Artificial intelligence (AI) is the intelligence of machines or software, as opposed to the intelligence of humans or other animals. It is a field of study in computer science that develops and studies intelligent machines. Such machines may be called AIs.

A chatbot is a software application or web interface that is designed to mimic human conversation through text or voice interactions. Modern chatbots are typically online and use generative artificial intelligence systems that are capable of maintaining a conversation with a user in natural language and simulating the way a human would behave as a conversational partner. Such chatbots often use deep learning and natural language processing, but simpler chatbots have existed for decades.
Machine learning (ML) is a field of study in artificial intelligence concerned with the development and study of statistical algorithms that can learn from data and generalize to unseen data, and thus perform tasks without explicit instructions. Recently, generative artificial neural networks have been able to surpass many previous approaches in performance.
Natural language generation (NLG) is a software process that produces natural language output. A widely-cited survey of NLG methods describes NLG as "the subfield of artificial intelligence and computational linguistics that is concerned with the construction of computer systems than can produce understandable texts in English or other human languages from some underlying non-linguistic representation of information".
Human-based computation (HBC), human-assisted computation, ubiquitous human computing or distributed thinking is a computer science technique in which a machine performs its function by outsourcing certain steps to humans, usually as microwork. This approach uses differences in abilities and alternative costs between humans and computer agents to achieve symbiotic human–computer interaction. For computationally difficult tasks such as image recognition, human-based computation plays a central role in training Deep Learning-based Artificial Intelligence systems. In this case, human-based computation has been referred to as human-aided artificial intelligence.
Artificial intelligence (AI) has been used in applications throughout industry and academia. AI, like electricity or computers, is a general-purpose technology that has a multitude of applications. It has been used in fields of language translation, image recognition, credit scoring, e-commerce and other domains.

Figure Eight was a human-in-the-loop machine learning and artificial intelligence company based in San Francisco.
Learning to rank or machine-learned ranking (MLR) is the application of machine learning, typically supervised, semi-supervised or reinforcement learning, in the construction of ranking models for information retrieval systems. Training data may, for example, consist of lists of items with some partial order specified between items in each list. This order is typically induced by giving a numerical or ordinal score or a binary judgment for each item. The goal of constructing the ranking model is to rank new, unseen lists in a similar way to rankings in the training data.
Explainable AI (XAI), often overlapping with Interpretable AI, or Explainable Machine Learning (XML), either refers to an AI system over which it is possible for humans to retain intellectual oversight, or to the methods to achieve this. The main focus is usually on the reasoning behind the decisions or predictions made by the AI which are made more understandable and transparent. XAI counters the "black box" tendency of machine learning, where even the AI's designers cannot explain why it arrived at a specific decision.
Automated machine learning (AutoML) is the process of automating the tasks of applying machine learning to real-world problems.
Crowdsource is a crowdsourcing platform developed by Google intended to improve a host of Google services through the user-facing training of different algorithms.
Deep reinforcement learning is a subfield of machine learning that combines reinforcement learning (RL) and deep learning. RL considers the problem of a computational agent learning to make decisions by trial and error. Deep RL incorporates deep learning into the solution, allowing agents to make decisions from unstructured input data without manual engineering of the state space. Deep RL algorithms are able to take in very large inputs and decide what actions to perform to optimize an objective. Deep reinforcement learning has been used for a diverse set of applications including but not limited to robotics, video games, natural language processing, computer vision, education, transportation, finance and healthcare.

Federated learning is a machine learning technique that trains an algorithm via multiple independent sessions, each using its own dataset. This approach stands in contrast to traditional centralized machine learning techniques where local datasets are merged into one training session, as well as to approaches that assume that local data samples are identically distributed.
Government by algorithm is an alternative form of government or social ordering where the usage of computer algorithms is applied to regulations, law enforcement, and generally any aspect of everyday life such as transportation or land registration. The term "government by algorithm" has appeared in academic literature as an alternative for "algorithmic governance" in 2013. A related term, algorithmic regulation, is defined as setting the standard, monitoring and modifying behaviour by means of computational algorithms – automation of judiciary is in its scope. In the context of blockchain, it is also known as blockchain governance.
Abeba Birhane is an Ethiopian-born cognitive scientist who works at the intersection of complex adaptive systems, machine learning, algorithmic bias, and critical race studies. Birhane's work with Vinay Prabhu uncovered that large-scale image datasets commonly used to develop AI systems, including ImageNet and 80 Million Tiny Images, carried racist and misogynistic labels and offensive images. She has been recognized by VentureBeat as a top innovator in computer vision and named as one of the 100 most influential persons in AI 2023 by TIME magazine.
The Fashion MNIST dataset is a large freely available database of fashion images that is commonly used for training and testing various machine learning systems. Fashion-MNIST was intended to serve as a replacement for the original MNIST database for benchmarking machine learning algorithms, as it shares the same image size, data format and the structure of training and testing splits.
Hugging Face, Inc. is a French-American company that develops tools for building applications using machine learning, based in New York City. It is most notable for its transformers library built for natural language processing applications and its platform that allows users to share machine learning models and datasets and showcase their work.
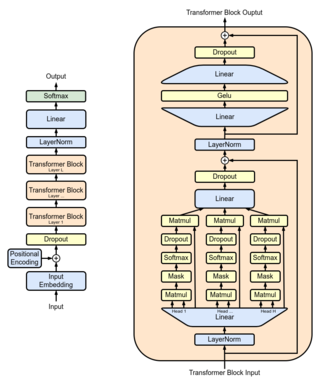
Generative pre-trained transformers (GPT) are a type of large language model (LLM) and a prominent framework for generative artificial intelligence. They are artificial neural networks that are used in natural language processing tasks. GPTs are based on the transformer architecture, pre-trained on large data sets of unlabelled text, and able to generate novel human-like content. As of 2023, most LLMs have these characteristics and are sometimes referred to broadly as GPTs.

Edward Y. Chang is a computer scientist, academic, and author. He is an adjunct professor of Computer Science at Stanford University, and Visiting Chair Professor of Bioinformatics and Medical Engineering at Asia University, since 2019.