Related Research Articles
A bidirectional text contains two text directionalities, right-to-left (RTL) and left-to-right (LTR). It generally involves text containing different types of alphabets, but may also refer to boustrophedon, which is changing text direction in each row.

In computing, data storage, and data transmission, character encoding is used to represent a repertoire of characters by some kind of encoding system that assigns a number to each character for digital representation. Depending on the abstraction level and context, corresponding code points and the resulting code space may be regarded as bit patterns, octets, natural numbers, electrical pulses, or anything of the like. A character encoding is used in computation, data storage, and transmission of textual data. "Character set", "character map", "codeset" and "code page" are related, but not identical, terms.
Unicode, formally the Unicode Standard, is an information technology standard for the consistent encoding, representation, and handling of text expressed in most of the world's writing systems. The standard, which is maintained by the Unicode Consortium, defines 144,697 characters covering 159 modern and historic scripts, as well as symbols, emoji, and non-visual control and formatting codes.
UTF-8 is a variable-width character encoding used for electronic communication. Defined by the Unicode Standard, the name is derived from UnicodeTransformation Format – 8-bit.

Newline is a control character or sequence of control characters in a character encoding specification that is used to signify the end of a line of text and the start of a new one, e.g., Line Feed (LF) in Unix. Some text editors set this special character when pressing the ↵ Enter key.
In computing, Chinese character encodings can be used to represent text written in the CJK languages—Chinese, Japanese, Korean—and (rarely) obsolete Vietnamese, all of which use Chinese characters. Several general-purpose character encodings accommodate Chinese characters, and some of them were developed specifically for Chinese.

GB 18030 is a Chinese government standard, described as Information Technology — Chinese coded character set and defines the required language and character support necessary for software in China. GB18030 is the registered Internet name for the official character set of the People's Republic of China (PRC) superseding GB2312. As a Unicode Transformation Format, GB18030 supports both simplified and traditional Chinese characters. It is also compatible with legacy encodings including GB2312, CP936, and GBK 1.0.
The Standard Compression Scheme for Unicode (SCSU) is a Unicode Technical Standard for reducing the number of bytes needed to represent Unicode text, especially if that text uses mostly characters from one or a small number of per-language character blocks. It does so by dynamically mapping values in the range 128–255 to offsets within particular blocks of 128 characters. The initial conditions of the encoder mean that existing strings in ASCII and ISO-8859-1 that do not contain C0 control codes other than NULL TAB CR and LF can be treated as SCSU strings. Since most alphabets do reside in blocks of contiguous Unicode codepoints, texts that use small alphabets and either ASCII punctuation or punctuation that fits within the window for the main alphabet can be encoded at one byte per character, most other punctuation can be encoded at 2 bytes per symbol through non-locking shifts. SCSU can also switch to UTF-16 internally to handle non-alphabetic languages.
The at sign, @, is normally read aloud as "at"; it is also commonly called the at symbol, commercial at or address sign. It is used as an accounting and invoice abbreviation meaning "at a rate of", but it is now seen more widely in email addresses and social media platform handles.
Tamil Script Code for Information Interchange (TSCII) is a coding scheme for representing the Tamil script. The lower 128 codepoints are plain ASCII, the upper 128 codepoints are TSCII-specific. After long years of being used on the Internet by private agreement only, it was successfully registered with the IANA in 2007.
In Unix and Unix-like operating systems, iconv is a command-line program and a standardized application programming interface (API) used to convert between different character encodings. "It can convert from any of these encodings to any other, through Unicode conversion."
International Components for Unicode (ICU) is an open-source project of mature C/C++ and Java libraries for Unicode support, software internationalization, and software globalization. ICU is widely portable to many operating systems and environments. It gives applications the same results on all platforms and between C, C++, and Java software. The ICU project is a technical committee of the Unicode Consortium and sponsored, supported, and used by IBM and many other companies.
Binary Ordered Compression for Unicode (BOCU) is a MIME compatible Unicode compression scheme. BOCU-1 combines the wide applicability of UTF-8 with the compactness of Standard Compression Scheme for Unicode (SCSU). This Unicode encoding is designed to be useful for compressing short strings, and maintains code point order. BOCU-1 is specified in a Unicode Technical Note.
In computer programming, whitespace is any character or series of characters that represent horizontal or vertical space in typography. When rendered, a whitespace character does not correspond to a visible mark, but typically does occupy an area on a page. For example, the common whitespace symbol U+0020 SPACE represents a blank space punctuation character in text, used as a word divider in Western scripts.
Sa is one of the Japanese kana, which each represent one mora. Both represent. The shapes of these kana originate from 左 and 散, respectively.
ゑ in hiragana, or ヱ in katakana, is a nearly obsolete Japanese kana. The combination of an W-column kana letter with "ゑ゙" in hiragana was also introduced to represent [ve] in the 19th century and 20th century.
Unicode equivalence is the specification by the Unicode character encoding standard that some sequences of code points represent essentially the same character. This feature was introduced in the standard to allow compatibility with preexisting standard character sets, which often included similar or identical characters.
Bopomofo (Chinese: 注音符號; pinyin: zhùyīnfúhào; Wade–Giles: chu⁴yin¹fu²hao⁴, or Mandarin Phonetic Symbols, also named Zhuyin, is a major Chinese transliteration system for Mandarin Chinese and other related languages and dialects that is nowadays most commonly used in Taiwanese Mandarin. It is also used to transcribe other varieties of Chinese, particularly other varieties of Mandarin Chinese dialects, as well as Taiwanese Hokkien. Consisting of 37 characters and four tone marks, it transcribes all possible sounds in Mandarin.
Zawgyi font is a predominant typeface used for Burmese language text on websites. It is also known as Zawgyi-One or zawgyi1 font although updated versions of this font were not named Zawgyi-two. Prior to 2019, it was the most popular font on Burmese websites.
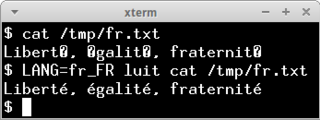
luit is a utility program used to translate the character set of a computer program so that its output can be displayed correctly on a terminal emulator that uses a different character set. Whereas iconv converts the character set of strings or text files at rest, luit converts the input and output of programs running interactively.
References
- ↑ Utterstroem, Jonas; Arrouye, Yves (2005). "uconv(1)". Linux man page. Retrieved 9 September 2018.
- ↑ Ruby bindings
| | This computer-library-related article is a stub. You can help Wikipedia by expanding it. |