Related Research Articles
Unicode, formally The Unicode Standard, is a text encoding standard maintained by the Unicode Consortium designed to support the use of text written in all of the world's major writing systems. Version 15.1 of the standard defines 149813 characters and 161 scripts used in various ordinary, literary, academic, and technical contexts.
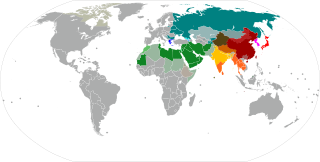
The Brahmic scripts, also known as Indic scripts, are a family of abugida writing systems. They are used throughout the Indian subcontinent, Southeast Asia and parts of East Asia. They are descended from the Brahmi script of ancient India and are used by various languages in several language families in South, East and Southeast Asia: Indo-Aryan, Dravidian, Tibeto-Burman, Mongolic, Austroasiatic, Austronesian, and Tai. They were also the source of the dictionary order (gojūon) of Japanese kana.
The byte-order mark (BOM) is a particular usage of the special Unicode character code, U+FEFFZERO WIDTH NO-BREAK SPACE, whose appearance as a magic number at the start of a text stream can signal several things to a program reading the text:
Malayalam script is a Brahmic script used commonly to write Malayalam, which is the principal language of Kerala, India, spoken by 45 million people in the world. It is a Dravidian language spoken in the Indian state of Kerala and the union territories of Lakshadweep and Puducherry by the Malayali people. It is one of the official scripts of the Indian Republic. Malayalam script is also widely used for writing Sanskrit texts in Kerala.
UTF-32 (32-bit Unicode Transformation Format) is a fixed-length encoding used to encode Unicode code points that uses exactly 32 bits (four bytes) per code point (but a number of leading bits must be zero as there are far fewer than 232 Unicode code points, needing actually only 21 bits). UTF-32 is a fixed-length encoding, in contrast to all other Unicode transformation formats, which are variable-length encodings. Each 32-bit value in UTF-32 represents one Unicode code point and is exactly equal to that code point's numerical value.

The Tibetan script is a segmental writing system (abugida) of Indic origin used to write certain Tibetic languages, including Tibetan, Dzongkha, Sikkimese, Ladakhi, Jirel and Balti. It has also been used for some non-Tibetic languages in close cultural contact with Tibet, such as Thakali and Old Turkic. The printed form is called uchen script while the hand-written cursive form used in everyday writing is called umê script. This writing system is used across the Himalayas and Tibet.

The zero-width non-joiner () is a non-printing character used in the computerization of writing systems that make use of ligatures. When placed between two characters that would otherwise be connected into a ligature, a ZWNJ causes them to be printed in their final and initial forms, respectively. This is also an effect of a space character, but a ZWNJ is used when it is desirable to keep the characters closer together or to connect a word with its morpheme.
Telugu script, an abugida from the Brahmic family of scripts, is used to write the Telugu language, a Dravidian language spoken in the Indian states of Andhra Pradesh and Telangana as well as several other neighbouring states. It is one of the official scripts of the Indian Republic. The Telugu script is also widely used for writing Sanskrit texts and to some extent the Gondi language. It gained prominence during the Eastern Chalukyas also known as Vengi Chalukya era. It shares extensive similarities with the Kannada script, as both of them evolved from the Bhattiprolu and Kadamba scripts of the Brahmi family. In 2008, the Telugu language was given the status of a Classical Language of India, in recognition of its rich history and heritage.
Indian Standard Code for Information Interchange (ISCII) is a coding scheme for representing various writing systems of India. It encodes the main Indic scripts and a Roman transliteration. The supported scripts are: Bengali–Assamese, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. ISCII does not encode the writing systems of India that are based on Persian, but its writing system switching codes nonetheless provide for Kashmiri, Sindhi, Urdu, Persian, Pashto and Arabic. The Persian-based writing systems were subsequently encoded in the PASCII encoding.
Uniscribe is the Microsoft Windows set of services for rendering Unicode-encoded text, supporting complex text layout. It is implemented in the dynamic link library USP10.DLL. Uniscribe was released with Windows 2000 and Internet Explorer 5.0. In addition, the Windows CE platform has supported Uniscribe since version 5.0.
Virama is a Sanskrit phonological concept to suppress the inherent vowel that otherwise occurs with every consonant letter, commonly used as a generic term for a codepoint in Unicode, representing either
- halanta, hasanta or explicit virāma, a diacritic in many Brahmic scripts, including the Devanagari and Bengali scripts, or
- saṃyuktākṣara or implicit virama, a conjunct consonant or ligature.

The zero-width joiner (‍) is a non-printing character used in the computerized typesetting of writing systems in which the shape or positioning of a grapheme depends on its relation to other graphemes, such as the Arabic script or any Indic script. Sometimes the Roman script is to be counted as complex, e.g. when using a Fraktur typeface. When placed between two characters that would otherwise not be connected, a ZWJ causes them to be printed in their connected forms.

The Lepcha script, or Róng script, is an abugida used by the Lepcha people to write the Lepcha language. Unusually for an abugida, syllable-final consonants are written as diacritics.
The Unicode Consortium and the ISO/IEC JTC 1/SC 2/WG 2 jointly collaborate on the list of the characters in the Universal Coded Character Set. The Universal Coded Character Set, most commonly called the Universal Character Set, is an international standard to map characters, discrete symbols used in natural language, mathematics, music, and other domains, to unique machine-readable data values. By creating this mapping, the UCS enables computer software vendors to interoperate, and transmit—interchange—UCS-encoded text strings from one to another. Because it is a universal map, it can be used to represent multiple languages at the same time. This avoids the confusion of using multiple legacy character encodings, which can result in the same sequence of codes having multiple interpretations depending on the character encoding in use, resulting in mojibake if the wrong one is chosen.
The Chakma Script, also called Ajhā pāṭh, Ojhapath, Ojhopath, Aaojhapath, is an abugida used for the Chakma language, and recently for the Pali language.
The zero-width space (), abbreviated ZWSP, is a non-printing character used in computerized typesetting to indicate word boundaries to text-processing systems for scripts that do not use explicit spacing, or after characters not followed by a visible space after which there may be a line break.

Meteg is a punctuation mark used in Biblical Hebrew for stress marking. It is a vertical bar placed under the affected syllable.
Myanmar is a Unicode block containing characters for the Burmese, Mon, Shan, Palaung, and the Karen languages of Myanmar, as well as the Aiton and Phake languages of Northeast India. It is also used to write Pali and Sanskrit in Myanmar.
Mongolian is a Unicode block containing characters for dialects of Mongolian, Manchu, and Sibe languages. It is traditionally written in vertical lines Top-Down, right across the page, although the Unicode code charts cite the characters rotated to horizontal orientation as this is the orientation of glyphs in a font that supports layout in vertical orientation.
Tamil All Character Encoding (TACE16) is a scheme for encoding the Tamil script in the Private Use Area of Unicode, implementing a syllabary-based character model differing from the modified-ISCII model used by Unicode's existing Tamil implementation.
References
- ↑ "Unicode character database". The Unicode Standard. Retrieved 2023-07-26.
- ↑ "Enumerated Versions of The Unicode Standard". The Unicode Standard. Retrieved 2023-07-26.
- 1 2 3 "Unicode 1.0.1 Addendum" (PDF). The Unicode Standard. 1992-11-03. Retrieved 2016-07-09.
- ↑ Kaplan, Michael (2007-08-28). "Every character has a story #29: U+1000^H^H^H^H0f40, (TIBETAN or MYANMAR LETTER KA, depending on when you ask)". Sorting it all out.
- A Chinese concern posted to the Unicode Consortium citing the conjunct character "སྐྤྵྴྍྐ" (EWTS s+k+p+Sh+sh+x+ka; IAST skpṣśxka), showing the complexity of encoding. (Devanagari encoding never allowed "ᳵ" to be conjuncted, i.e. "स्क्प्ष्श्ᳵ्क"does not exist.)