditionally refers to the ratio between the quantity of software produced and the cost spent for it. Here the delicacy lies in finding a reasonable way to define software quantity.
Software measurement is a quantified attribute of a characteristic of a software product or the software process. It is a discipline within software engineering. The process of software measurement is defined and governed by ISO Standard ISO 15939.
Quilt is a software utility for managing a series of changes to the source code of any computer program. Such changes are often referred to as "patches" or "patch sets". Quilt can take an arbitrary number of patches as input and condense them into a single patch. In doing so, Quilt makes it easier for many programmers to test and evaluate the different changes amongst patches before they are permanently applied to the source code.
Weighted Micro Function Points (WMFP) is a modern software sizing algorithm which is a successor to solid ancestor scientific methods as COCOMO, COSYSMO, maintainability index, cyclomatic complexity, function points, and Halstead complexity. It produces more accurate results than traditional software sizing methodologies, while requiring less configuration and knowledge from the end user, as most of the estimation is based on automatic measurements of an existing source code.
The following outline is provided as an overview of and topical guide to the Perl programming language:
perf is a performance analyzing tool in Linux, available from Linux kernel version 2.6.31 in 2009. Userspace controlling utility, named perf, is accessed from the command line and provides a number of subcommands; it is capable of statistical profiling of the entire system.
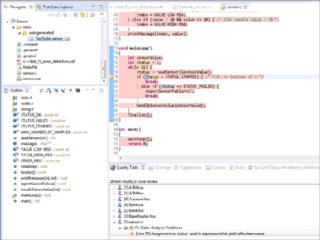
Parasoft C/C++test is an integrated set of tools for testing C and C++ source code that software developers use to analyze, test, find defects, and measure the quality and security of their applications. It supports software development practices that are part of development testing, including static code analysis, dynamic code analysis, unit test case generation and execution, code coverage analysis, regression testing, runtime error detection, requirements traceability, and code review. It's a commercial tool that supports operation on Linux, Windows, and Solaris platforms as well as support for on-target embedded testing and cross compilers.